 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up Music Information Retrieval Training with Semi-Supervised Learning
Oct 02, 2023In the era of data-driven Music Information Retrieval (MIR), the scarcity of labeled data has been one of the major concerns to the success of an MIR task. In this work, we leverage the semi-supervised teacher-student training approach to improve MIR tasks. For training, we scale up the unlabeled music data to 240k hours, which is much larger than any public MIR datasets. We iteratively create and refine the pseudo-labels in the noisy teacher-student training process. Knowledge expansion is also explored to iteratively scale up the model sizes from as small as less than 3M to almost 100M parameters. We study the performance correlation between data size and model size in the experiments. By scaling up both model size and training data, our models achieve state-of-the-art results on several MIR tasks compared to models that are either trained in a supervised manner or based on a self-supervised pretrained model. To our knowledge, this is the first attempt to study the effects of scaling up both model and training data for a variety of MIR tasks.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Text Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023


Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
Improving Fast-slow Encoder based Transducer with Streaming Deliberation
Dec 15, 2022This paper introduces a fast-slow encoder based transducer with streaming deliberation for end-to-end automatic speech recognition. We aim to improve the recognition accuracy of the fast-slow encoder based transducer while keeping its latency low by integrating a streaming deliberation model. Specifically, the deliberation model leverages partial hypotheses from the streaming fast encoder and implicitly learns to correct recognition errors. We modify the parallel beam search algorithm for fast-slow encoder based transducer to be efficient and compatible with the deliberation model. In addition, the deliberation model is designed to process streaming data. To further improve the deliberation performance, a simple text augmentation approach is explored. We also compare LSTM and Conformer models for encoding partial hypotheses. Experiments on Librispeech and in-house data show relative WER reductions (WERRs) from 3% to 5% with a slight increase in model size and negligible extra token emission latency compared with fast-slow encoder based transducer. Compared with vanilla neural transducers, the proposed deliberation model together with fast-slow encoder based transducer obtains relative 10-11% WERRs on Librispeech and around relative 6% WERR on in-house data with smaller emission delays.
Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities
Nov 10, 2022



End-to-end multilingual ASR has become more appealing because of several reasons such as simplifying the training and deployment process and positive performance transfer from high-resource to low-resource languages. However, scaling up the number of languages, total hours, and number of unique tokens is not a trivial task. This paper explores large-scale multilingual ASR models on 70 languages. We inspect two architectures: (1) Shared embedding and output and (2) Multiple embedding and output model. In the shared model experiments, we show the importance of tokenization strategy across different languages. Later, we use our optimal tokenization strategy to train multiple embedding and output model to further improve our result. Our multilingual ASR achieves 13.9%-15.6% average WER relative improvement compared to monolingual models. We show that our multilingual ASR generalizes well on an unseen dataset and domain, achieving 9.5% and 7.5% WER on Multilingual Librispeech (MLS) with zero-shot and finetuning, respectively.
Factorized Blank Thresholding for Improved Runtime Efficiency of Neural Transducers
Nov 02, 2022We show how factoring the RNN-T's output distribution can significantly reduce the computation cost and power consumption for on-device ASR inference with no loss in accuracy. With the rise in popularity of neural-transducer type models like the RNN-T for on-device ASR, optimizing RNN-T's runtime efficiency is of great interest. While previous work has primarily focused on the optimization of RNN-T's acoustic encoder and predictor, this paper focuses the attention on the joiner. We show that despite being only a small part of RNN-T, the joiner has a large impact on the overall model's runtime efficiency. We propose to factorize the joiner into blank and non-blank portions for the purpose of skipping the more expensive non-blank computation when the blank probability exceeds a certain threshold. Since the blank probability can be computed very efficiently and the RNN-T output is dominated by blanks, our proposed method leads to a 26-30% decoding speed-up and 43-53% reduction in on-device power consumption, all the while incurring no accuracy degradation and being relatively simple to implement.
Joint Audio/Text Training for Transformer Rescorer of Streaming Speech Recognition
Oct 31, 2022



Recently, there has been an increasing interest in two-pass streaming end-to-end speech recognition (ASR) that incorporates a 2nd-pass rescoring model on top of the conventional 1st-pass streaming ASR model to improve recognition accuracy while keeping latency low. One of the latest 2nd-pass rescoring model, Transformer Rescorer, takes the n-best initial outputs and audio embeddings from the 1st-pass model, and then choose the best output by re-scoring the n-best initial outputs. However, training this Transformer Rescorer requires expensive paired audio-text training data because the model uses audio embeddings as input. In this work, we present our Joint Audio/Text training method for Transformer Rescorer, to leverage unpaired text-only data which is relatively cheaper than paired audio-text data. We evaluate Transformer Rescorer with our Joint Audio/Text training on Librispeech dataset as well as our large-scale in-house dataset and show that our training method can improve word error rate (WER) significantly compared to standard Transformer Rescorer without requiring any extra model parameters or latency.
Multimodality Multi-Lead ECG Arrhythmia Classification using Self-Supervised Learning
Sep 30, 2022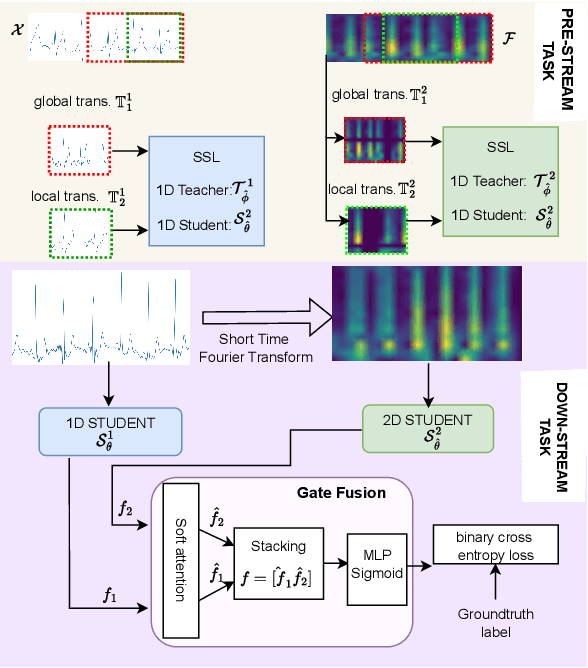
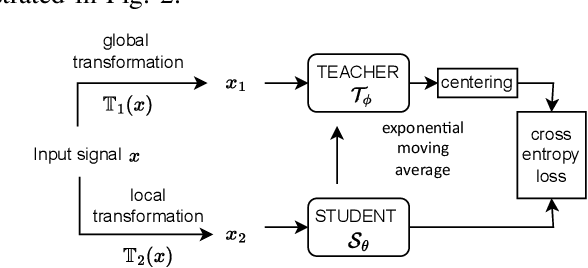
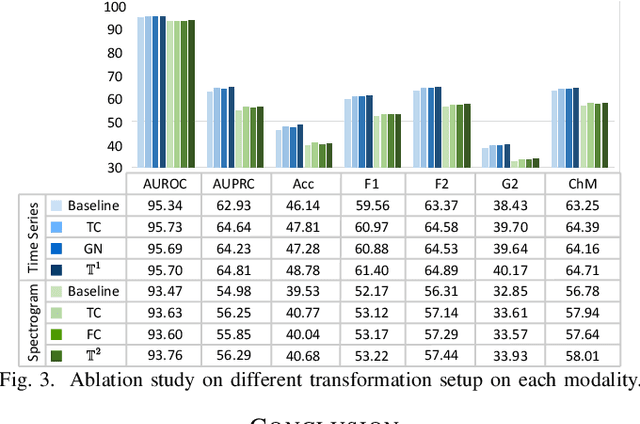
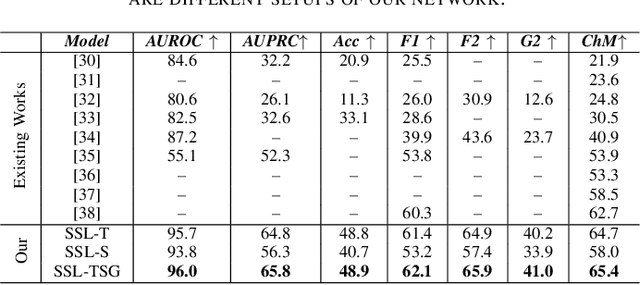
Electrocardiogram (ECG) signal is one of the most effective sources of information mainly employed for the diagnosis and prediction of cardiovascular diseases (CVDs) connected with the abnormalities in heart rhythm. Clearly, single modality ECG (i.e. time series) cannot convey its complete characteristics, thus, exploiting both time and time-frequency modalities in the form of time-series data and spectrogram is needed. Leveraging the cutting-edge self-supervised learning (SSL) technique on unlabeled data, we propose SSL-based multimodality ECG classification. Our proposed network follows SSL learning paradigm and consists of two modules corresponding to pre-stream task, and down-stream task, respectively. In the SSL-pre-stream task, we utilize self-knowledge distillation (KD) techniques with no labeled data, on various transformations and in both time and frequency domains. In the down-stream task, which is trained on labeled data, we propose a gate fusion mechanism to fuse information from multimodality.To evaluate the effectiveness of our approach, ten-fold cross validation on the 12-lead PhysioNet 2020 dataset has been conducted.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022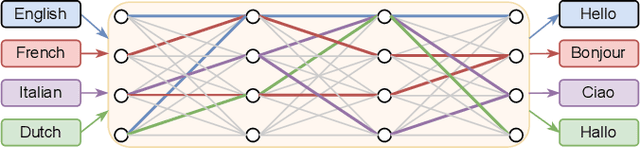
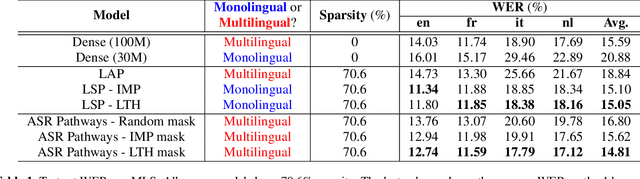
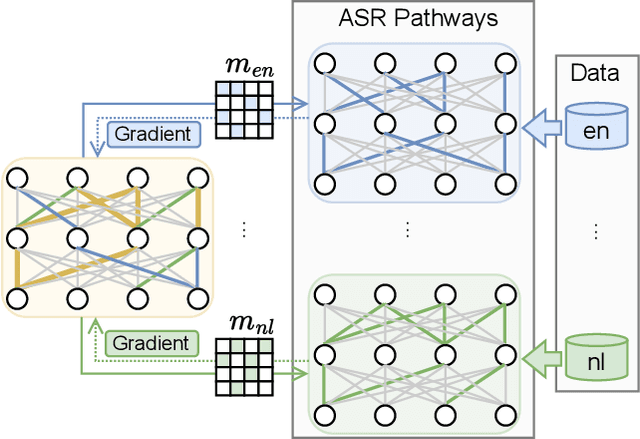
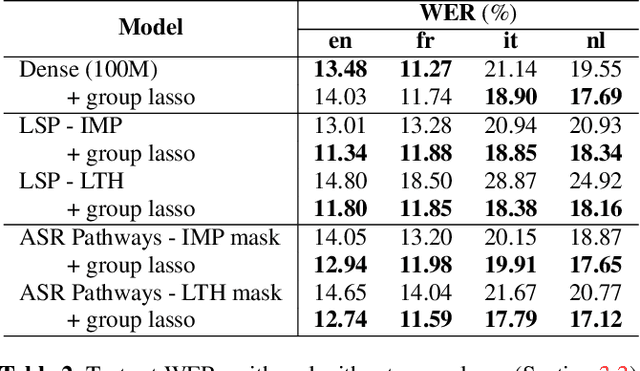
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.
An Investigation of Monotonic Transducers for Large-Scale Automatic Speech Recognition
Apr 19, 2022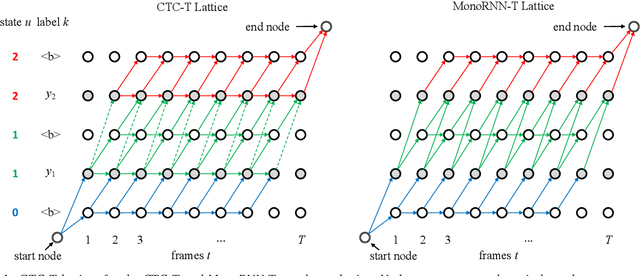
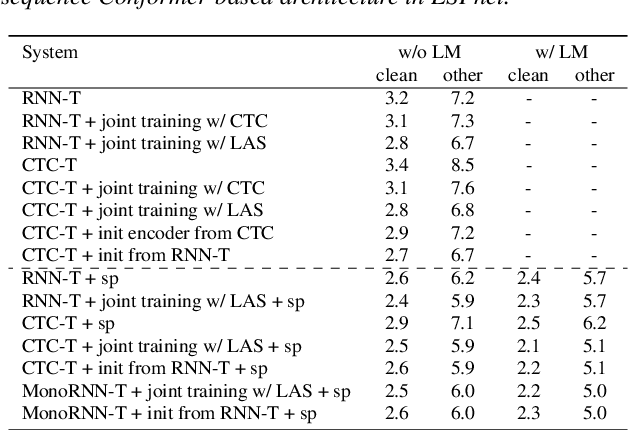
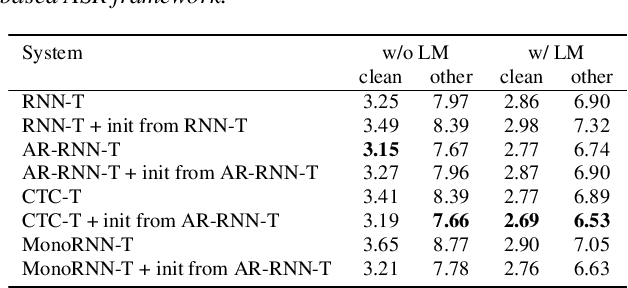
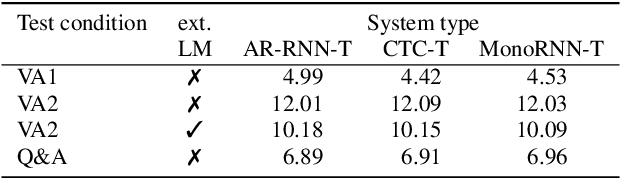
The two most popular loss functions for streaming end-to-end automatic speech recognition (ASR) are the RNN-Transducer (RNN-T) and the connectionist temporal classification (CTC) objectives. Both perform an alignment-free training by marginalizing over all possible alignments, but use different transition rules. Between these two loss types we can classify the monotonic RNN-T (MonoRNN-T) and the recently proposed CTC-like Transducer (CTC-T), which both can be realized using the graph temporal classification-transducer (GTC-T) loss function. Monotonic transducers have a few advantages. First, RNN-T can suffer from runaway hallucination, where a model keeps emitting non-blank symbols without advancing in time, often in an infinite loop. Secondly, monotonic transducers consume exactly one model score per time step and are therefore more compatible and unifiable with traditional FST-based hybrid ASR decoders. However, the MonoRNN-T so far has been found to have worse accuracy than RNN-T. It does not have to be that way, though: By regularizing the training - via joint LAS training or parameter initialization from RNN-T - both MonoRNN-T and CTC-T perform as well - or better - than RNN-T. This is demonstrated for LibriSpeech and for a large-scale in-house data set.