 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawFlow : Collecting and Simulating Lawyers' Thought Processes
Apr 26, 2025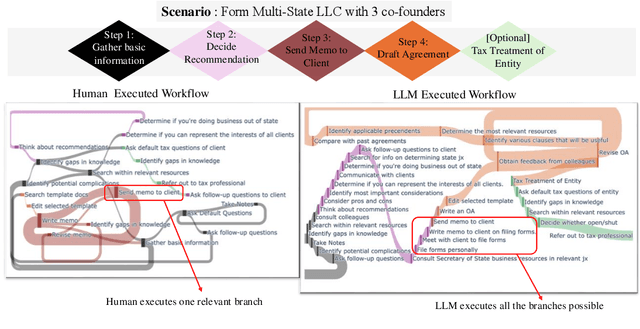
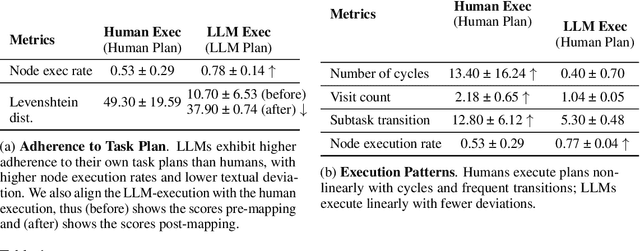
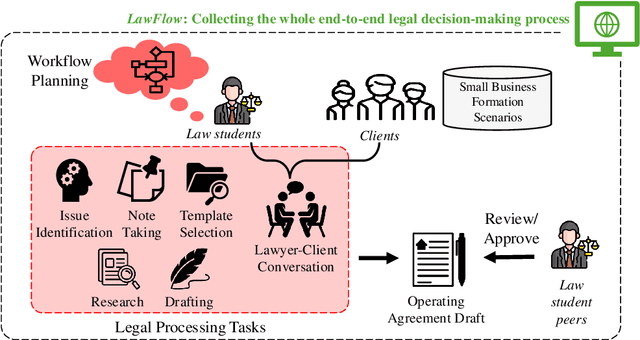
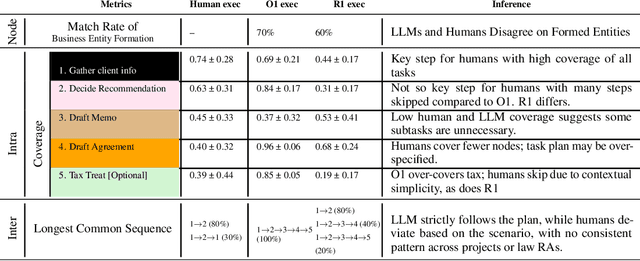
Legal practitioners, particularly those early in their careers, face complex, high-stakes tasks that require adaptive, context-sensitive reasoning. While AI holds promise in supporting legal work, current datasets and models are narrowly focused on isolated subtasks and fail to capture the end-to-end decision-making required in real-world practice. To address this gap, we introduce LawFlow, a dataset of complete end-to-end legal workflows collected from trained law students, grounded in real-world business entity formation scenarios. Unlike prior datasets focused on input-output pairs or linear chains of thought, LawFlow captures dynamic, modular, and iterative reasoning processes that reflect the ambiguity, revision, and client-adaptive strategies of legal practice. Using LawFlow, we compare human and LLM-generated workflows, revealing systematic differences in structure, reasoning flexibility, and plan execution. Human workflows tend to be modular and adaptive, while LLM workflows are more sequential, exhaustive, and less sensitive to downstream implications. Our findings also suggest that legal professionals prefer AI to carry out supportive roles, such as brainstorming, identifying blind spots, and surfacing alternatives, rather than executing complex workflows end-to-end. Building on these findings, we propose a set of design suggestions, rooted in empirical observations, that align AI assistance with human goals of clarity, completeness, creativity, and efficiency, through hybrid planning, adaptive execution, and decision-point support. Our results highlight both the current limitations of LLMs in supporting complex legal workflows and opportunities for developing more collaborative, reasoning-aware legal AI systems. All data and code are available on our project page (https://minnesotanlp.github.io/LawFlow-website/).
SelectLLM: Can LLMs Select Important Instructions to Annotate?
Jan 29, 2024



Training large language models (LLMs) with a large and diverse instruction dataset aligns the models to comprehend and follow human instructions. Recent works have shown that using a small set of high-quality instructions can outperform using large yet more noisy ones. Because instructions are unlabeled and their responses are natural text, traditional active learning schemes with the model's confidence cannot be directly applied to the selection of unlabeled instructions. In this work, we propose a novel method for instruction selection, called SelectLLM, that leverages LLMs for the selection of high-quality instructions. Our high-level idea is to use LLMs to estimate the usefulness and impactfulness of each instruction without the corresponding labels (i.e., responses), via prompting. SelectLLM involves two steps: dividing the unlabelled instructions using a clustering algorithm (e.g., CoreSet) to multiple clusters, and then prompting LLMs to choose high-quality instructions within each cluster. SelectLLM showed comparable or slightly better performance on the popular instruction benchmarks, compared to the recent state-of-the-art selection methods. All code and data are publicly available (https://github.com/minnesotanlp/select-llm).