 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Complex Networks
Feb 25, 2018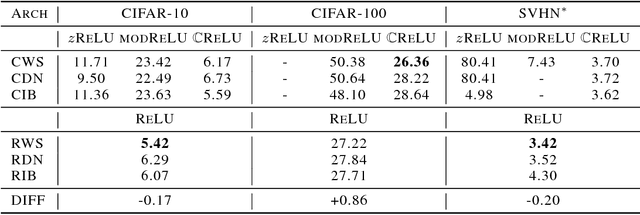
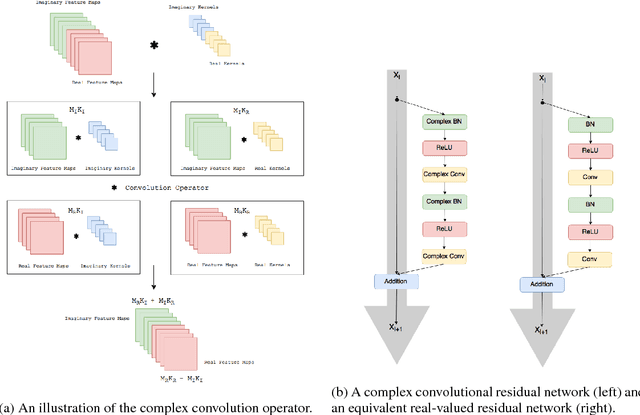

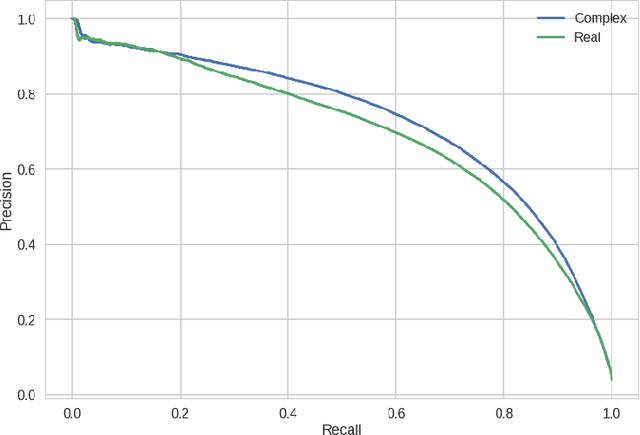
At present, the vast majority of building blocks, techniques, and architectures for deep learning are based on real-valued operations and representations. However, recent work on recurrent neural networks and older fundamental theoretical analysis suggests that complex numbers could have a richer representational capacity and could also facilitate noise-robust memory retrieval mechanisms. Despite their attractive properties and potential for opening up entirely new neural architectures, complex-valued deep neural networks have been marginalized due to the absence of the building blocks required to design such models. In this work, we provide the key atomic components for complex-valued deep neural networks and apply them to convolutional feed-forward networks and convolutional LSTMs. More precisely, we rely on complex convolutions and present algorithms for complex batch-normalization, complex weight initialization strategies for complex-valued neural nets and we use them in experiments with end-to-end training schemes. We demonstrate that such complex-valued models are competitive with their real-valued counterparts. We test deep complex models on several computer vision tasks, on music transcription using the MusicNet dataset and on Speech Spectrum Prediction using the TIMIT dataset. We achieve state-of-the-art performance on these audio-related tasks.
Twin Networks: Matching the Future for Sequence Generation
Feb 23, 2018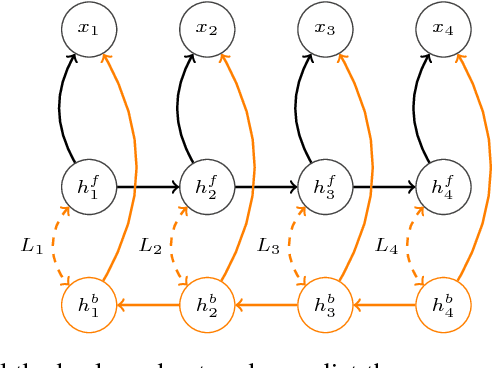

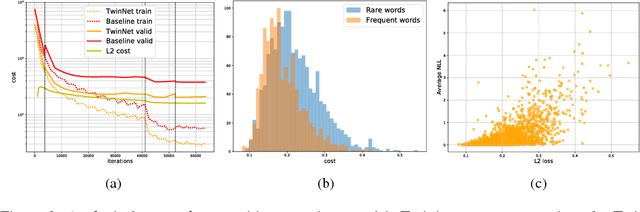
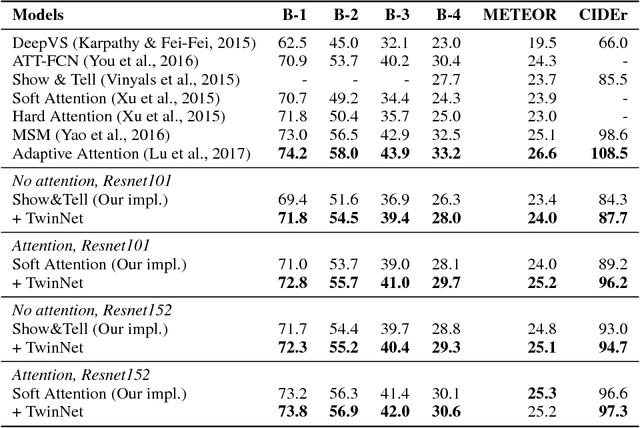
We propose a simple technique for encouraging generative RNNs to plan ahead. We train a "backward" recurrent network to generate a given sequence in reverse order, and we encourage states of the forward model to predict cotemporal states of the backward model. The backward network is used only during training, and plays no role during sampling or inference. We hypothesize that our approach eases modeling of long-term dependencies by implicitly forcing the forward states to hold information about the longer-term future (as contained in the backward states). We show empirically that our approach achieves 9% relative improvement for a speech recognition task, and achieves significant improvement on a COCO caption generation task.
Towards end-to-end spoken language understanding
Feb 23, 2018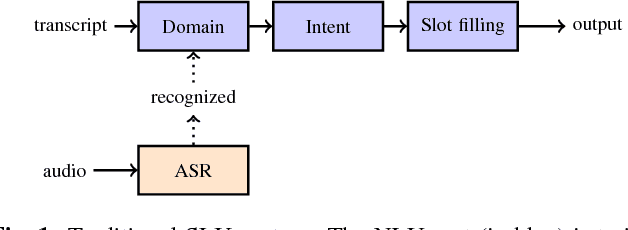

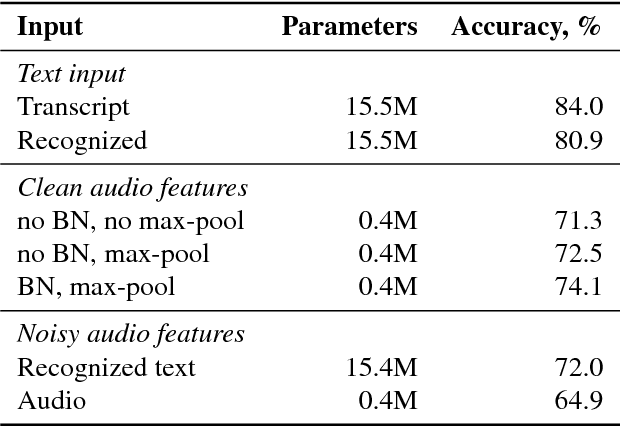
Spoken language understanding system is traditionally designed as a pipeline of a number of components. First, the audio signal is processed by an automatic speech recognizer for transcription or n-best hypotheses. With the recognition results, a natural language understanding system classifies the text to structured data as domain, intent and slots for down-streaming consumers, such as dialog system, hands-free applications. These components are usually developed and optimized independently. In this paper, we present our study on an end-to-end learning system for spoken language understanding. With this unified approach, we can infer the semantic meaning directly from audio features without the intermediate text representation. This study showed that the trained model can achieve reasonable good result and demonstrated that the model can capture the semantic attention directly from the audio features.
Invariant Representations for Noisy Speech Recognition
Nov 27, 2016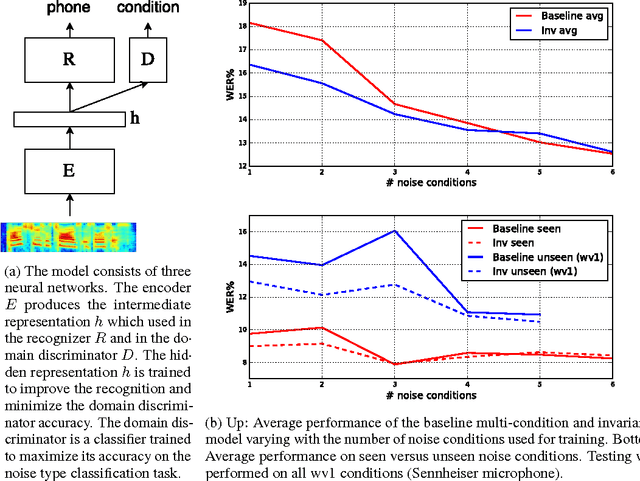
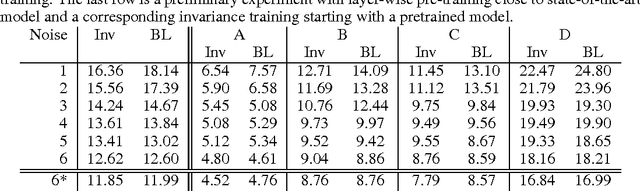
Modern automatic speech recognition (ASR) systems need to be robust under acoustic variability arising from environmental, speaker, channel, and recording conditions. Ensuring such robustness to variability is a challenge in modern day neural network-based ASR systems, especially when all types of variability are not seen during training. We attempt to address this problem by encouraging the neural network acoustic model to learn invariant feature representations. We use ideas from recent research on image generation using Generative Adversarial Networks and domain adaptation ideas extending adversarial gradient-based training. A recent work from Ganin et al. proposes to use adversarial training for image domain adaptation by using an intermediate representation from the main target classification network to deteriorate the domain classifier performance through a separate neural network. Our work focuses on investigating neural architectures which produce representations invariant to noise conditions for ASR. We evaluate the proposed architecture on the Aurora-4 task, a popular benchmark for noise robust ASR. We show that our method generalizes better than the standard multi-condition training especially when only a few noise categories are seen during training.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
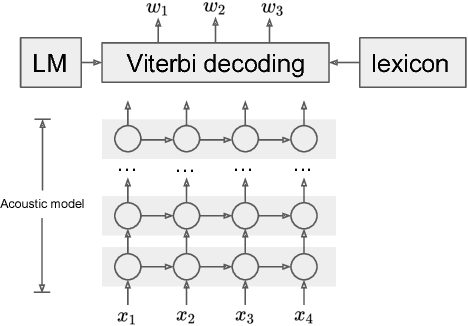
End-to-End Attention-based Large Vocabulary Speech Recognition
Mar 14, 2016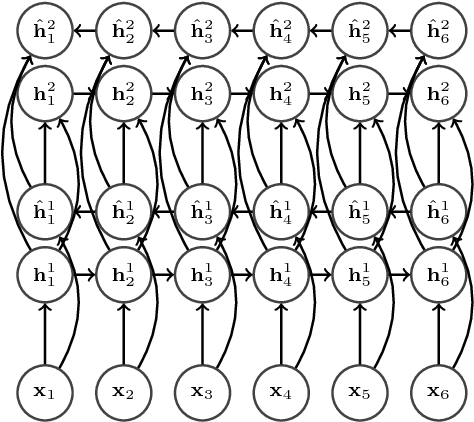
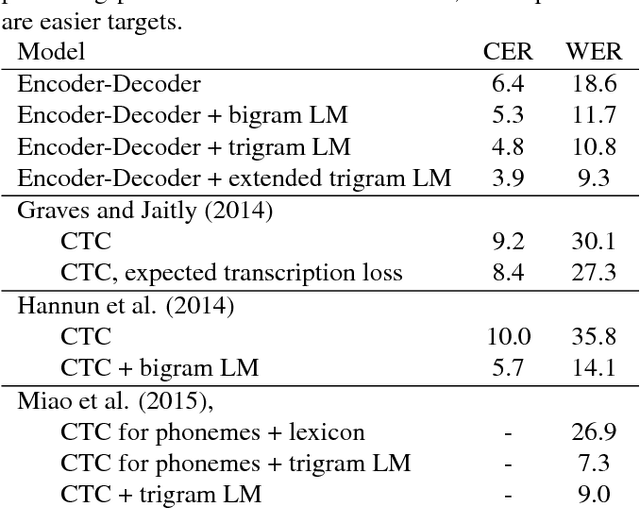
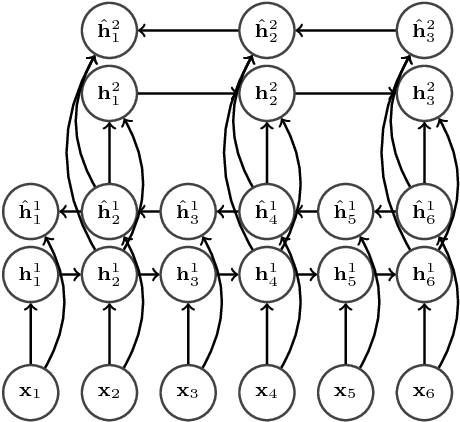
Many of the current state-of-the-art Large Vocabulary Continuous Speech Recognition Systems (LVCSR) are hybrids of neural networks and Hidden Markov Models (HMMs). Most of these systems contain separate components that deal with the acoustic modelling, language modelling and sequence decoding. We investigate a more direct approach in which the HMM is replaced with a Recurrent Neural Network (RNN) that performs sequence prediction directly at the character level. Alignment between the input features and the desired character sequence is learned automatically by an attention mechanism built into the RNN. For each predicted character, the attention mechanism scans the input sequence and chooses relevant frames. We propose two methods to speed up this operation: limiting the scan to a subset of most promising frames and pooling over time the information contained in neighboring frames, thereby reducing source sequence length. Integrating an n-gram language model into the decoding process yields recognition accuracies similar to other HMM-free RNN-based approaches.
Task Loss Estimation for Sequence Prediction
Jan 19, 2016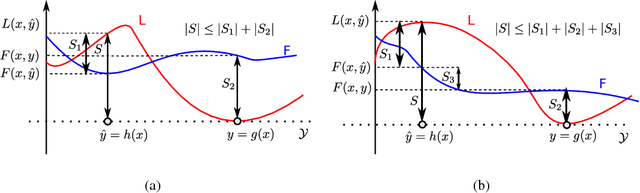
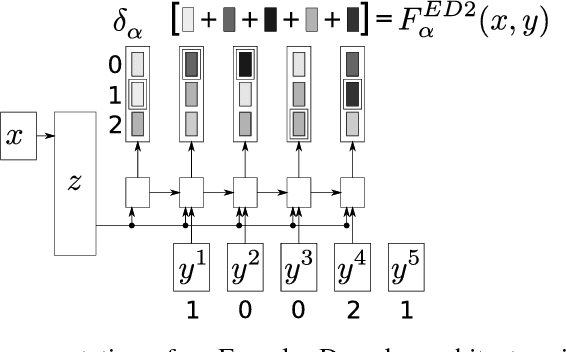
Often, the performance on a supervised machine learning task is evaluated with a emph{task loss} function that cannot be optimized directly. Examples of such loss functions include the classification error, the edit distance and the BLEU score. A common workaround for this problem is to instead optimize a emph{surrogate loss} function, such as for instance cross-entropy or hinge loss. In order for this remedy to be effective, it is important to ensure that minimization of the surrogate loss results in minimization of the task loss, a condition that we call emph{consistency with the task loss}. In this work, we propose another method for deriving differentiable surrogate losses that provably meet this requirement. We focus on the broad class of models that define a score for every input-output pair. Our idea is that this score can be interpreted as an estimate of the task loss, and that the estimation error may be used as a consistent surrogate loss. A distinct feature of such an approach is that it defines the desirable value of the score for every input-output pair. We use this property to design specialized surrogate losses for Encoder-Decoder models often used for sequence prediction tasks. In our experiment, we benchmark on the task of speech recognition. Using a new surrogate loss instead of cross-entropy to train an Encoder-Decoder speech recognizer brings a significant ~13% relative improvement in terms of Character Error Rate (CER) in the case when no extra corpora are used for language modeling.
Attention-Based Models for Speech Recognition
Jun 24, 2015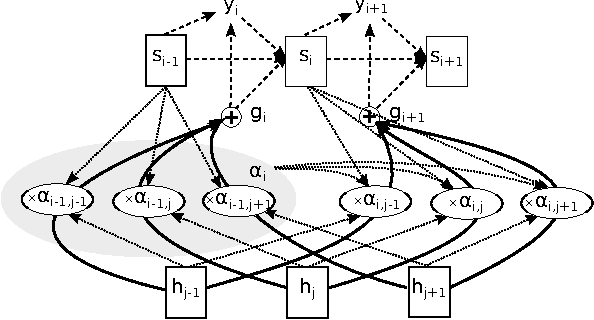

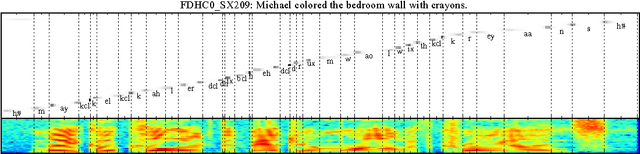
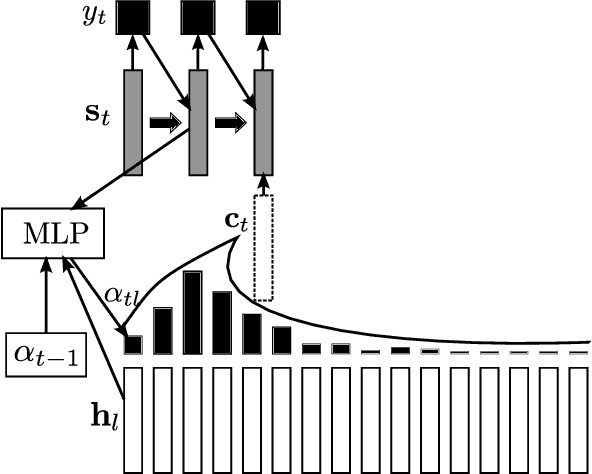
Recurrent sequence generators conditioned on input data through an attention mechanism have recently shown very good performance on a range of tasks in- cluding machine translation, handwriting synthesis and image caption gen- eration. We extend the attention-mechanism with features needed for speech recognition. We show that while an adaptation of the model used for machine translation in reaches a competitive 18.7% phoneme error rate (PER) on the TIMIT phoneme recognition task, it can only be applied to utterances which are roughly as long as the ones it was trained on. We offer a qualitative explanation of this failure and propose a novel and generic method of adding location-awareness to the attention mechanism to alleviate this issue. The new method yields a model that is robust to long inputs and achieves 18% PER in single utterances and 20% in 10-times longer (repeated) utterances. Finally, we propose a change to the at- tention mechanism that prevents it from concentrating too much on single frames, which further reduces PER to 17.6% level.
Blocks and Fuel: Frameworks for deep learning
Jun 01, 2015We introduce two Python frameworks to train neural networks on large datasets: Blocks and Fuel. Blocks is based on Theano, a linear algebra compiler with CUDA-support. It facilitates the training of complex neural network models by providing parametrized Theano operations, attaching metadata to Theano's symbolic computational graph, and providing an extensive set of utilities to assist training the networks, e.g. training algorithms, logging, monitoring, visualization, and serialization. Fuel provides a standard format for machine learning datasets. It allows the user to easily iterate over large datasets, performing many types of pre-processing on the fly.