 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Concept-wise Temporal Convolutional Networks for Action Localization
Aug 26, 2019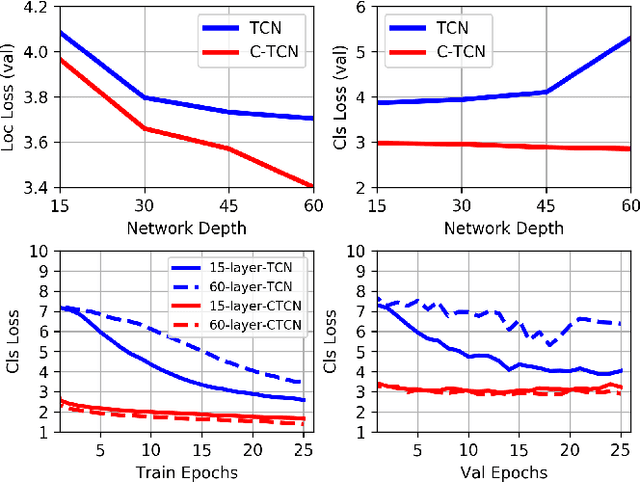
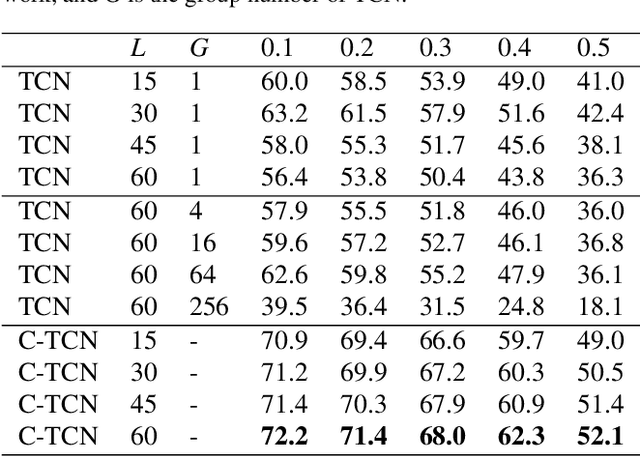
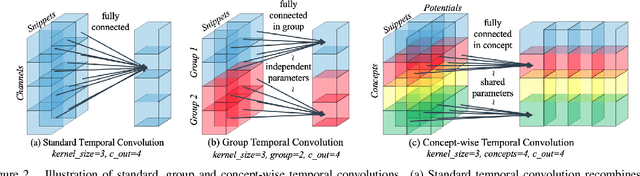
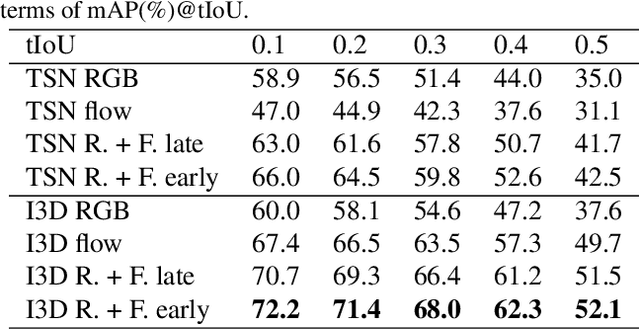
Existing action localization approaches adopt shallow temporal convolutional networks (\ie, TCN) on 1D feature map extracted from video frames. In this paper, we empirically find that stacking more conventional temporal convolution layers actually deteriorates action classification performance, possibly ascribing to that all channels of 1D feature map, which generally are highly abstract and can be regarded as latent concepts, are excessively recombined in temporal convolution. To address this issue, we introduce a novel concept-wise temporal convolution (CTC) layer as an alternative to conventional temporal convolution layer for training deeper action localization networks. Instead of recombining latent concepts, CTC layer deploys a number of temporal filters to each concept separately with shared filter parameters across concepts. Thus can capture common temporal patterns of different concepts and significantly enrich representation ability. Via stacking CTC layers, we proposed a deep concept-wise temporal convolutional network (C-TCN), which boosts the state-of-the-art action localization performance on THUMOS'14 from 42.8 to 52.1 in terms of mAP(\%), achieving a relative improvement of 21.7\%. Favorable result is also obtained on ActivityNet.
Multi-Agent Reinforcement Learning Based Frame Sampling for Effective Untrimmed Video Recognition
Aug 02, 2019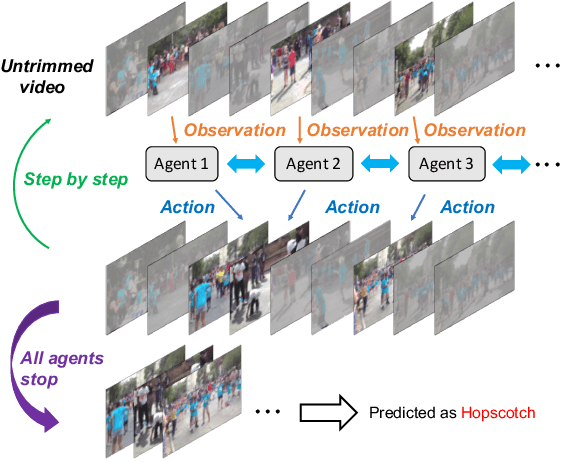
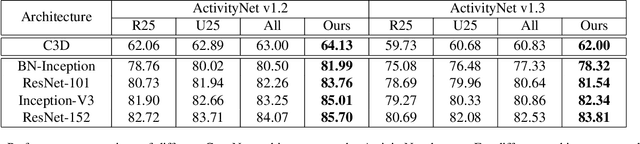
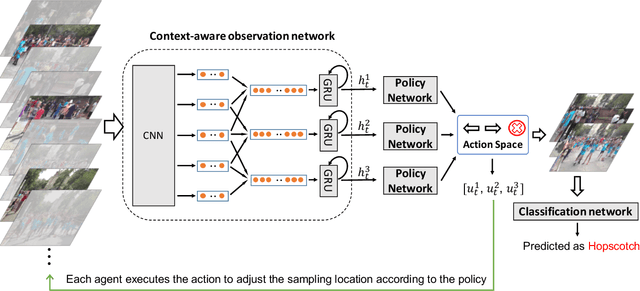

Video Recognition has drawn great research interest and great progress has been made. A suitable frame sampling strategy can improve the accuracy and efficiency of recognition. However, mainstream solutions generally adopt hand-crafted frame sampling strategies for recognition. It could degrade the performance, especially in untrimmed videos, due to the variation of frame-level saliency. To this end, we concentrate on improving untrimmed video classification via developing a learning-based frame sampling strategy. We intuitively formulate the frame sampling procedure as multiple parallel Markov decision processes, each of which aims at picking out a frame/clip by gradually adjusting an initial sampling. Then we propose to solve the problems with multi-agent reinforcement learning (MARL). Our MARL framework is composed of a novel RNN-based context-aware observation network which jointly models context information among nearby agents and historical states of a specific agent, a policy network which generates the probability distribution over a predefined action space at each step and a classification network for reward calculation as well as final recognition. Extensive experimental results show that our MARL-based scheme remarkably outperforms hand-crafted strategies with various 2D and 3D baseline methods. Our single RGB model achieves a comparable performance of ActivityNet v1.3 champion submission with multi-modal multi-model fusion and new state-of-the-art results on YouTube Birds and YouTube Cars.
Adapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution
May 07, 2019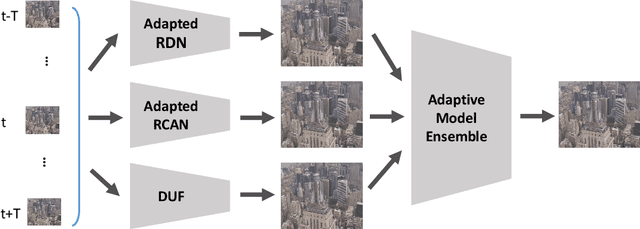
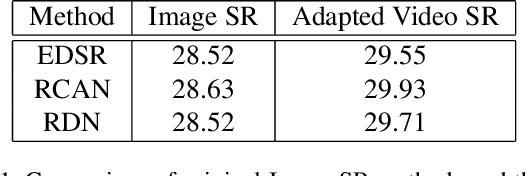
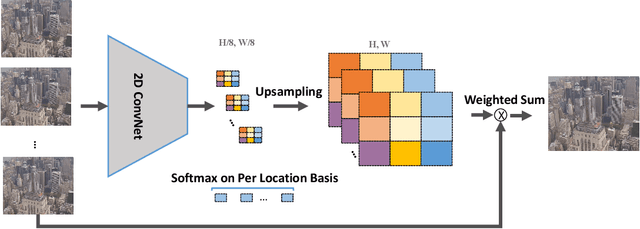
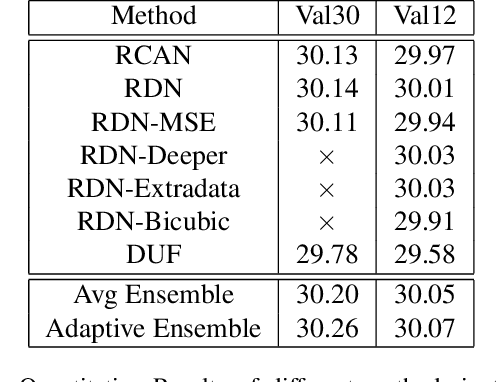
Recently, image super-resolution has been widely studied and achieved significant progress by leveraging the power of deep convolutional neural networks. However, there has been limited advancement in video super-resolution (VSR) due to the complex temporal patterns in videos. In this paper, we investigate how to adapt state-of-the-art methods of image super-resolution for video super-resolution. The proposed adapting method is straightforward. The information among successive frames is well exploited, while the overhead on the original image super-resolution method is negligible. Furthermore, we propose a learning-based method to ensemble the outputs from multiple super-resolution models. Our methods show superior performance and rank second in the NTIRE2019 Video Super-Resolution Challenge Track 1.
Read, Watch, and Move: Reinforcement Learning for Temporally Grounding Natural Language Descriptions in Videos
Jan 21, 2019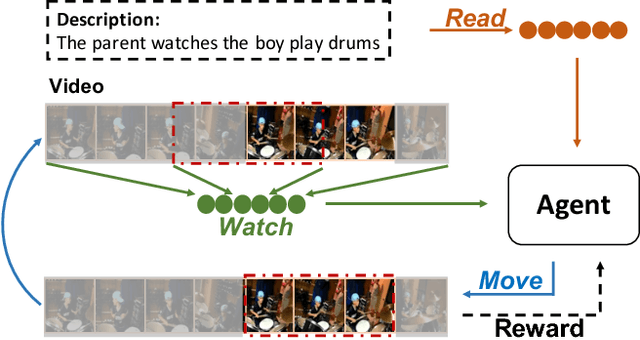
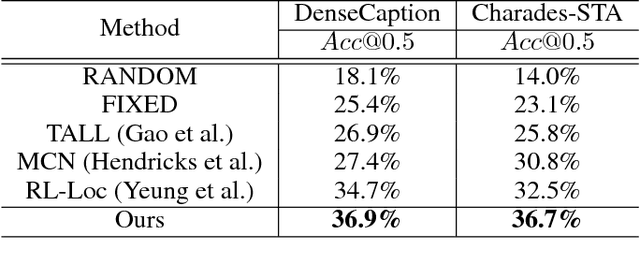
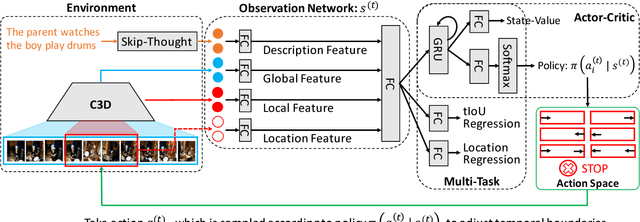
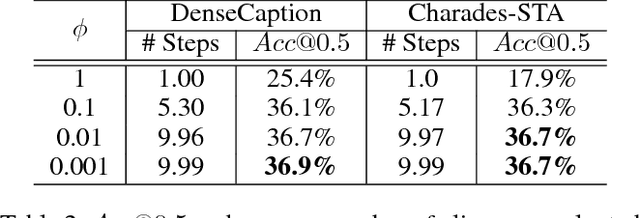
The task of video grounding, which temporally localizes a natural language description in a video, plays an important role in understanding videos. Existing studies have adopted strategies of sliding window over the entire video or exhaustively ranking all possible clip-sentence pairs in a pre-segmented video, which inevitably suffer from exhaustively enumerated candidates. To alleviate this problem, we formulate this task as a problem of sequential decision making by learning an agent which regulates the temporal grounding boundaries progressively based on its policy. Specifically, we propose a reinforcement learning based framework improved by multi-task learning and it shows steady performance gains by considering additional supervised boundary information during training. Our proposed framework achieves state-of-the-art performance on ActivityNet'18 DenseCaption dataset and Charades-STA dataset while observing only 10 or less clips per video.
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition
Nov 06, 2018
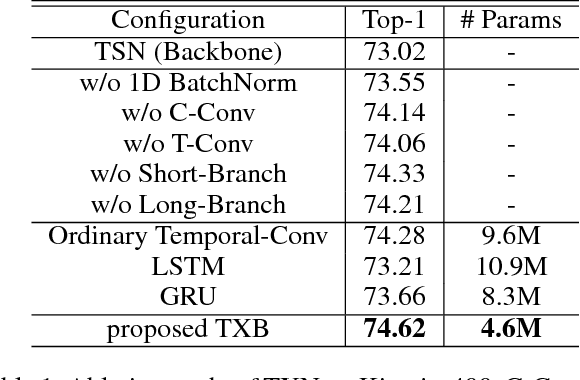
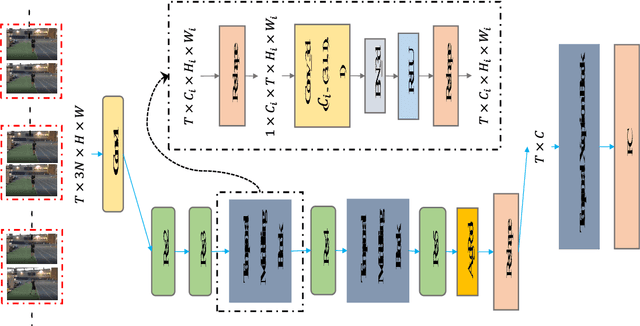
Despite the success of deep learning for static image understanding, it remains unclear what are the most effective network architectures for the spatial-temporal modeling in videos. In this paper, in contrast to the existing CNN+RNN or pure 3D convolution based approaches, we explore a novel spatial temporal network (StNet) architecture for both local and global spatial-temporal modeling in videos. Particularly, StNet stacks N successive video frames into a \emph{super-image} which has 3N channels and applies 2D convolution on super-images to capture local spatial-temporal relationship. To model global spatial-temporal relationship, we apply temporal convolution on the local spatial-temporal feature maps. Specifically, a novel temporal Xception block is proposed in StNet. It employs a separate channel-wise and temporal-wise convolution over the feature sequence of video. Extensive experiments on the Kinetics dataset demonstrate that our framework outperforms several state-of-the-art approaches in action recognition and can strike a satisfying trade-off between recognition accuracy and model complexity. We further demonstrate the generalization performance of the leaned video representations on the UCF101 dataset.
Exploiting Spatial-Temporal Modelling and Multi-Modal Fusion for Human Action Recognition
Jun 27, 2018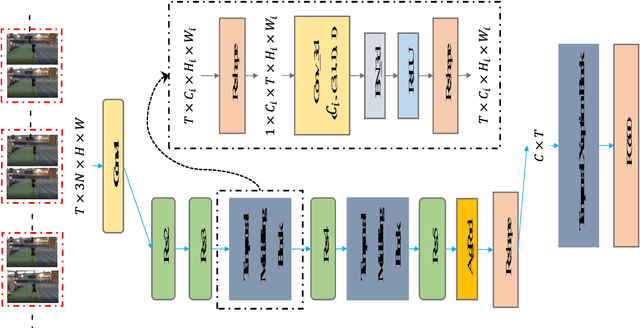

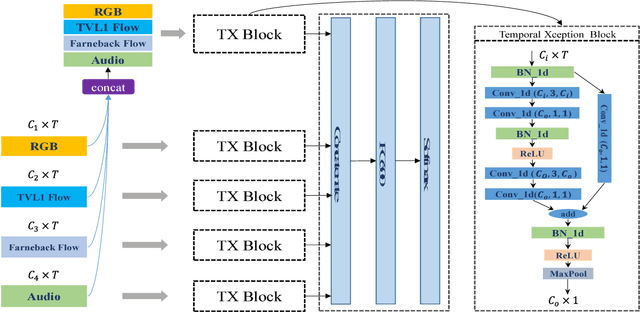

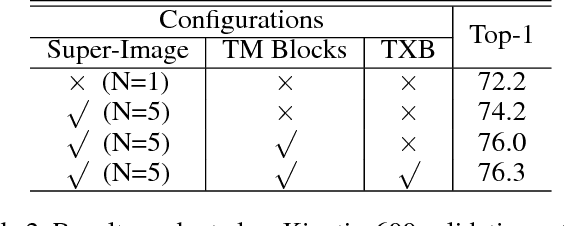
In this report, our approach to tackling the task of ActivityNet 2018 Kinetics-600 challenge is described in detail. Though spatial-temporal modelling methods, which adopt either such end-to-end framework as I3D \cite{i3d} or two-stage frameworks (i.e., CNN+RNN), have been proposed in existing state-of-the-arts for this task, video modelling is far from being well solved. In this challenge, we propose spatial-temporal network (StNet) for better joint spatial-temporal modelling and comprehensively video understanding. Besides, given that multi-modal information is contained in video source, we manage to integrate both early-fusion and later-fusion strategy of multi-modal information via our proposed improved temporal Xception network (iTXN) for video understanding. Our StNet RGB single model achieves 78.99\% top-1 precision in the Kinetics-600 validation set and that of our improved temporal Xception network which integrates RGB, flow and audio modalities is up to 82.35\%. After model ensemble, we achieve top-1 precision as high as 85.0\% on the validation set and rank No.1 among all submissions.