 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Noise Can Make an EEG-Based Brain-Computer Interface Speller Output Anything
Mar 04, 2020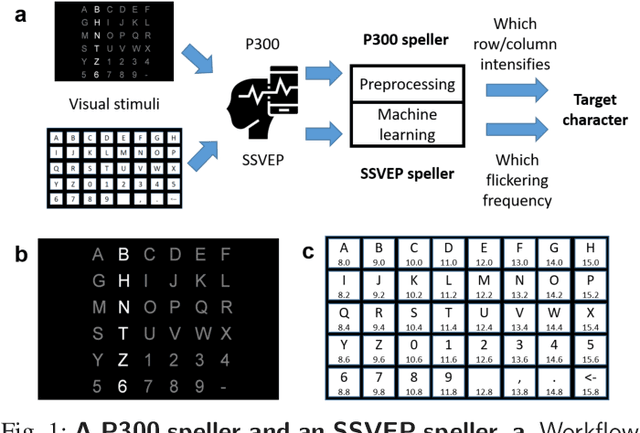
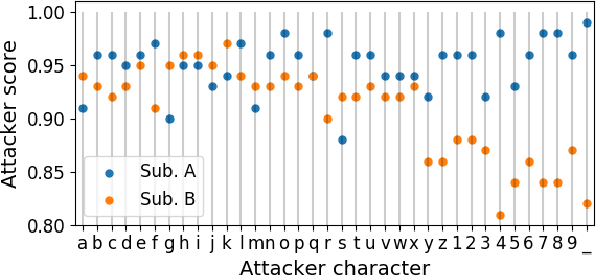
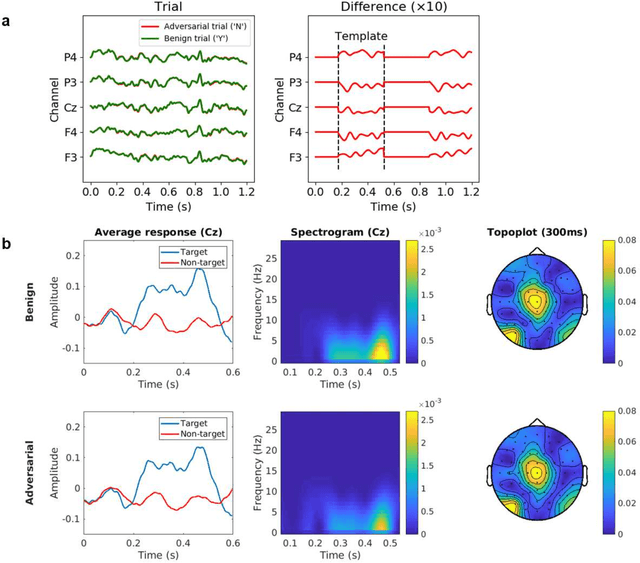
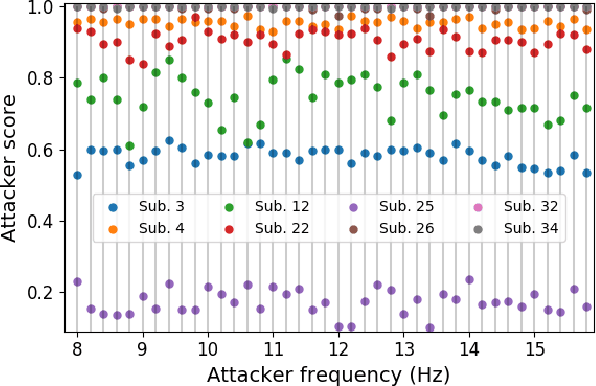
An electroencephalogram (EEG) based brain-computer interface (BCI) speller allows a user to input text to a computer by thought. It is particularly useful to severely disabled individuals, e.g., amyotrophic lateral sclerosis patients, who have no other effective means of communication with another person or a computer. Most studies so far focused on making EEG-based BCI spellers faster and more reliable; however, few have considered their security. Here we show that P300 and steady-state visual evoked potential BCI spellers are very vulnerable, i.e., they can be severely attacked by adversarial perturbations, which are too tiny to be noticed when added to EEG signals, but can mislead the spellers to spell anything the attacker wants. The consequence could range from merely user frustration to severe misdiagnosis in clinical applications. We hope our research can attract more attention to the security of EEG-based BCI spellers, and more broadly, EEG-based BCIs, which has received little attention before.
MBGD-RDA Training and Rule Pruning for Concise TSK Fuzzy Regression Models
Mar 03, 2020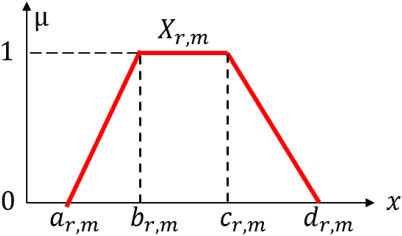
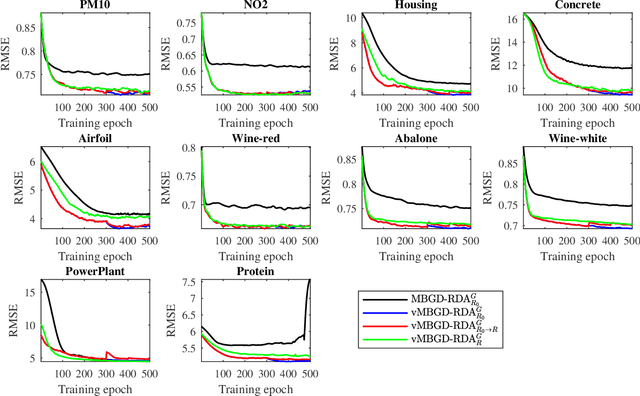
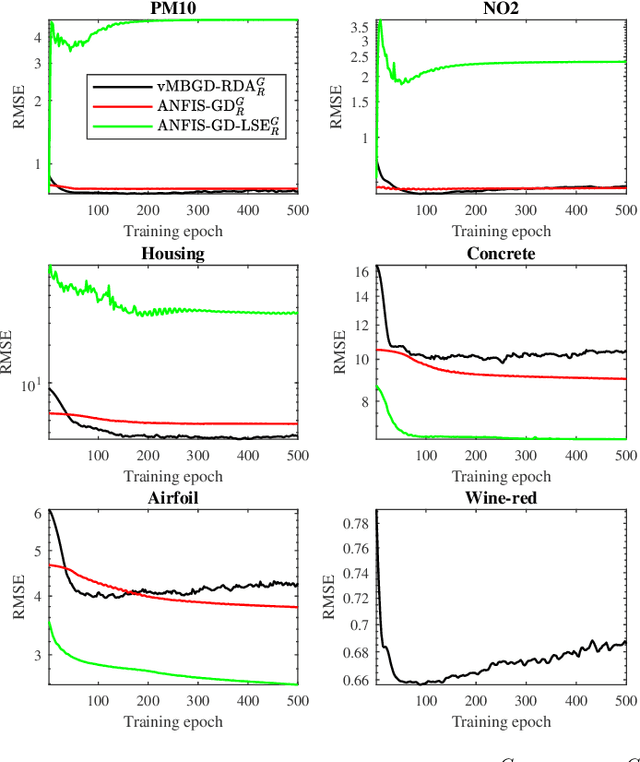
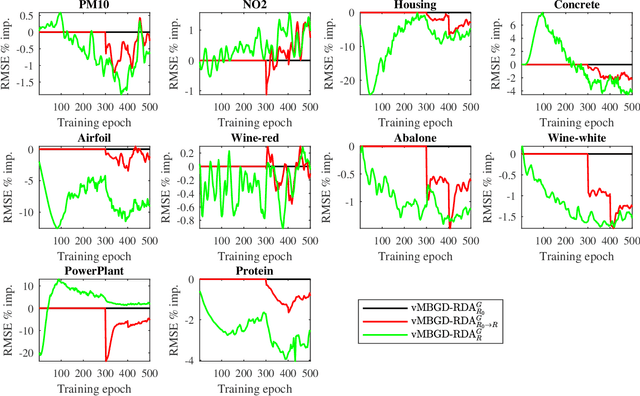
To effectively train Takagi-Sugeno-Kang (TSK) fuzzy systems for regression problems, a Mini-Batch Gradient Descent with Regularization, DropRule, and AdaBound (MBGD-RDA) algorithm was recently proposed. It has demonstrated superior performances; however, there are also some limitations, e.g., it does not allow the user to specify the number of rules directly, and only Gaussian MFs can be used. This paper proposes two variants of MBGD-RDA to remedy these limitations, and show that they outperform the original MBGD-RDA and the classical ANFIS algorithms with the same number of rules. Furthermore, we also propose a rule pruning algorithm for TSK fuzzy systems, which can reduce the number of rules without significantly sacrificing the regression performance. Experiments showed that the rules obtained from pruning are generally better than training them from scratch directly, especially when Gaussian MFs are used.
Supervised Enhanced Soft Subspace Clustering (SESSC) for TSK Fuzzy Classifiers
Feb 27, 2020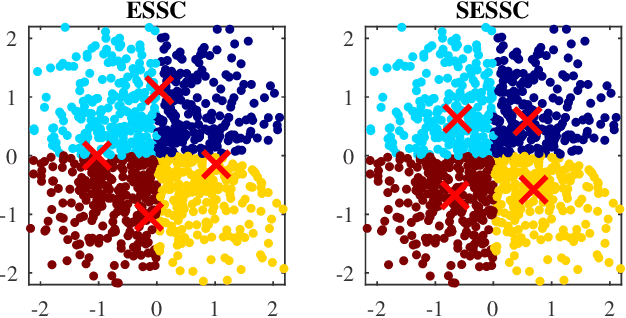
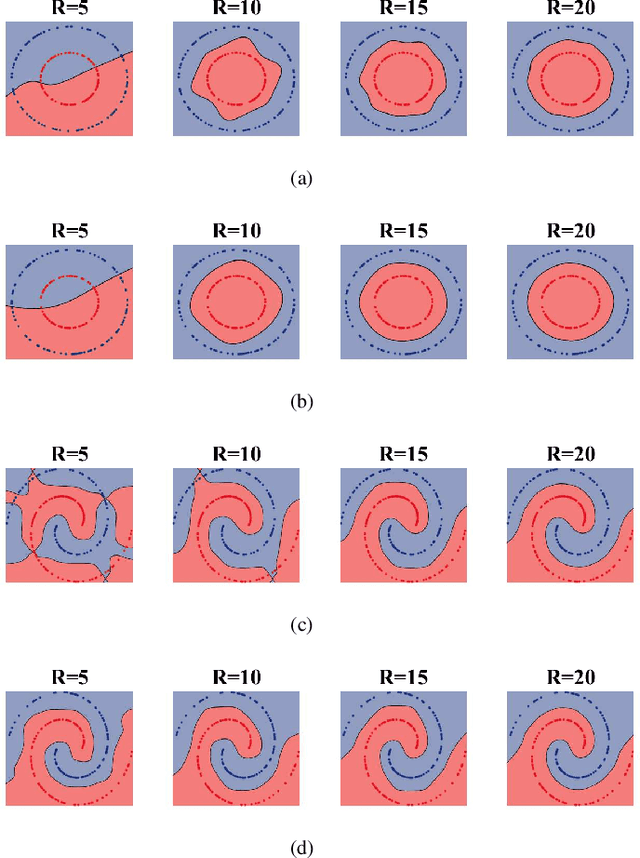
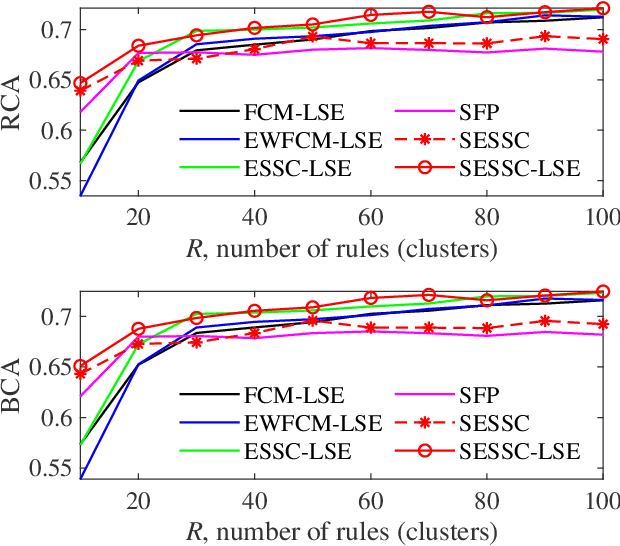
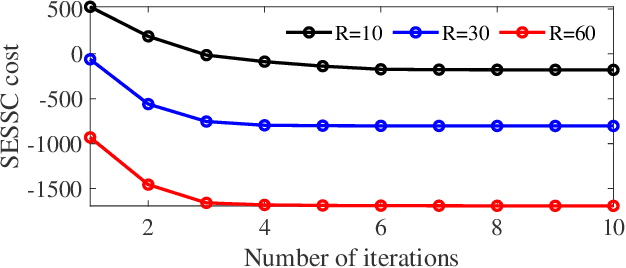
Fuzzy c-means based clustering algorithms are frequently used for Takagi-Sugeno-Kang (TSK) fuzzy classifier antecedent parameter estimation. One rule is initialized from each cluster. However, most of these clustering algorithms are unsupervised, which waste valuable label information in the training data. This paper proposes a supervised enhanced soft subspace clustering (SESSC) algorithm, which considers simultaneously the within-cluster compactness, between-cluster separation, and label information in clustering. It can effectively deal with high-dimensional data, be used as a classifier alone, or be integrated into a TSK fuzzy classifier to further improve its performance. Experiments on nine UCI datasets from various application domains demonstrated that SESSC based initialization outperformed other clustering approaches, especially when the number of rules is small.
EEG-based Brain-Computer Interfaces : A Survey of Recent Studies on Signal Sensing Technologies and Computational Intelligence Approaches and their Applications
Jan 28, 2020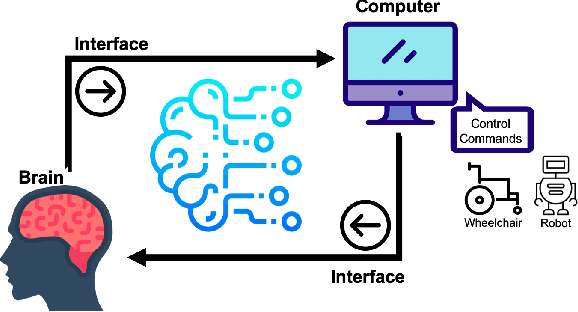
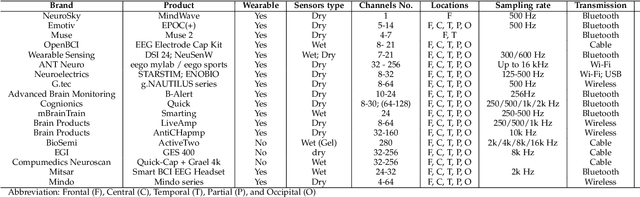
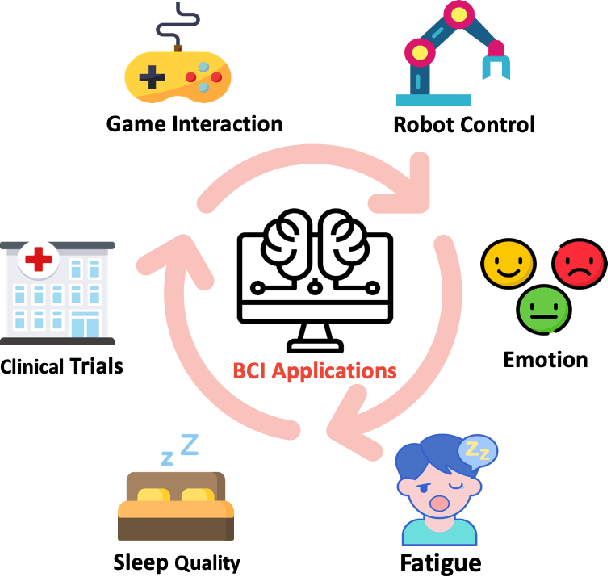
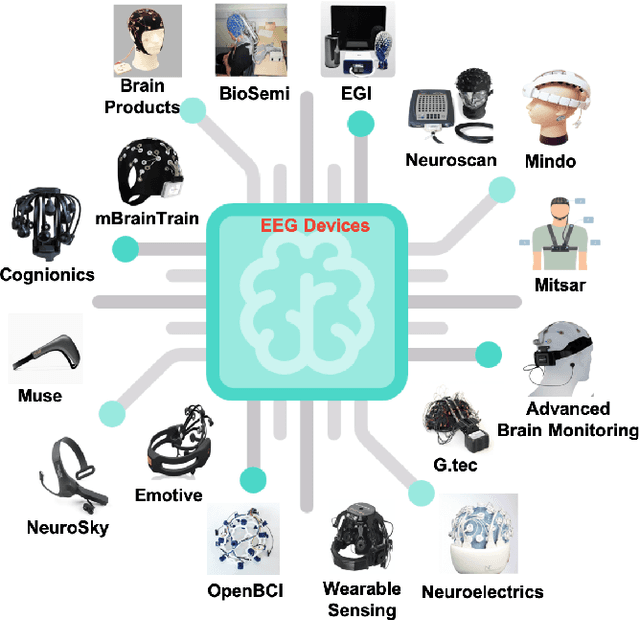
Brain-Computer Interface (BCI) is a powerful communication tool between users and systems, which enhances the capability of the human brain in communicating and interacting with the environment directly. Advances in neuroscience and computer science in the past decades have led to exciting developments in BCI, thereby making BCI a top interdisciplinary research area in computational neuroscience and intelligence. Recent technological advances such as wearable sensing devices, real-time data streaming, machine learning, and deep learning approaches have increased interest in electroencephalographic (EEG) based BCI for translational and healthcare applications. Many people benefit from EEG-based BCIs, which facilitate continuous monitoring of fluctuations in cognitive states under monotonous tasks in the workplace or at home. In this study, we survey the recent literature of EEG signal sensing technologies and computational intelligence approaches in BCI applications, compensated for the gaps in the systematic summary of the past five years (2015-2019). In specific, we first review the current status of BCI and its significant obstacles. Then, we present advanced signal sensing and enhancement technologies to collect and clean EEG signals, respectively. Furthermore, we demonstrate state-of-art computational intelligence techniques, including interpretable fuzzy models, transfer learning, deep learning, and combinations, to monitor, maintain, or track human cognitive states and operating performance in prevalent applications. Finally, we deliver a couple of innovative BCI-inspired healthcare applications and discuss some future research directions in EEG-based BCIs.
Unsupervised Pool-Based Active Learning for Linear Regression
Jan 14, 2020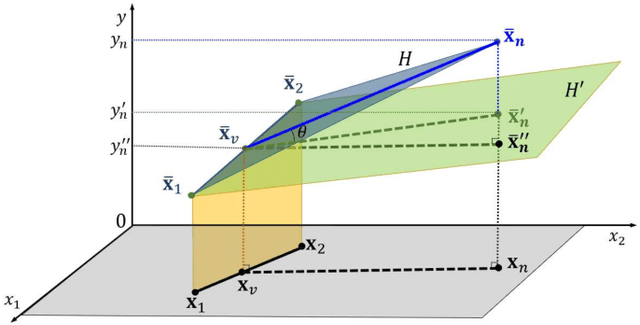
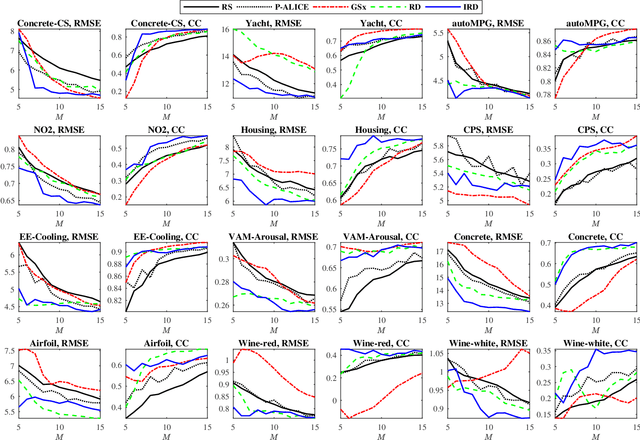
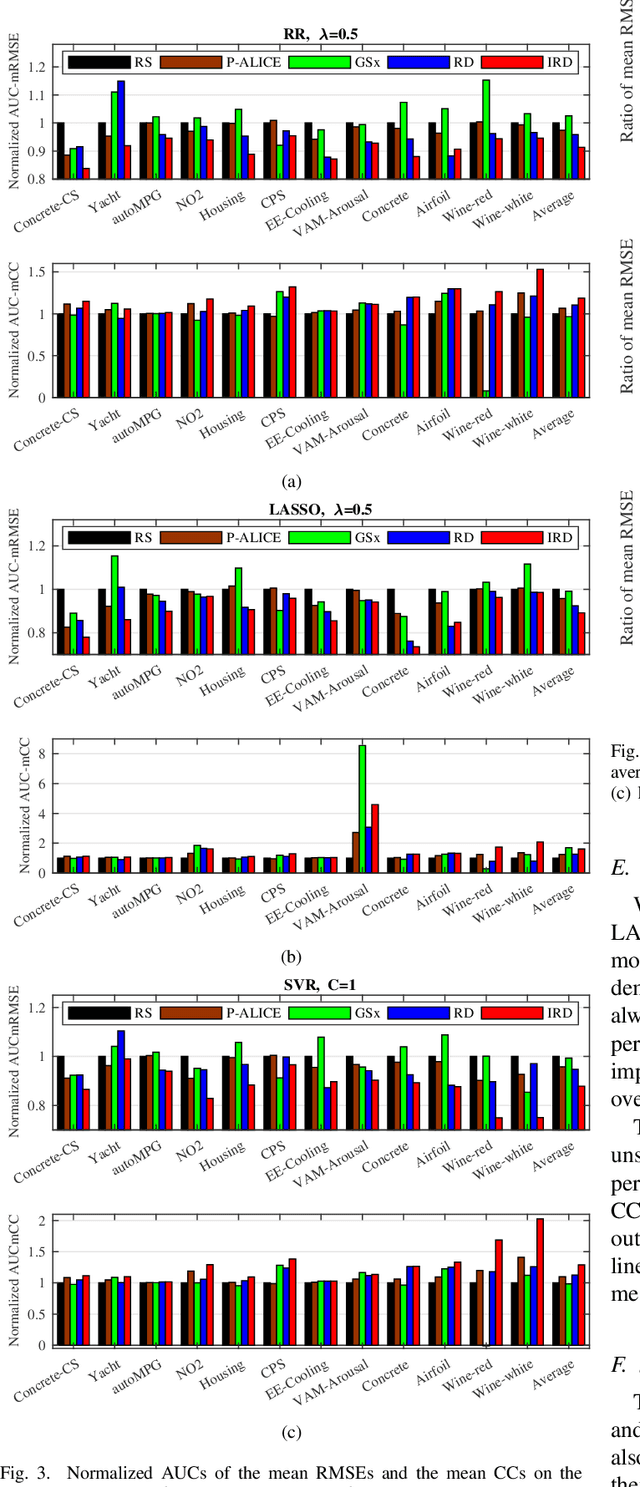
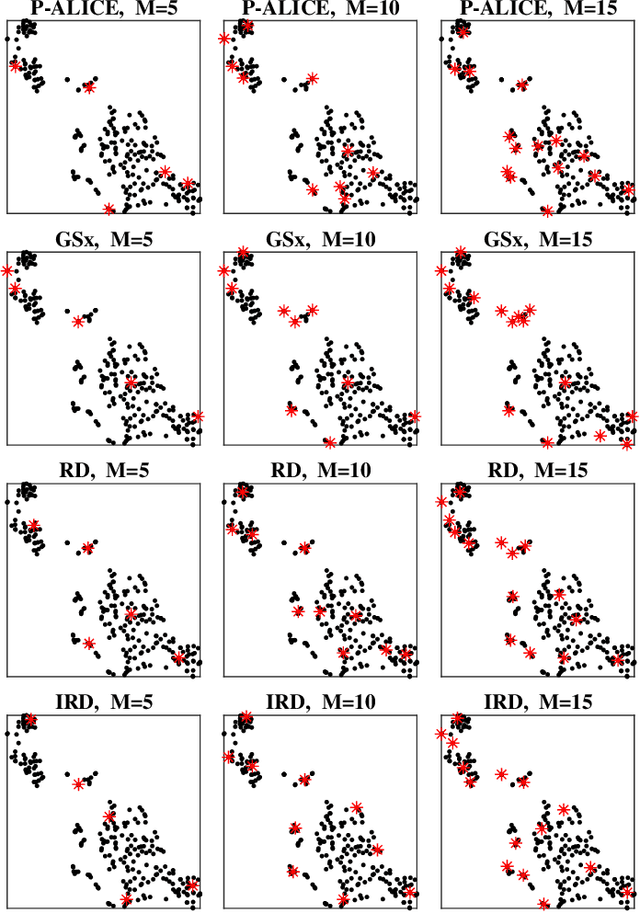
In many real-world machine learning applications, unlabeled data can be easily obtained, but it is very time-consuming and/or expensive to label them. So, it is desirable to be able to select the optimal samples to label, so that a good machine learning model can be trained from a minimum amount of labeled data. Active learning (AL) has been widely used for this purpose. However, most existing AL approaches are supervised: they train an initial model from a small amount of labeled samples, query new samples based on the model, and then update the model iteratively. Few of them have considered the completely unsupervised AL problem, i.e., starting from zero, how to optimally select the very first few samples to label, without knowing any label information at all. This problem is very challenging, as no label information can be utilized. This paper studies unsupervised pool-based AL for linear regression problems. We propose a novel AL approach that considers simultaneously the informativeness, representativeness, and diversity, three essential criteria in AL. Extensive experiments on 14 datasets from various application domains, using three different linear regression models (ridge regression, LASSO, and linear support vector regression), demonstrated the effectiveness of our proposed approach.
Discriminative Joint Probability Maximum Mean Discrepancy (DJP-MMD) for Domain Adaptation
Jan 14, 2020
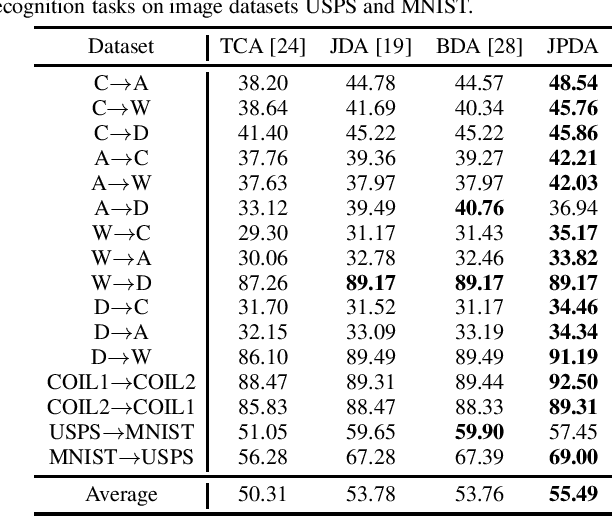
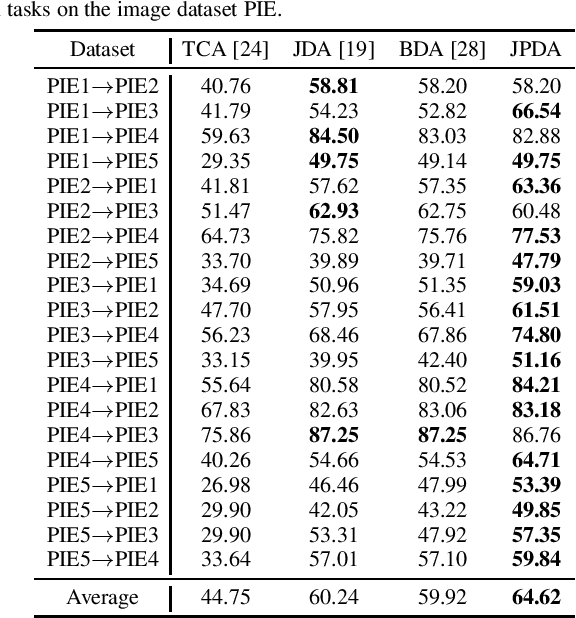
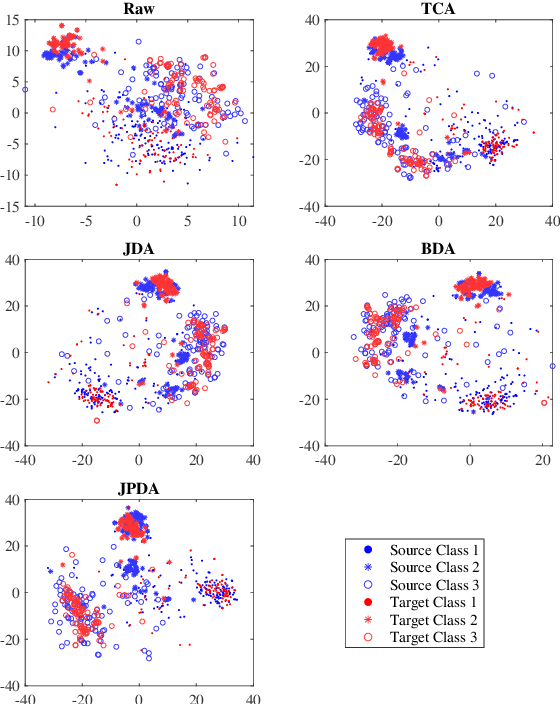
Maximum mean discrepancy (MMD) has been widely adopted in domain adaptation to measure the discrepancy between the source and target domain distributions. Many existing domain adaptation approaches are based on the joint MMD, which is computed as the (weighted) sum of the marginal distribution discrepancy and the conditional distribution discrepancy; however, a more natural metric may be their joint probability distribution discrepancy. Additionally, most metrics only aim to increase the transferability between domains, but ignores the discriminability between different classes, which may result in insufficient classification performance. To address these issues, discriminative joint probability MMD (DJP-MMD) is proposed in this paper to replace the frequently-used joint MMD in domain adaptation. It has two desirable properties: 1) it provides a new theoretical basis for computing the distribution discrepancy, which is simpler and more accurate; 2) it increases the transferability and discriminability simultaneously. We validate its performance by embedding it into a joint probability domain adaptation framework. Experiments on six image classification datasets demonstrated that the proposed DJP-MMD can outperform traditional MMDs.
Supervised Discriminative Sparse PCA with Adaptive Neighbors for Dimensionality Reduction
Jan 12, 2020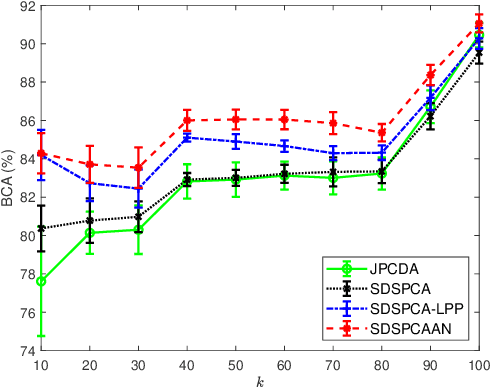
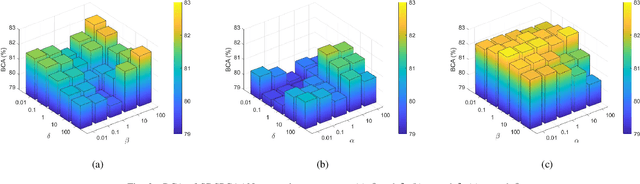
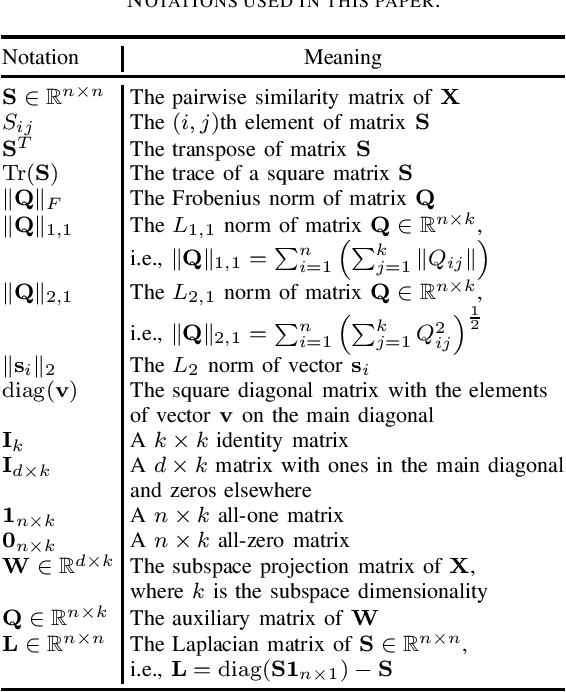
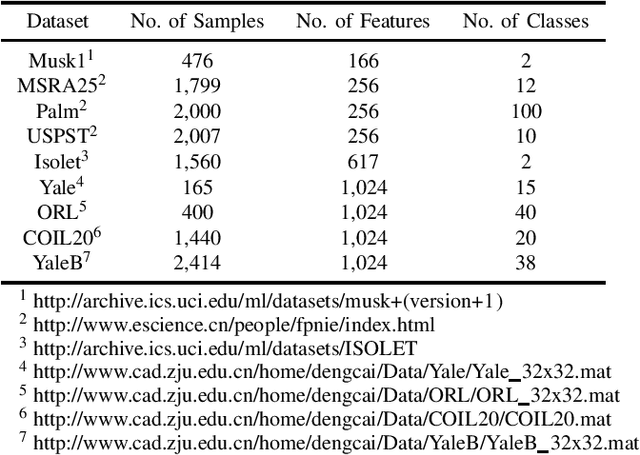
Dimensionality reduction is an important operation in information visualization, feature extraction, clustering, regression, and classification, especially for processing noisy high dimensional data. However, most existing approaches preserve either the global or the local structure of the data, but not both. Approaches that preserve only the global data structure, such as principal component analysis (PCA), are usually sensitive to outliers. Approaches that preserve only the local data structure, such as locality preserving projections, are usually unsupervised (and hence cannot use label information) and uses a fixed similarity graph. We propose a novel linear dimensionality reduction approach, supervised discriminative sparse PCA with adaptive neighbors (SDSPCAAN), to integrate neighborhood-free supervised discriminative sparse PCA and projected clustering with adaptive neighbors. As a result, both global and local data structures, as well as the label information, are used for better dimensionality reduction. Classification experiments on nine high-dimensional datasets validated the effectiveness and robustness of our proposed SDSPCAAN.
EEG-based Drowsiness Estimation for Driving Safety using Deep Q-Learning
Jan 08, 2020
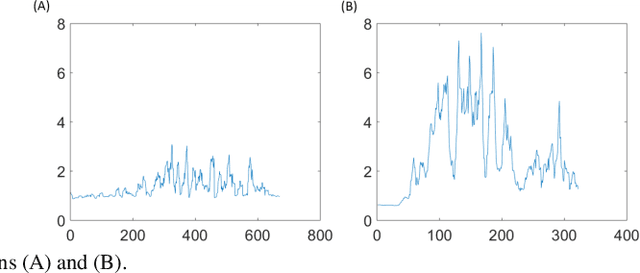
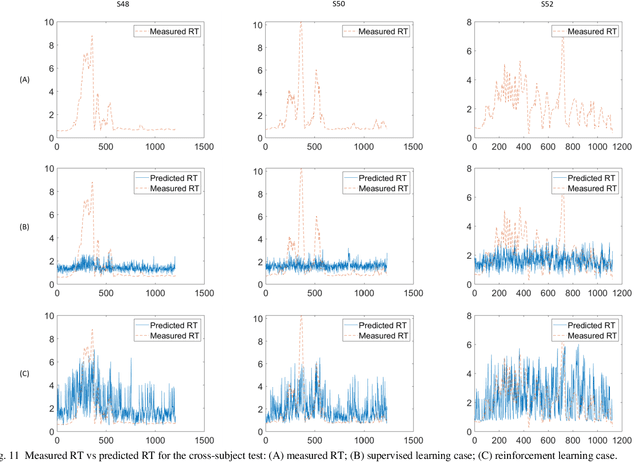
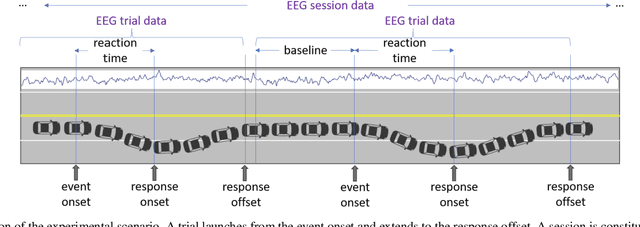
Fatigue is the most vital factor of road fatalities and one manifestation of fatigue during driving is drowsiness. In this paper, we propose using deep Q-learning to analyze an electroencephalogram (EEG) dataset captured during a simulated endurance driving test. By measuring the correlation between drowsiness and driving performance, this experiment represents an important brain-computer interface (BCI) paradigm especially from an application perspective. We adapt the terminologies in the driving test to fit the reinforcement learning framework, thus formulate the drowsiness estimation problem as an optimization of a Q-learning task. By referring to the latest deep Q-Learning technologies and attending to the characteristics of EEG data, we tailor a deep Q-network for action proposition that can indirectly estimate drowsiness. Our results show that the trained model can trace the variations of mind state in a satisfactory way against the testing EEG data, which demonstrates the feasibility and practicability of this new computation paradigm. We also show that our method outperforms the supervised learning counterpart and is superior for real applications. To the best of our knowledge, we are the first to introduce the deep reinforcement learning method to this BCI scenario, and our method can be potentially generalized to other BCI cases.
Empirical Studies on the Properties of Linear Regions in Deep Neural Networks
Jan 04, 2020
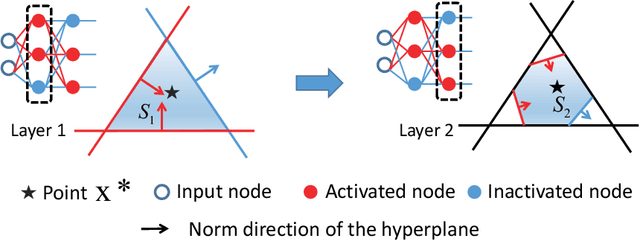
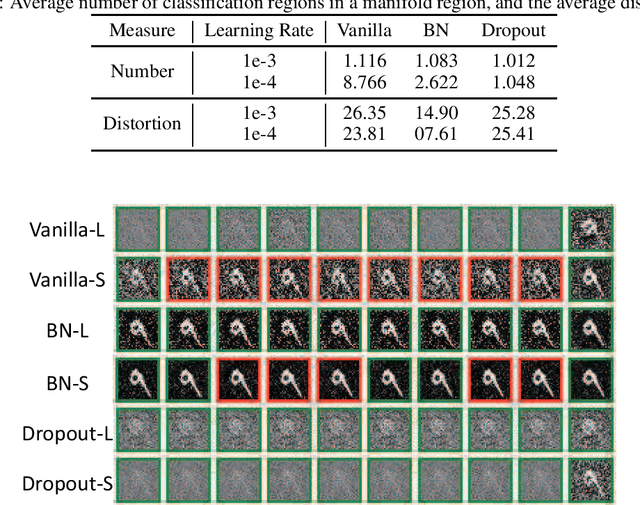
A deep neural network (DNN) with piecewise linear activations can partition the input space into numerous small linear regions, where different linear functions are fitted. It is believed that the number of these regions represents the expressivity of the DNN. This paper provides a novel and meticulous perspective to look into DNNs: Instead of just counting the number of the linear regions, we study their local properties, such as the inspheres, the directions of the corresponding hyperplanes, the decision boundaries, and the relevance of the surrounding regions. We empirically observed that different optimization techniques lead to completely different linear regions, even though they result in similar classification accuracies. We hope our study can inspire the design of novel optimization techniques, and help discover and analyze the behaviors of DNNs.
Different Set Domain Adaptation for Brain-Computer Interfaces: A Label Alignment Approach
Dec 29, 2019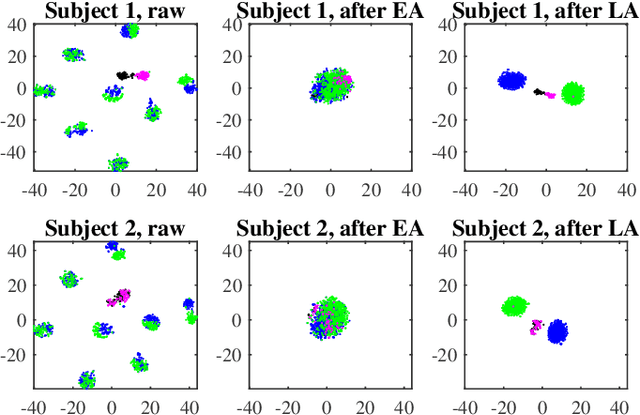
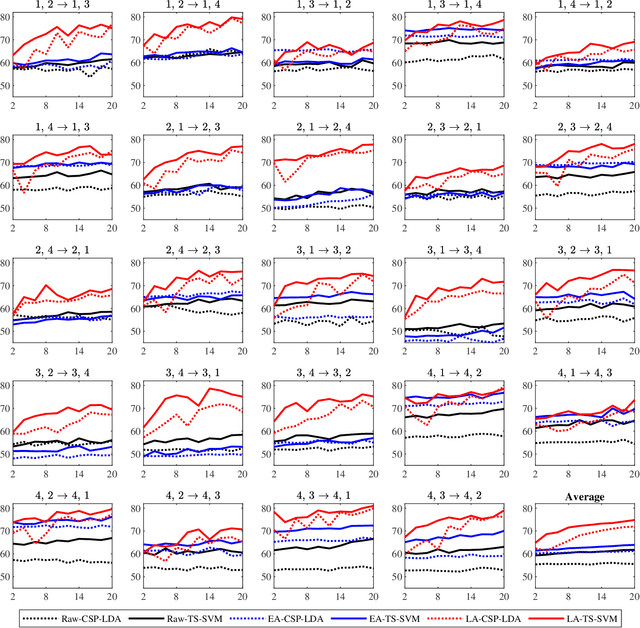
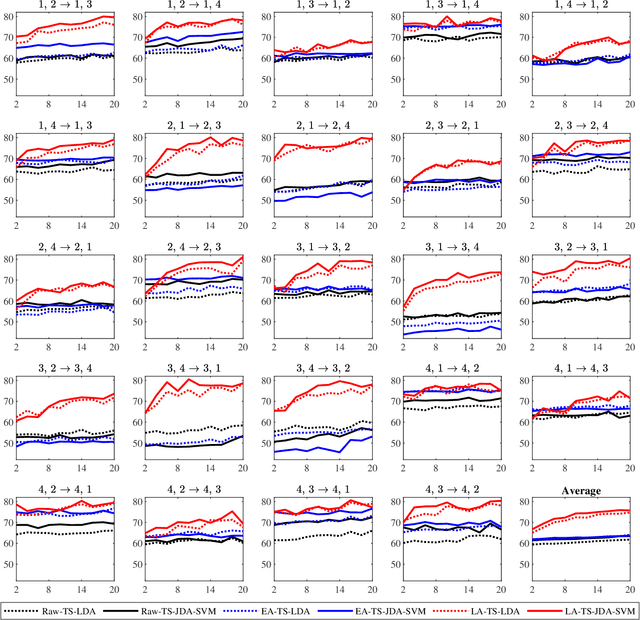
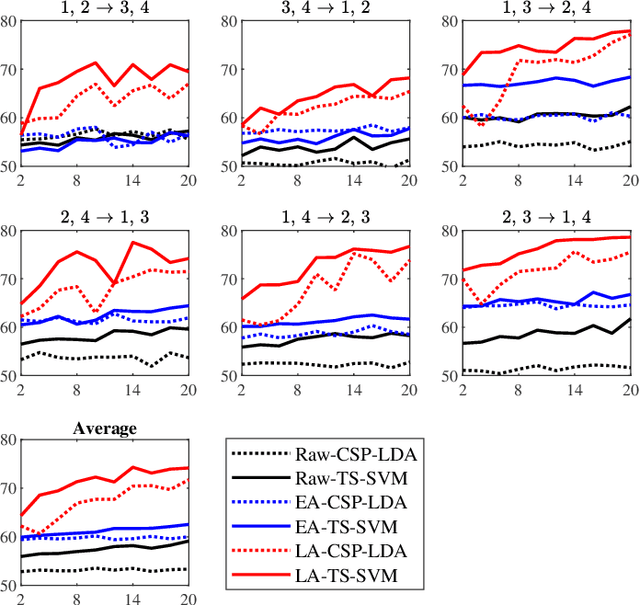
A brain-computer interface (BCI) system usually needs a long calibration session for each new subject/task to adjust its parameters, which impedes its transition from the laboratory to real-world applications. Domain adaptation, which leverages labeled data from auxiliary subjects/tasks (source domains), has demonstrated its effectiveness in reducing such calibration effort. Currently, most domain adaptation approaches require the source domains to have the same feature space and label space as the target domain, which limits their applications, as the auxiliary data may have different feature spaces and/or different label spaces. This paper considers different set domain adaptation for BCIs, i.e., the source and target domains have different label spaces. We introduce a practical setting of different label sets for BCIs, and propose a novel label alignment (LA) approach to align the source label space with the target label space. It has three desirable properties: 1) LA only needs as few as one labeled sample from each class of the target subject; 2) LA can be used as a preprocessing step before different feature extraction and classification algorithms; and, 3) LA can be integrated with other domain adaptation approaches to achieve even better performance. Experiments on two motor imagery datasets demonstrated the effectiveness of LA.