 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan an Embodied Agent Find Your "Cat-shaped Mug"? LLM-Based Zero-Shot Object Navigation
Mar 06, 2023We present LGX, a novel algorithm for Object Goal Navigation in a "language-driven, zero-shot manner", where an embodied agent navigates to an arbitrarily described target object in a previously unexplored environment. Our approach leverages the capabilities of Large Language Models (LLMs) for making navigational decisions by mapping the LLMs implicit knowledge about the semantic context of the environment into sequential inputs for robot motion planning. Simultaneously, we also conduct generalized target object detection using a pre-trained Vision-Language grounding model. We achieve state-of-the-art zero-shot object navigation results on RoboTHOR with a success rate (SR) improvement of over 27% over the current baseline of the OWL-ViT CLIP on Wheels (OWL CoW). Furthermore, we study the usage of LLMs for robot navigation and present an analysis of the various semantic factors affecting model output. Finally, we showcase the benefits of our approach via real-world experiments that indicate the superior performance of LGX when navigating to and detecting visually unique objects.
MITFAS: Mutual Information based Temporal Feature Alignment and Sampling for Aerial Video Action Recognition
Mar 05, 2023



We present a novel approach for action recognition in UAV videos. Our formulation is designed to handle occlusion and viewpoint changes caused by the movement of a UAV. We use the concept of mutual information to compute and align the regions corresponding to human action or motion in the temporal domain. This enables our recognition model to learn from the key features associated with the motion. We also propose a novel frame sampling method that uses joint mutual information to acquire the most informative frame sequence in UAV videos. We have integrated our approach with X3D and evaluated the performance on multiple datasets. In practice, we achieve 18.9% improvement in Top-1 accuracy over current state-of-the-art methods on UAV-Human(Li et al., 2021), 7.3% improvement on Drone-Action(Perera et al., 2019), and 7.16% improvement on NEC Drones(Choi et al., 2020). We will release the code at the time of publication
GeoLCR: Attention-based Geometric Loop Closure and Registration
Mar 04, 2023We present a novel algorithm for learning-based loop-closure for SLAM (simultaneous localization and mapping) applications. Our approach is designed for general 3D point cloud data, including those from lidar, and is used to prevent accumulated drift over time for autonomous driving. We voxelize the point clouds into coarse voxels and calculate the overlap to estimate if the vehicle drives in a loop. We perform point-level registration to compute the current pose accurately. We have evaluated our approach on well-known datasets KITTI, KITTI-360, Nuscenes, Complex Urban, NCLT, and MulRan. We show at most 2 times improvement in accuracy estimation of translation and rotation. On some challenging sequences, our method is the first approach that can obtain a 100% success rate.
AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning
Mar 02, 2023We propose a novel approach for aerial video action recognition. Our method is designed for videos captured using UAVs and can run on edge or mobile devices. We present a learning-based approach that uses customized auto zoom to automatically identify the human target and scale it appropriately. This makes it easier to extract the key features and reduces the computational overhead. We also present an efficient temporal reasoning algorithm to capture the action information along the spatial and temporal domains within a controllable computational cost. Our approach has been implemented and evaluated both on the desktop with high-end GPUs and on the low power Robotics RB5 Platform for robots and drones. In practice, we achieve 6.1-7.4% improvement over SOTA in Top-1 accuracy on the RoCoG-v2 dataset, 8.3-10.4% improvement on the UAV-Human dataset and 3.2% improvement on the Drone Action dataset.
Scene2BIR: Material-aware learning-based binaural impulse response generator for reconstructed real-world 3D scenes
Feb 02, 2023We present an end-to-end binaural impulse response generator (BIR) to generate plausible sounds in real-time for real-world models. Our approach uses a novel neural-network-based BIR generator (Scene2BIR) for the reconstructed 3D model. We propose a graph neural network that uses both the material and the topology information of the 3D scenes and generates a scene latent vector. Moreover, we use a conditional generative adversarial network (CGAN) to generate BIRs from the scene latent vector. Our network is able to handle holes or other artifacts in the reconstructed 3D mesh model. We present an efficient cost function to the generator network to incorporate spatial audio effects. Given the source and the listener position, our approach can generate a BIR in 0.1 milliseconds on an NVIDIA GeForce RTX 2080 Ti GPU and can easily handle multiple sources. We have evaluated the accuracy of our approach with real-world captured BIRs and an interactive geometric sound propagation algorithm.
Beyond Exponentially Fast Mixing in Average-Reward Reinforcement Learning via Multi-Level Monte Carlo Actor-Critic
Feb 01, 2023


Many existing reinforcement learning (RL) methods employ stochastic gradient iteration on the back end, whose stability hinges upon a hypothesis that the data-generating process mixes exponentially fast with a rate parameter that appears in the step-size selection. Unfortunately, this assumption is violated for large state spaces or settings with sparse rewards, and the mixing time is unknown, making the step size inoperable. In this work, we propose an RL methodology attuned to the mixing time by employing a multi-level Monte Carlo estimator for the critic, the actor, and the average reward embedded within an actor-critic (AC) algorithm. This method, which we call \textbf{M}ulti-level \textbf{A}ctor-\textbf{C}ritic (MAC), is developed especially for infinite-horizon average-reward settings and neither relies on oracle knowledge of the mixing time in its parameter selection nor assumes its exponential decay; it, therefore, is readily applicable to applications with slower mixing times. Nonetheless, it achieves a convergence rate comparable to the state-of-the-art AC algorithms. We experimentally show that these alleviated restrictions on the technical conditions required for stability translate to superior performance in practice for RL problems with sparse rewards.
STEERING: Stein Information Directed Exploration for Model-Based Reinforcement Learning
Jan 28, 2023Directed Exploration is a crucial challenge in reinforcement learning (RL), especially when rewards are sparse. Information-directed sampling (IDS), which optimizes the information ratio, seeks to do so by augmenting regret with information gain. However, estimating information gain is computationally intractable or relies on restrictive assumptions which prohibit its use in many practical instances. In this work, we posit an alternative exploration incentive in terms of the integral probability metric (IPM) between a current estimate of the transition model and the unknown optimal, which under suitable conditions, can be computed in closed form with the kernelized Stein discrepancy (KSD). Based on KSD, we develop a novel algorithm STEERING: \textbf{STE}in information dir\textbf{E}cted exploration for model-based \textbf{R}einforcement Learn\textbf{ING}. To enable its derivation, we develop fundamentally new variants of KSD for discrete conditional distributions. We further establish that STEERING archives sublinear Bayesian regret, improving upon prior learning rates of information-augmented MBRL, IDS included. Experimentally, we show that the proposed algorithm is computationally affordable and outperforms several prior approaches.
Synthetic Wave-Geometric Impulse Responses for Improved Speech Dereverberation
Dec 10, 2022We present a novel approach to improve the performance of learning-based speech dereverberation using accurate synthetic datasets. Our approach is designed to recover the reverb-free signal from a reverberant speech signal. We show that accurately simulating the low-frequency components of Room Impulse Responses (RIRs) is important to achieving good dereverberation. We use the GWA dataset that consists of synthetic RIRs generated in a hybrid fashion: an accurate wave-based solver is used to simulate the lower frequencies and geometric ray tracing methods simulate the higher frequencies. We demonstrate that speech dereverberation models trained on hybrid synthetic RIRs outperform models trained on RIRs generated by prior geometric ray tracing methods on four real-world RIR datasets.
Towards Improved Room Impulse Response Estimation for Speech Recognition
Nov 08, 2022
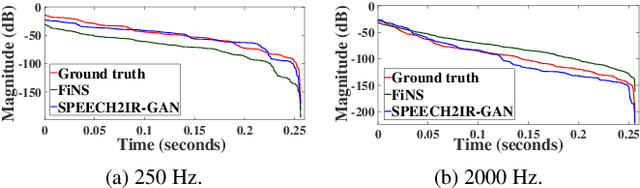
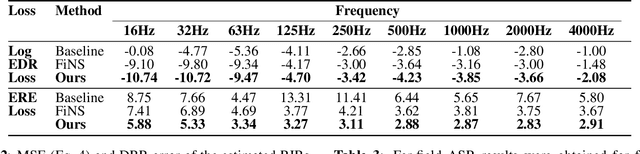

We propose to characterize and improve the performance of blind room impulse response (RIR) estimation systems in the context of a downstream application scenario, far-field automatic speech recognition (ASR). We first draw the connection between improved RIR estimation and improved ASR performance, as a means of evaluating neural RIR estimators. We then propose a GAN-based architecture that encodes RIR features from reverberant speech and constructs an RIR from the encoded features, and uses a novel energy decay relief loss to optimize for capturing energy-based properties of the input reverberant speech. We show that our model outperforms the state-of-the-art baselines on acoustic benchmarks (by 72% on the energy decay relief and 22% on an early-reflection energy metric), as well as in an ASR evaluation task (by 6.9% in word error rate).
SLICER: Learning universal audio representations using low-resource self-supervised pre-training
Nov 02, 2022We present a new Self-Supervised Learning (SSL) approach to pre-train encoders on unlabeled audio data that reduces the need for large amounts of labeled data for audio and speech classification. Our primary aim is to learn audio representations that can generalize across a large variety of speech and non-speech tasks in a low-resource un-labeled audio pre-training setting. Inspired by the recent success of clustering and contrasting learning paradigms for SSL-based speech representation learning, we propose SLICER (Symmetrical Learning of Instance and Cluster-level Efficient Representations), which brings together the best of both clustering and contrasting learning paradigms. We use a symmetric loss between latent representations from student and teacher encoders and simultaneously solve instance and cluster-level contrastive learning tasks. We obtain cluster representations online by just projecting the input spectrogram into an output subspace with dimensions equal to the number of clusters. In addition, we propose a novel mel-spectrogram augmentation procedure, k-mix, based on mixup, which does not require labels and aids unsupervised representation learning for audio. Overall, SLICER achieves state-of-the-art results on the LAPE Benchmark \cite{9868132}, significantly outperforming DeLoRes-M and other prior approaches, which are pre-trained on $10\times$ larger of unsupervised data. We will make all our codes available on GitHub.