 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Framework for Fair Consensus Clustering in Streams
Feb 12, 2026Consensus clustering seeks to combine multiple clusterings of the same dataset, potentially derived by considering various non-sensitive attributes by different agents in a multi-agent environment, into a single partitioning that best reflects the overall structure of the underlying dataset. Recent work by Chakraborty et al, introduced a fair variant under proportionate fairness and obtained a constant-factor approximation by naively selecting the best closest fair input clustering; however, their offline approach requires storing all input clusterings, which is prohibitively expensive for most large-scale applications. In this paper, we initiate the study of fair consensus clustering in the streaming model, where input clusterings arrive sequentially and memory is limited. We design the first constant-factor algorithm that processes the stream while storing only a logarithmic number of inputs. En route, we introduce a new generic algorithmic framework that integrates closest fair clustering with cluster fitting, yielding improved approximation guarantees not only in the streaming setting but also when revisited offline. Furthermore, the framework is fairness-agnostic: it applies to any fairness definition for which an approximately close fair clustering can be computed efficiently. Finally, we extend our methods to the more general k-median consensus clustering problem.
Generalizing Fair Clustering to Multiple Groups: Algorithms and Applications
Nov 14, 2025Clustering is a fundamental task in machine learning and data analysis, but it frequently fails to provide fair representation for various marginalized communities defined by multiple protected attributes -- a shortcoming often caused by biases in the training data. As a result, there is a growing need to enhance the fairness of clustering outcomes, ideally by making minimal modifications, possibly as a post-processing step after conventional clustering. Recently, Chakraborty et al. [COLT'25] initiated the study of \emph{closest fair clustering}, though in a restricted scenario where data points belong to only two groups. In practice, however, data points are typically characterized by many groups, reflecting diverse protected attributes such as age, ethnicity, gender, etc. In this work, we generalize the study of the \emph{closest fair clustering} problem to settings with an arbitrary number (more than two) of groups. We begin by showing that the problem is NP-hard even when all groups are of equal size -- a stark contrast with the two-group case, for which an exact algorithm exists. Next, we propose near-linear time approximation algorithms that efficiently handle arbitrary-sized multiple groups, thereby answering an open question posed by Chakraborty et al. [COLT'25]. Leveraging our closest fair clustering algorithms, we further achieve improved approximation guarantees for the \emph{fair correlation clustering} problem, advancing the state-of-the-art results established by Ahmadian et al. [AISTATS'20] and Ahmadi et al. [2020]. Additionally, we are the first to provide approximation algorithms for the \emph{fair consensus clustering} problem involving multiple (more than two) groups, thus addressing another open direction highlighted by Chakraborty et al. [COLT'25].
Towards Fair Representation: Clustering and Consensus
Jun 11, 2025Consensus clustering, a fundamental task in machine learning and data analysis, aims to aggregate multiple input clusterings of a dataset, potentially based on different non-sensitive attributes, into a single clustering that best represents the collective structure of the data. In this work, we study this fundamental problem through the lens of fair clustering, as introduced by Chierichetti et al. [NeurIPS'17], which incorporates the disparate impact doctrine to ensure proportional representation of each protected group in the dataset within every cluster. Our objective is to find a consensus clustering that is not only representative but also fair with respect to specific protected attributes. To the best of our knowledge, we are the first to address this problem and provide a constant-factor approximation. As part of our investigation, we examine how to minimally modify an existing clustering to enforce fairness -- an essential postprocessing step in many clustering applications that require fair representation. We develop an optimal algorithm for datasets with equal group representation and near-linear time constant factor approximation algorithms for more general scenarios with different proportions of two group sizes. We complement our approximation result by showing that the problem is NP-hard for two unequal-sized groups. Given the fundamental nature of this problem, we believe our results on Closest Fair Clustering could have broader implications for other clustering problems, particularly those for which no prior approximation guarantees exist for their fair variants.
Prototypical Human-AI Collaboration Behaviors from LLM-Assisted Writing in the Wild
May 21, 2025As large language models (LLMs) are used in complex writing workflows, users engage in multi-turn interactions to steer generations to better fit their needs. Rather than passively accepting output, users actively refine, explore, and co-construct text. We conduct a large-scale analysis of this collaborative behavior for users engaged in writing tasks in the wild with two popular AI assistants, Bing Copilot and WildChat. Our analysis goes beyond simple task classification or satisfaction estimation common in prior work and instead characterizes how users interact with LLMs through the course of a session. We identify prototypical behaviors in how users interact with LLMs in prompts following their original request. We refer to these as Prototypical Human-AI Collaboration Behaviors (PATHs) and find that a small group of PATHs explain a majority of the variation seen in user-LLM interaction. These PATHs span users revising intents, exploring texts, posing questions, adjusting style or injecting new content. Next, we find statistically significant correlations between specific writing intents and PATHs, revealing how users' intents shape their collaboration behaviors. We conclude by discussing the implications of our findings on LLM alignment.
LawFlow : Collecting and Simulating Lawyers' Thought Processes
Apr 26, 2025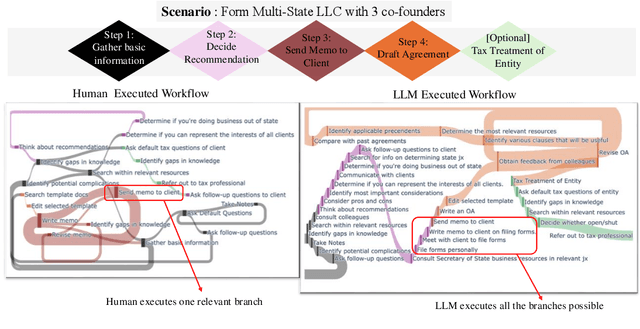
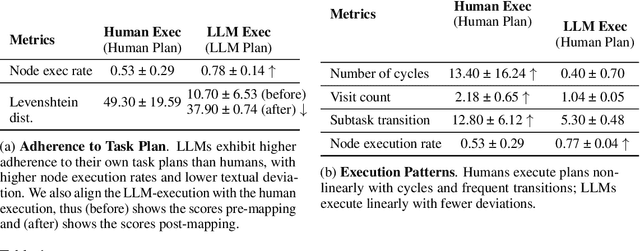
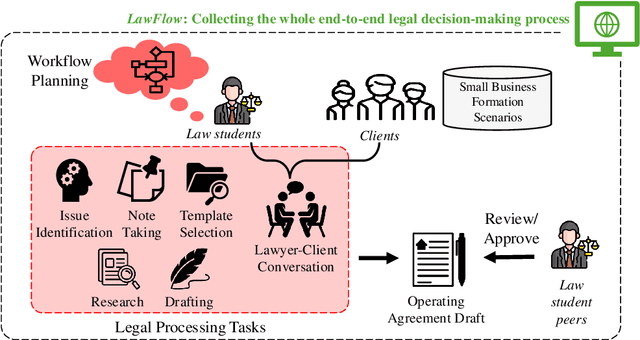
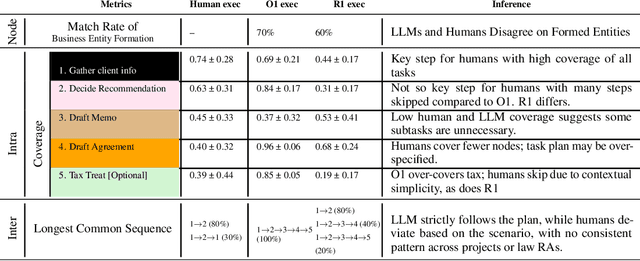
Legal practitioners, particularly those early in their careers, face complex, high-stakes tasks that require adaptive, context-sensitive reasoning. While AI holds promise in supporting legal work, current datasets and models are narrowly focused on isolated subtasks and fail to capture the end-to-end decision-making required in real-world practice. To address this gap, we introduce LawFlow, a dataset of complete end-to-end legal workflows collected from trained law students, grounded in real-world business entity formation scenarios. Unlike prior datasets focused on input-output pairs or linear chains of thought, LawFlow captures dynamic, modular, and iterative reasoning processes that reflect the ambiguity, revision, and client-adaptive strategies of legal practice. Using LawFlow, we compare human and LLM-generated workflows, revealing systematic differences in structure, reasoning flexibility, and plan execution. Human workflows tend to be modular and adaptive, while LLM workflows are more sequential, exhaustive, and less sensitive to downstream implications. Our findings also suggest that legal professionals prefer AI to carry out supportive roles, such as brainstorming, identifying blind spots, and surfacing alternatives, rather than executing complex workflows end-to-end. Building on these findings, we propose a set of design suggestions, rooted in empirical observations, that align AI assistance with human goals of clarity, completeness, creativity, and efficiency, through hybrid planning, adaptive execution, and decision-point support. Our results highlight both the current limitations of LLMs in supporting complex legal workflows and opportunities for developing more collaborative, reasoning-aware legal AI systems. All data and code are available on our project page (https://minnesotanlp.github.io/LawFlow-website/).
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.
Which Modality should I use -- Text, Motif, or Image? : Understanding Graphs with Large Language Models
Nov 16, 2023



Large language models (LLMs) are revolutionizing various fields by leveraging large text corpora for context-aware intelligence. Due to the context size, however, encoding an entire graph with LLMs is fundamentally limited. This paper explores how to better integrate graph data with LLMs and presents a novel approach using various encoding modalities (e.g., text, image, and motif) and approximation of global connectivity of a graph using different prompting methods to enhance LLMs' effectiveness in handling complex graph structures. The study also introduces GraphTMI, a new benchmark for evaluating LLMs in graph structure analysis, focusing on factors such as homophily, motif presence, and graph difficulty. Key findings reveal that image modality, supported by advanced vision-language models like GPT-4V, is more effective than text in managing token limits while retaining critical information. The research also examines the influence of different factors on each encoding modality's performance. This study highlights the current limitations and charts future directions for LLMs in graph understanding and reasoning tasks.
Balancing Effect of Training Dataset Distribution of Multiple Styles for Multi-Style Text Transfer
May 24, 2023Text style transfer is an exciting task within the field of natural language generation that is often plagued by the need for high-quality paired datasets. Furthermore, training a model for multi-attribute text style transfer requires datasets with sufficient support across all combinations of the considered stylistic attributes, adding to the challenges of training a style transfer model. This paper explores the impact of training data input diversity on the quality of the generated text from the multi-style transfer model. We construct a pseudo-parallel dataset by devising heuristics to adjust the style distribution in the training samples. We balance our training dataset using marginal and joint distributions to train our style transfer models. We observe that a balanced dataset produces more effective control effects over multiple styles than an imbalanced or skewed one. Through quantitative analysis, we explore the impact of multiple style distributions in training data on style-transferred output. These findings will better inform the design of style-transfer datasets.