 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Really Perform Bad for Graph Representation?
Jun 17, 2021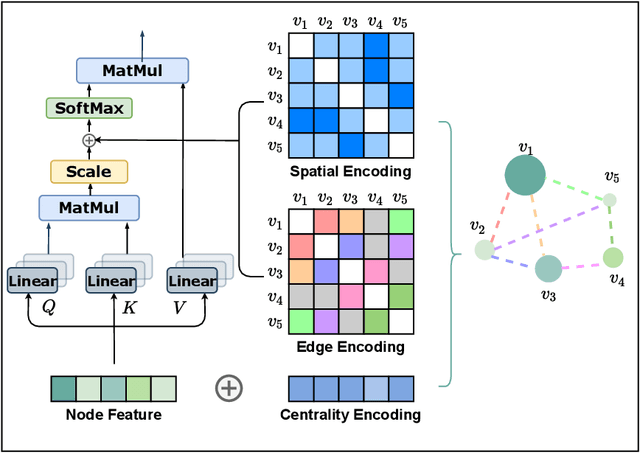
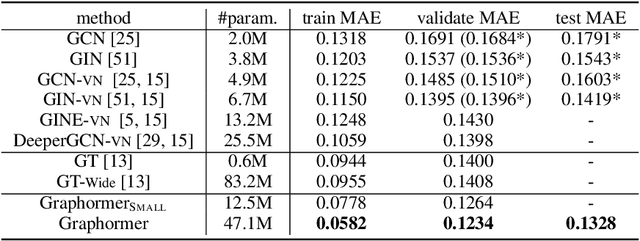

The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.
How could Neural Networks understand Programs?
May 31, 2021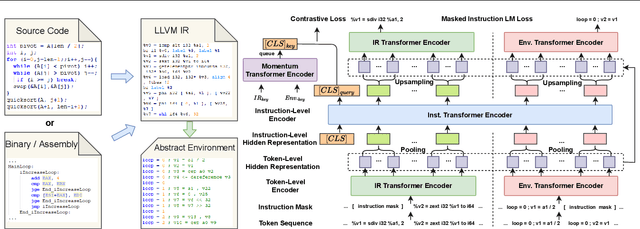
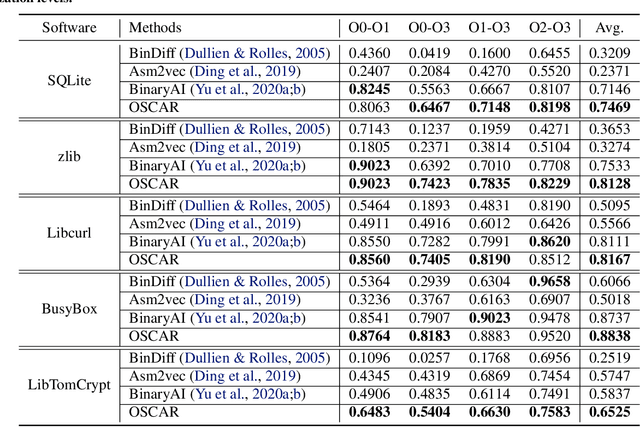


Semantic understanding of programs is a fundamental problem for programming language processing (PLP). Recent works that learn representations of code based on pre-training techniques in NLP have pushed the frontiers in this direction. However, the semantics of PL and NL have essential differences. These being ignored, we believe it is difficult to build a model to better understand programs, by either directly applying off-the-shelf NLP pre-training techniques to the source code, or adding features to the model by the heuristic. In fact, the semantics of a program can be rigorously defined by formal semantics in PL theory. For example, the operational semantics, describes the meaning of a valid program as updating the environment (i.e., the memory address-value function) through fundamental operations, such as memory I/O and conditional branching. Inspired by this, we propose a novel program semantics learning paradigm, that the model should learn from information composed of (1) the representations which align well with the fundamental operations in operational semantics, and (2) the information of environment transition, which is indispensable for program understanding. To validate our proposal, we present a hierarchical Transformer-based pre-training model called OSCAR to better facilitate the understanding of programs. OSCAR learns from intermediate representation (IR) and an encoded representation derived from static analysis, which are used for representing the fundamental operations and approximating the environment transitions respectively. OSCAR empirically shows the outstanding capability of program semantics understanding on many practical software engineering tasks.
Adversarial Training with Rectified Rejection
May 31, 2021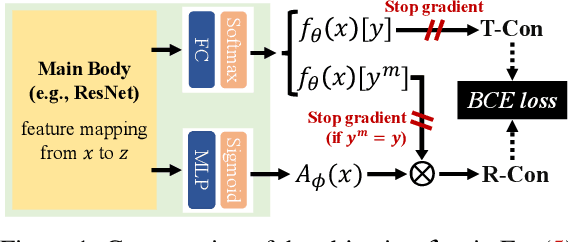
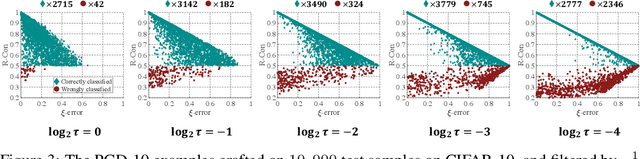
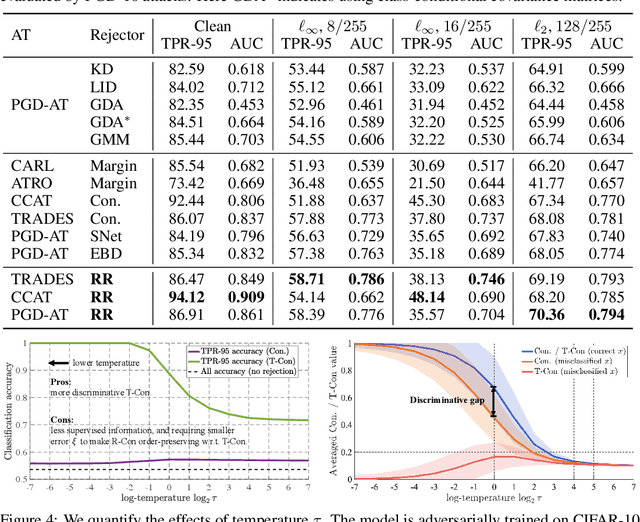
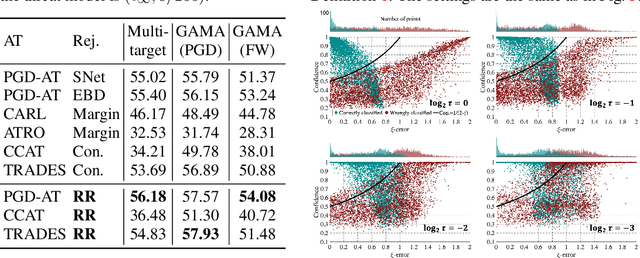
Adversarial training (AT) is one of the most effective strategies for promoting model robustness, whereas even the state-of-the-art adversarially trained models struggle to exceed 60% robust test accuracy on CIFAR-10 without additional data, which is far from practical. A natural way to break this accuracy bottleneck is to introduce a rejection option, where confidence is a commonly used certainty proxy. However, the vanilla confidence can overestimate the model certainty if the input is wrongly classified. To this end, we propose to use true confidence (T-Con) (i.e., predicted probability of the true class) as a certainty oracle, and learn to predict T-Con by rectifying confidence. We prove that under mild conditions, a rectified confidence (R-Con) rejector and a confidence rejector can be coupled to distinguish any wrongly classified input from correctly classified ones, even under adaptive attacks. We also quantify that training R-Con to be aligned with T-Con could be an easier task than learning robust classifiers. In our experiments, we evaluate our rectified rejection (RR) module on CIFAR-10, CIFAR-10-C, and CIFAR-100 under several attacks, and demonstrate that the RR module is well compatible with different AT frameworks on improving robustness, with little extra computation.
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021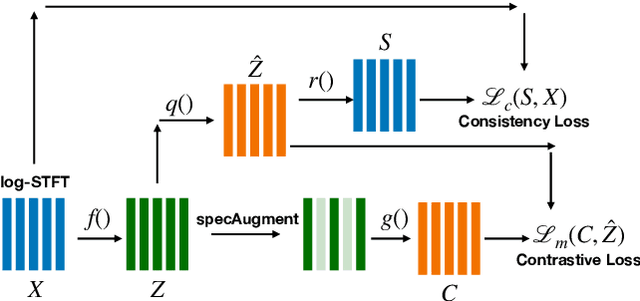

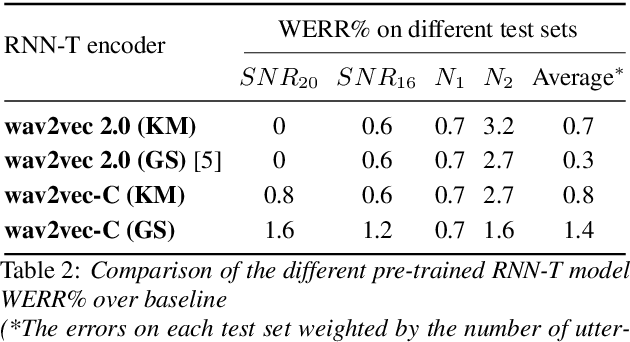
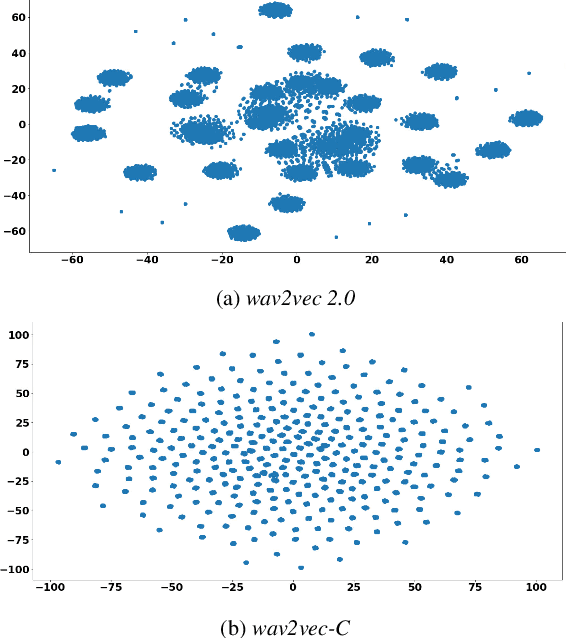
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Transformers with Competitive Ensembles of Independent Mechanisms
Feb 27, 2021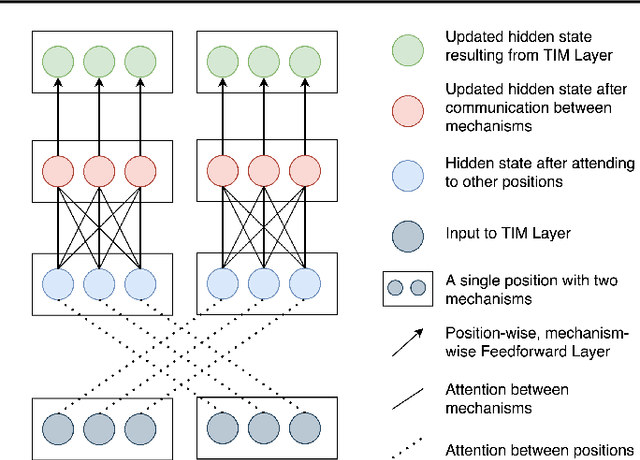
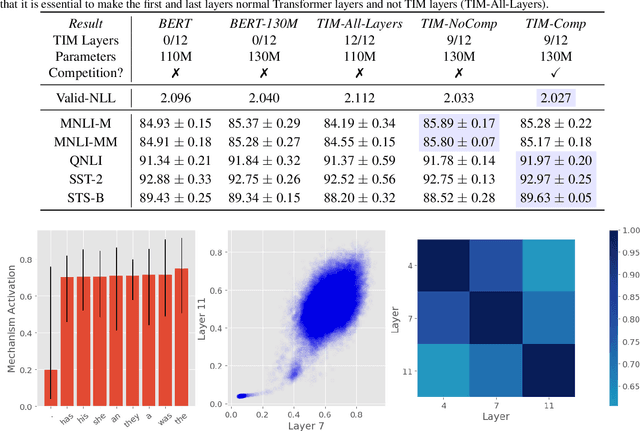
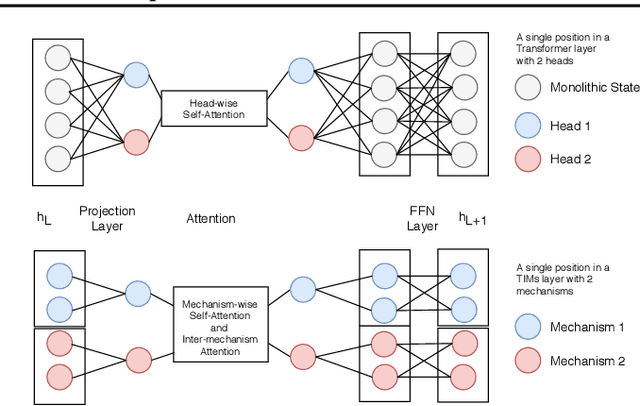
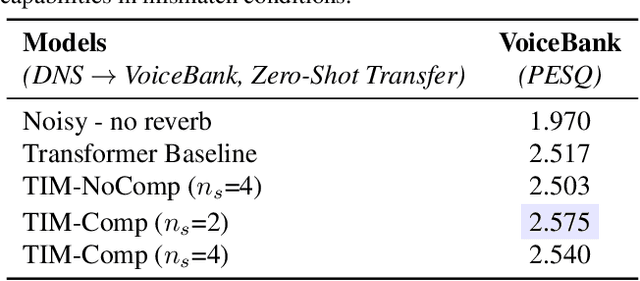
An important development in deep learning from the earliest MLPs has been a move towards architectures with structural inductive biases which enable the model to keep distinct sources of information and routes of processing well-separated. This structure is linked to the notion of independent mechanisms from the causality literature, in which a mechanism is able to retain the same processing as irrelevant aspects of the world are changed. For example, convnets enable separation over positions, while attention-based architectures (especially Transformers) learn which combination of positions to process dynamically. In this work we explore a way in which the Transformer architecture is deficient: it represents each position with a large monolithic hidden representation and a single set of parameters which are applied over the entire hidden representation. This potentially throws unrelated sources of information together, and limits the Transformer's ability to capture independent mechanisms. To address this, we propose Transformers with Independent Mechanisms (TIM), a new Transformer layer which divides the hidden representation and parameters into multiple mechanisms, which only exchange information through attention. Additionally, we propose a competition mechanism which encourages these mechanisms to specialize over time steps, and thus be more independent. We study TIM on a large-scale BERT model, on the Image Transformer, and on speech enhancement and find evidence for semantically meaningful specialization as well as improved performance.
LazyFormer: Self Attention with Lazy Update
Feb 25, 2021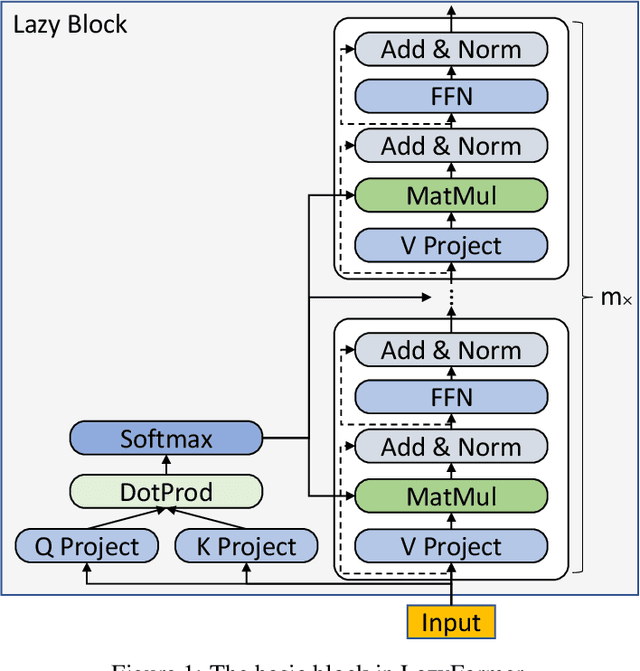


Improving the efficiency of Transformer-based language pre-training is an important task in NLP, especially for the self-attention module, which is computationally expensive. In this paper, we propose a simple but effective solution, called \emph{LazyFormer}, which computes the self-attention distribution infrequently. LazyFormer composes of multiple lazy blocks, each of which contains multiple Transformer layers. In each lazy block, the self-attention distribution is only computed once in the first layer and then is reused in all upper layers. In this way, the cost of computation could be largely saved. We also provide several training tricks for LazyFormer. Extensive experiments demonstrate the effectiveness of the proposed method.
Less is More: Pre-training a Strong Siamese Encoder Using a Weak Decoder
Feb 18, 2021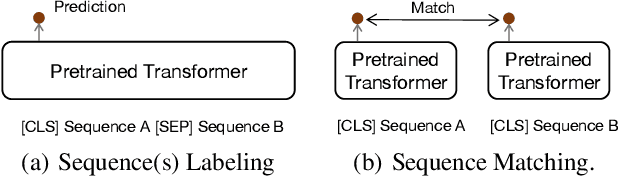
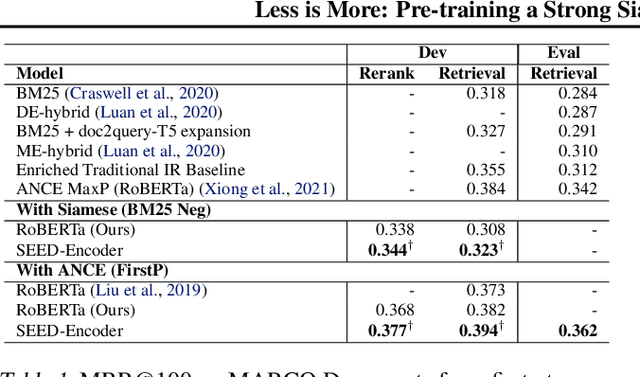
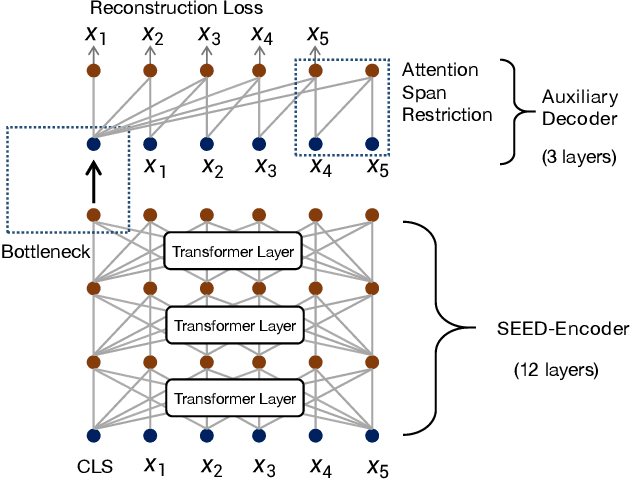
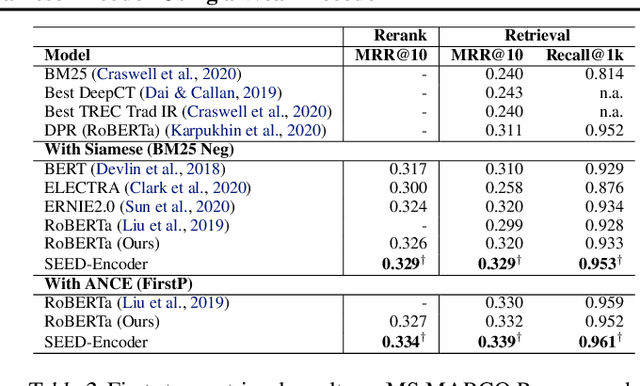
Many real-world applications use Siamese networks to efficiently match text sequences at scale, which require high-quality sequence encodings. This paper pre-trains language models dedicated to sequence matching in Siamese architectures. We first hypothesize that a representation is better for sequence matching if the entire sequence can be reconstructed from it, which, however, is unlikely to be achieved in standard autoencoders: A strong decoder can rely on its capacity and natural language patterns to reconstruct and bypass the needs of better sequence encodings. Therefore we propose a new self-learning method that pretrains the encoder with a weak decoder, which reconstructs the original sequence from the encoder's [CLS] representations but is restricted in both capacity and attention span. In our experiments on web search and recommendation, the pre-trained SEED-Encoder, "SiamEsE oriented encoder by reconstructing from weak decoder", shows significantly better generalization ability when fine-tuned in Siamese networks, improving overall accuracy and few-shot performances. Our code and models will be released.
Revisiting Language Encoding in Learning Multilingual Representations
Feb 16, 2021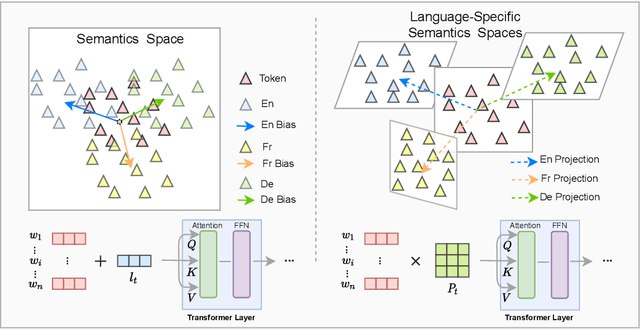
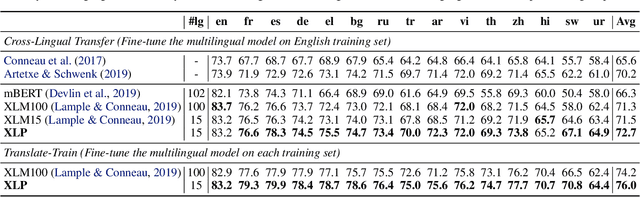
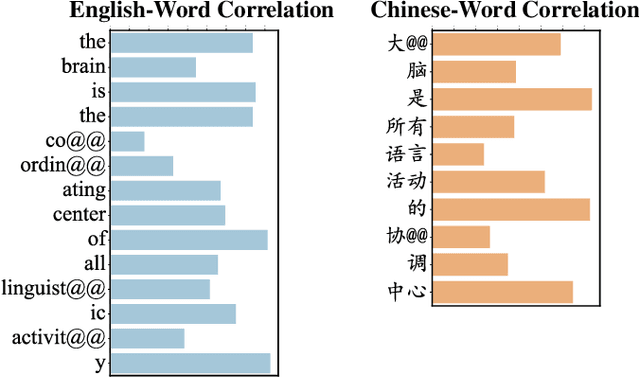

Transformer has demonstrated its great power to learn contextual word representations for multiple languages in a single model. To process multilingual sentences in the model, a learnable vector is usually assigned to each language, which is called "language embedding". The language embedding can be either added to the word embedding or attached at the beginning of the sentence. It serves as a language-specific signal for the Transformer to capture contextual representations across languages. In this paper, we revisit the use of language embedding and identify several problems in the existing formulations. By investigating the interaction between language embedding and word embedding in the self-attention module, we find that the current methods cannot reflect the language-specific word correlation well. Given these findings, we propose a new approach called Cross-lingual Language Projection (XLP) to replace language embedding. For a sentence, XLP projects the word embeddings into language-specific semantic space, and then the projected embeddings will be fed into the Transformer model to process with their language-specific meanings. In such a way, XLP achieves the purpose of appropriately encoding "language" in a multilingual Transformer model. Experimental results show that XLP can freely and significantly boost the model performance on extensive multilingual benchmark datasets. Codes and models will be released at https://github.com/lsj2408/XLP.
Towards Certifying $\ell_\infty$ Robustness using Neural Networks with $\ell_\infty$-dist Neurons
Feb 10, 2021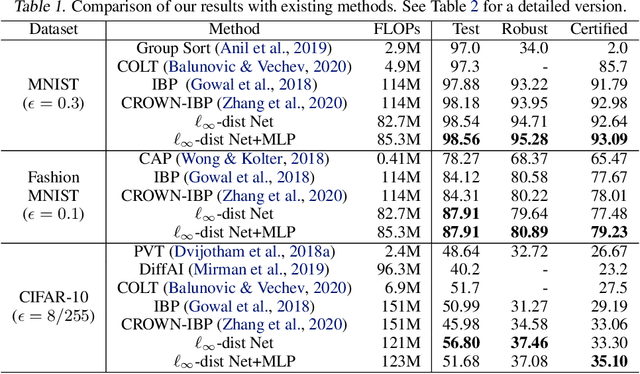
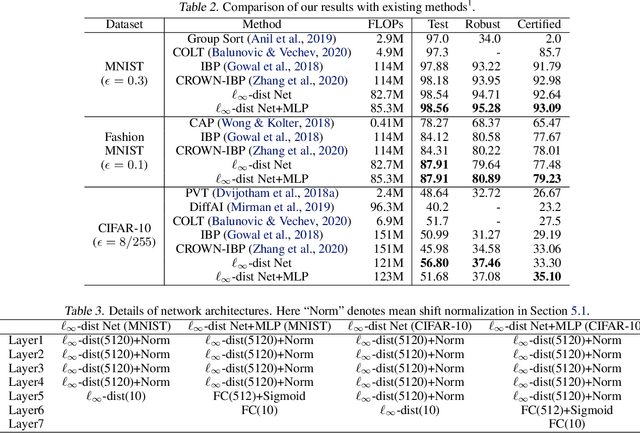
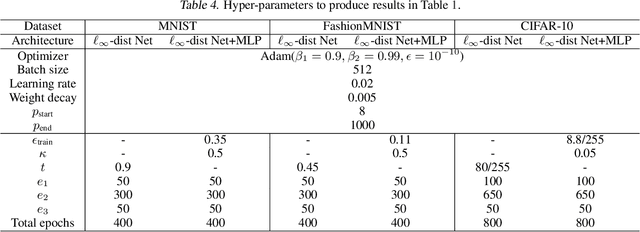

It is well-known that standard neural networks, even with a high classification accuracy, are vulnerable to small $\ell_\infty$-norm bounded adversarial perturbations. Although many attempts have been made, most previous works either can only provide empirical verification of the defense to a particular attack method, or can only develop a certified guarantee of the model robustness in limited scenarios. In this paper, we seek for a new approach to develop a theoretically principled neural network that inherently resists $\ell_\infty$ perturbations. In particular, we design a novel neuron that uses $\ell_\infty$-distance as its basic operation (which we call $\ell_\infty$-dist neuron), and show that any neural network constructed with $\ell_\infty$-dist neurons (called $\ell_{\infty}$-dist net) is naturally a 1-Lipschitz function with respect to $\ell_\infty$-norm. This directly provides a rigorous guarantee of the certified robustness based on the margin of prediction outputs. We also prove that such networks have enough expressive power to approximate any 1-Lipschitz function with robust generalization guarantee. Our experimental results show that the proposed network is promising. Using $\ell_{\infty}$-dist nets as the basic building blocks, we consistently achieve state-of-the-art performance on commonly used datasets: 93.09% certified accuracy on MNIST ($\epsilon=0.3$), 79.23% on Fashion MNIST ($\epsilon=0.1$) and 35.10% on CIFAR-10 ($\epsilon=8/255$).
CODE-AE: A Coherent De-confounding Autoencoder for Predicting Patient-Specific Drug Response From Cell Line Transcriptomics
Jan 31, 2021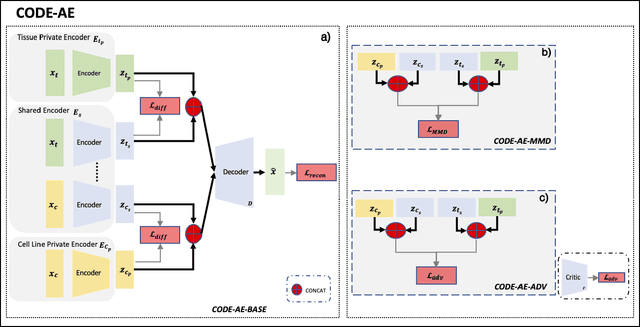
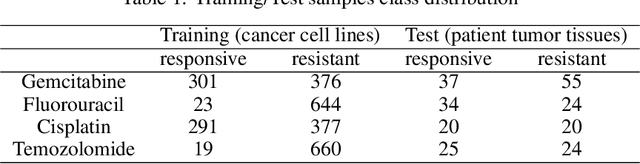
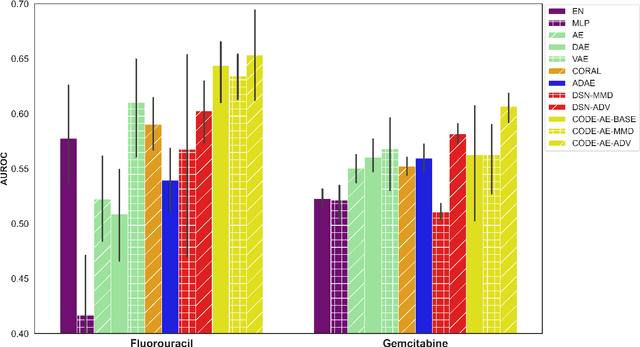

Accurate and robust prediction of patient's response to drug treatments is critical for developing precision medicine. However, it is often difficult to obtain a sufficient amount of coherent drug response data from patients directly for training a generalized machine learning model. Although the utilization of rich cell line data provides an alternative solution, it is challenging to transfer the knowledge obtained from cell lines to patients due to various confounding factors. Few existing transfer learning methods can reliably disentangle common intrinsic biological signals from confounding factors in the cell line and patient data. In this paper, we develop a Coherent Deconfounding Autoencoder (CODE-AE) that can extract both common biological signals shared by incoherent samples and private representations unique to each data set, transfer knowledge learned from cell line data to tissue data, and separate confounding factors from them. Extensive studies on multiple data sets demonstrate that CODE-AE significantly improves the accuracy and robustness over state-of-the-art methods in both predicting patient drug response and de-confounding biological signals. Thus, CODE-AE provides a useful framework to take advantage of in vitro omics data for developing generalized patient predictive models. The source code is available at https://github.com/XieResearchGroup/CODE-AE.