 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawFlow : Collecting and Simulating Lawyers' Thought Processes
Apr 26, 2025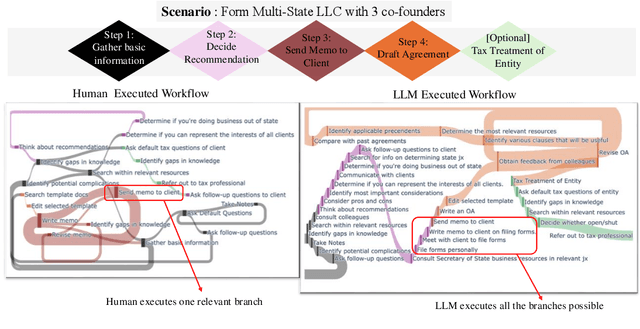
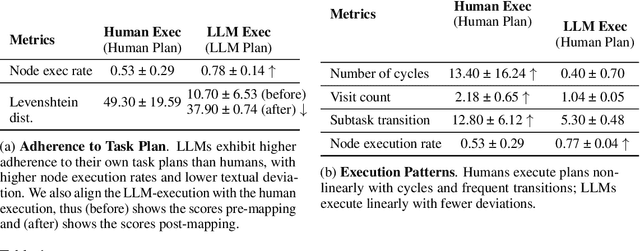
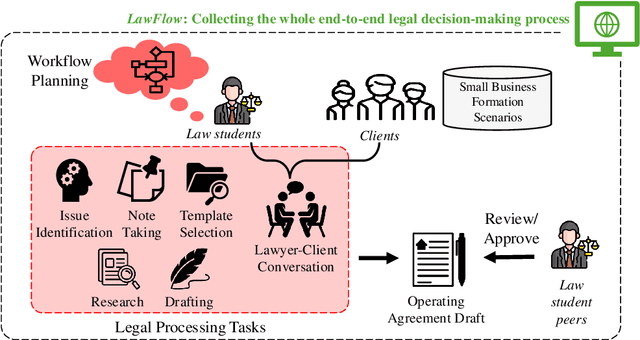
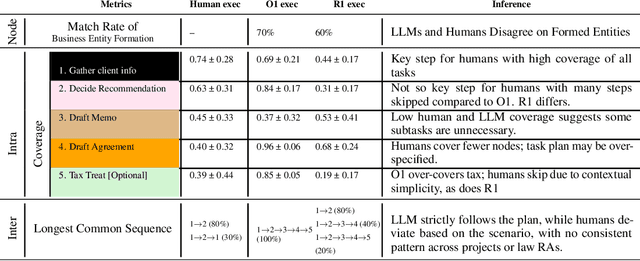
Legal practitioners, particularly those early in their careers, face complex, high-stakes tasks that require adaptive, context-sensitive reasoning. While AI holds promise in supporting legal work, current datasets and models are narrowly focused on isolated subtasks and fail to capture the end-to-end decision-making required in real-world practice. To address this gap, we introduce LawFlow, a dataset of complete end-to-end legal workflows collected from trained law students, grounded in real-world business entity formation scenarios. Unlike prior datasets focused on input-output pairs or linear chains of thought, LawFlow captures dynamic, modular, and iterative reasoning processes that reflect the ambiguity, revision, and client-adaptive strategies of legal practice. Using LawFlow, we compare human and LLM-generated workflows, revealing systematic differences in structure, reasoning flexibility, and plan execution. Human workflows tend to be modular and adaptive, while LLM workflows are more sequential, exhaustive, and less sensitive to downstream implications. Our findings also suggest that legal professionals prefer AI to carry out supportive roles, such as brainstorming, identifying blind spots, and surfacing alternatives, rather than executing complex workflows end-to-end. Building on these findings, we propose a set of design suggestions, rooted in empirical observations, that align AI assistance with human goals of clarity, completeness, creativity, and efficiency, through hybrid planning, adaptive execution, and decision-point support. Our results highlight both the current limitations of LLMs in supporting complex legal workflows and opportunities for developing more collaborative, reasoning-aware legal AI systems. All data and code are available on our project page (https://minnesotanlp.github.io/LawFlow-website/).
Under the Surface: Tracking the Artifactuality of LLM-Generated Data
Jan 30, 2024



This work delves into the expanding role of large language models (LLMs) in generating artificial data. LLMs are increasingly employed to create a variety of outputs, including annotations, preferences, instruction prompts, simulated dialogues, and free text. As these forms of LLM-generated data often intersect in their application, they exert mutual influence on each other and raise significant concerns about the quality and diversity of the artificial data incorporated into training cycles, leading to an artificial data ecosystem. To the best of our knowledge, this is the first study to aggregate various types of LLM-generated text data, from more tightly constrained data like "task labels" to more lightly constrained "free-form text". We then stress test the quality and implications of LLM-generated artificial data, comparing it with human data across various existing benchmarks. Despite artificial data's capability to match human performance, this paper reveals significant hidden disparities, especially in complex tasks where LLMs often miss the nuanced understanding of intrinsic human-generated content. This study critically examines diverse LLM-generated data and emphasizes the need for ethical practices in data creation and when using LLMs. It highlights the LLMs' shortcomings in replicating human traits and behaviors, underscoring the importance of addressing biases and artifacts produced in LLM-generated content for future research and development. All data and code are available on our project page.