 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabrik: An Online Collaborative Neural Network Editor
Oct 27, 2018
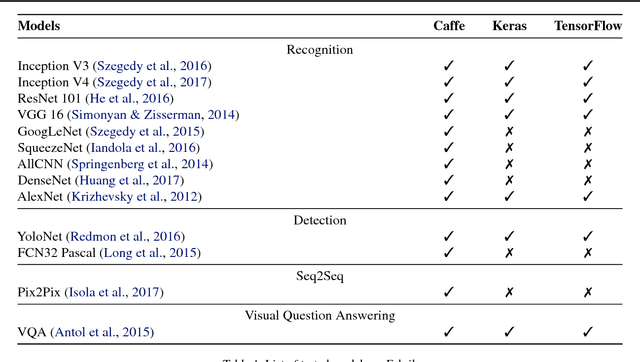
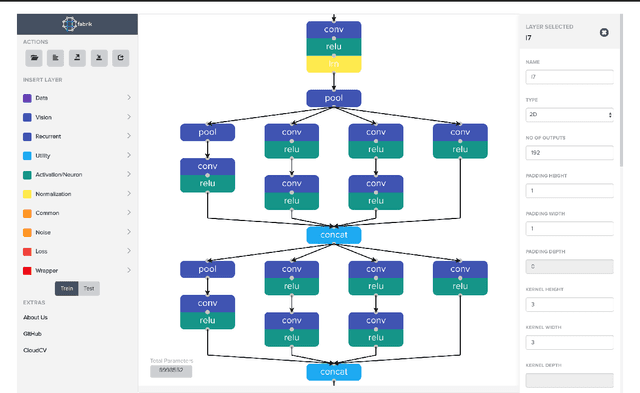

We present Fabrik, an online neural network editor that provides tools to visualize, edit, and share neural networks from within a browser. Fabrik provides a simple and intuitive GUI to import neural networks written in popular deep learning frameworks such as Caffe, Keras, and TensorFlow, and allows users to interact with, build, and edit models via simple drag and drop. Fabrik is designed to be framework agnostic and support high interoperability, and can be used to export models back to any supported framework. Finally, it provides powerful collaborative features to enable users to iterate over model design remotely and at scale.
TarMAC: Targeted Multi-Agent Communication
Oct 26, 2018
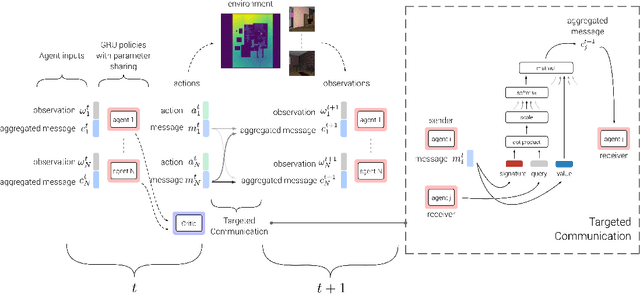
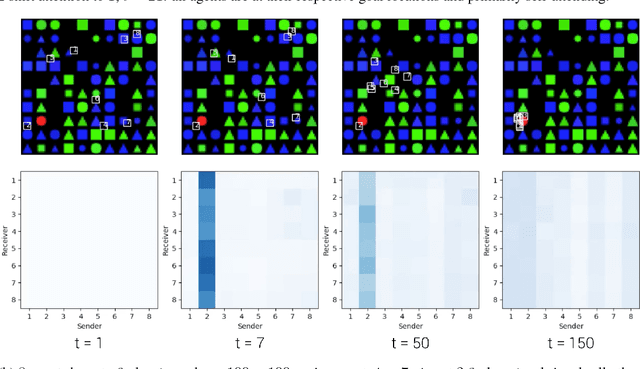

We explore a collaborative multi-agent reinforcement learning setting where a team of agents attempts to solve cooperative tasks in partially-observable environments. In this scenario, learning an effective communication protocol is key. We propose a communication architecture that allows for targeted communication, where agents learn both what messages to send and who to send them to, solely from downstream task-specific reward without any communication supervision. Additionally, we introduce a multi-stage communication approach where the agents co-ordinate via multiple rounds of communication before taking actions in the environment. We evaluate our approach on a diverse set of cooperative multi-agent tasks, of varying difficulties, with varying number of agents, in a variety of environments ranging from 2D grid layouts of shapes and simulated traffic junctions to complex 3D indoor environments. We demonstrate the benefits of targeted as well as multi-stage communication. Moreover, we show that the targeted communication strategies learned by agents are both interpretable and intuitive.
Neural Modular Control for Embodied Question Answering
Oct 26, 2018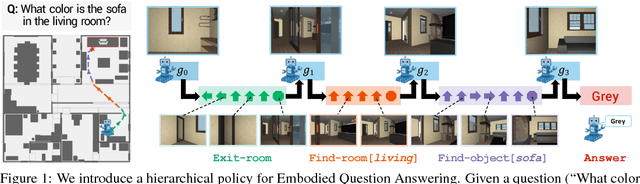

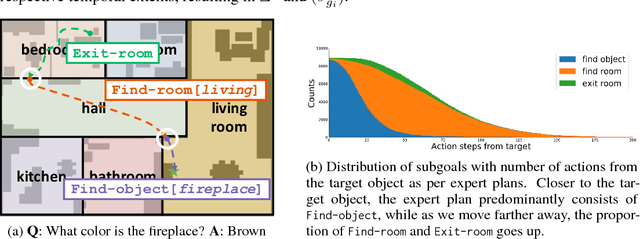
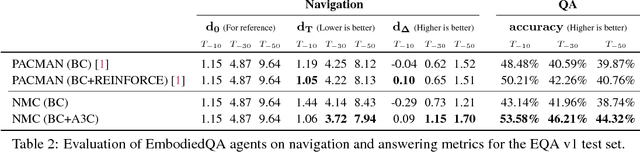
We present a modular approach for learning policies for navigation over long planning horizons from language input. Our hierarchical policy operates at multiple timescales, where the higher-level master policy proposes subgoals to be executed by specialized sub-policies. Our choice of subgoals is compositional and semantic, i.e. they can be sequentially combined in arbitrary orderings, and assume human-interpretable descriptions (e.g. 'exit room', 'find kitchen', 'find refrigerator', etc.). We use imitation learning to warm-start policies at each level of the hierarchy, dramatically increasing sample efficiency, followed by reinforcement learning. Independent reinforcement learning at each level of hierarchy enables sub-policies to adapt to consequences of their actions and recover from errors. Subsequent joint hierarchical training enables the master policy to adapt to the sub-policies.
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Oct 22, 2018
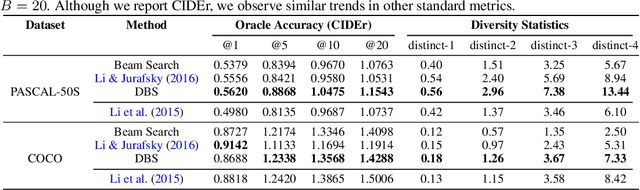
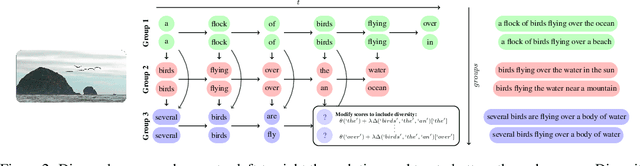
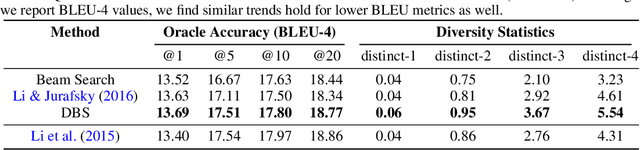
Neural sequence models are widely used to model time-series data. Equally ubiquitous is the usage of beam search (BS) as an approximate inference algorithm to decode output sequences from these models. BS explores the search space in a greedy left-right fashion retaining only the top-B candidates - resulting in sequences that differ only slightly from each other. Producing lists of nearly identical sequences is not only computationally wasteful but also typically fails to capture the inherent ambiguity of complex AI tasks. To overcome this problem, we propose Diverse Beam Search (DBS), an alternative to BS that decodes a list of diverse outputs by optimizing for a diversity-augmented objective. We observe that our method finds better top-1 solutions by controlling for the exploration and exploitation of the search space - implying that DBS is a better search algorithm. Moreover, these gains are achieved with minimal computational or memory over- head as compared to beam search. To demonstrate the broad applicability of our method, we present results on image captioning, machine translation and visual question generation using both standard quantitative metrics and qualitative human studies. Further, we study the role of diversity for image-grounded language generation tasks as the complexity of the image changes. We observe that our method consistently outperforms BS and previously proposed techniques for diverse decoding from neural sequence models.
Visual Curiosity: Learning to Ask Questions to Learn Visual Recognition
Oct 01, 2018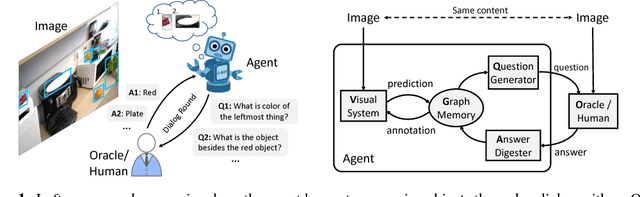
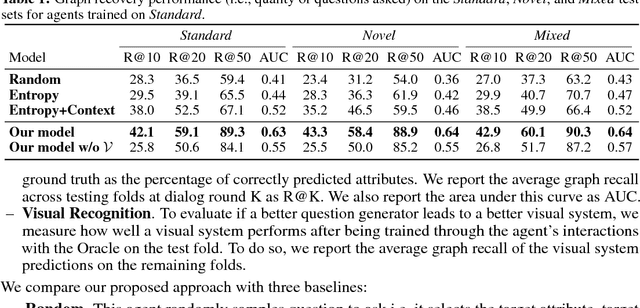
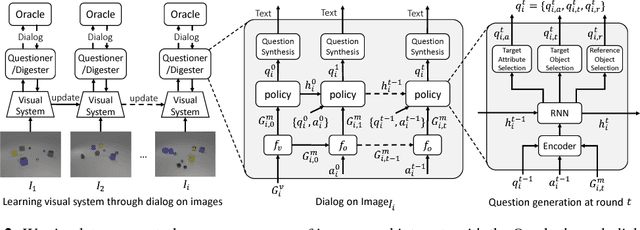

In an open-world setting, it is inevitable that an intelligent agent (e.g., a robot) will encounter visual objects, attributes or relationships it does not recognize. In this work, we develop an agent empowered with visual curiosity, i.e. the ability to ask questions to an Oracle (e.g., human) about the contents in images (e.g., What is the object on the left side of the red cube?) and build visual recognition model based on the answers received (e.g., Cylinder). In order to do this, the agent must (1) understand what it recognizes and what it does not, (2) formulate a valid, unambiguous and informative language query (a question) to ask the Oracle, (3) derive the parameters of visual classifiers from the Oracle response and (4) leverage the updated visual classifiers to ask more clarified questions. Specifically, we propose a novel framework and formulate the learning of visual curiosity as a reinforcement learning problem. In this framework, all components of our agent, visual recognition module (to see), question generation policy (to ask), answer digestion module (to understand) and graph memory module (to memorize), are learned entirely end-to-end to maximize the reward derived from the scene graph obtained by the agent as a consequence of the dialog with the Oracle. Importantly, the question generation policy is disentangled from the visual recognition system and specifics of the environment. Consequently, we demonstrate a sort of double generalization. Our question generation policy generalizes to new environments and a new pair of eyes, i.e., new visual system. Trained on a synthetic dataset, our results show that our agent learns new visual concepts significantly faster than several heuristic baselines, even when tested on synthetic environments with novel objects, as well as in a realistic environment.
Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples
Sep 09, 2018


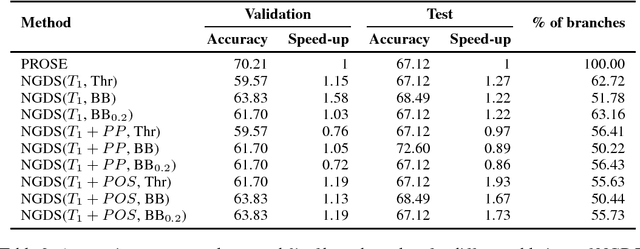
Synthesizing user-intended programs from a small number of input-output examples is a challenging problem with several important applications like spreadsheet manipulation, data wrangling and code refactoring. Existing synthesis systems either completely rely on deductive logic techniques that are extensively hand-engineered or on purely statistical models that need massive amounts of data, and in general fail to provide real-time synthesis on challenging benchmarks. In this work, we propose Neural Guided Deductive Search (NGDS), a hybrid synthesis technique that combines the best of both symbolic logic techniques and statistical models. Thus, it produces programs that satisfy the provided specifications by construction and generalize well on unseen examples, similar to data-driven systems. Our technique effectively utilizes the deductive search framework to reduce the learning problem of the neural component to a simple supervised learning setup. Further, this allows us to both train on sparingly available real-world data and still leverage powerful recurrent neural network encoders. We demonstrate the effectiveness of our method by evaluating on real-world customer scenarios by synthesizing accurate programs with up to 12x speed-up compared to state-of-the-art systems.
Visual Coreference Resolution in Visual Dialog using Neural Module Networks
Sep 06, 2018

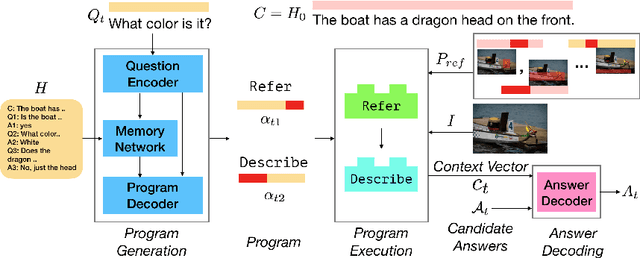

Visual dialog entails answering a series of questions grounded in an image, using dialog history as context. In addition to the challenges found in visual question answering (VQA), which can be seen as one-round dialog, visual dialog encompasses several more. We focus on one such problem called visual coreference resolution that involves determining which words, typically noun phrases and pronouns, co-refer to the same entity/object instance in an image. This is crucial, especially for pronouns (e.g., `it'), as the dialog agent must first link it to a previous coreference (e.g., `boat'), and only then can rely on the visual grounding of the coreference `boat' to reason about the pronoun `it'. Prior work (in visual dialog) models visual coreference resolution either (a) implicitly via a memory network over history, or (b) at a coarse level for the entire question; and not explicitly at a phrase level of granularity. In this work, we propose a neural module network architecture for visual dialog by introducing two novel modules - Refer and Exclude - that perform explicit, grounded, coreference resolution at a finer word level. We demonstrate the effectiveness of our model on MNIST Dialog, a visually simple yet coreference-wise complex dataset, by achieving near perfect accuracy, and on VisDial, a large and challenging visual dialog dataset on real images, where our model outperforms other approaches, and is more interpretable, grounded, and consistent qualitatively.
Choose Your Neuron: Incorporating Domain Knowledge through Neuron-Importance
Aug 08, 2018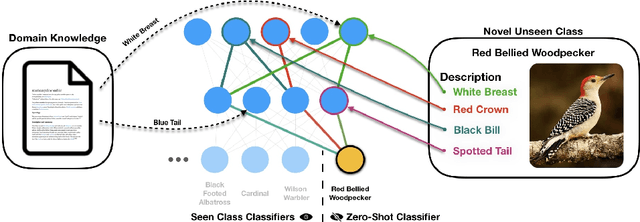
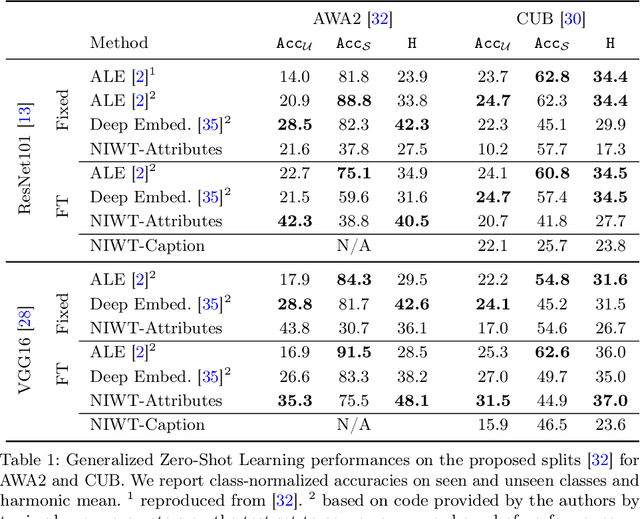
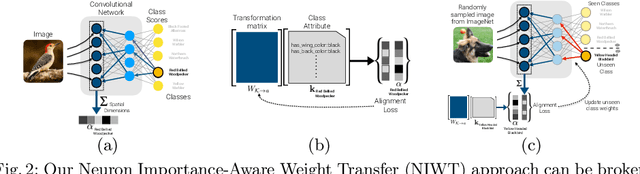

Individual neurons in convolutional neural networks supervised for image-level classification tasks have been shown to implicitly learn semantically meaningful concepts ranging from simple textures and shapes to whole or partial objects - forming a "dictionary" of concepts acquired through the learning process. In this work we introduce a simple, efficient zero-shot learning approach based on this observation. Our approach, which we call Neuron Importance-AwareWeight Transfer (NIWT), learns to map domain knowledge about novel "unseen" classes onto this dictionary of learned concepts and then optimizes for network parameters that can effectively combine these concepts - essentially learning classifiers by discovering and composing learned semantic concepts in deep networks. Our approach shows improvements over previous approaches on the CUBirds and AWA2 generalized zero-shot learning benchmarks. We demonstrate our approach on a diverse set of semantic inputs as external domain knowledge including attributes and natural language captions. Moreover by learning inverse mappings, NIWT can provide visual and textual explanations for the predictions made by the newly learned classifiers and provide neuron names. Our code is available at https://github.com/ramprs/neuron-importance-zsl.
Graph R-CNN for Scene Graph Generation
Aug 01, 2018

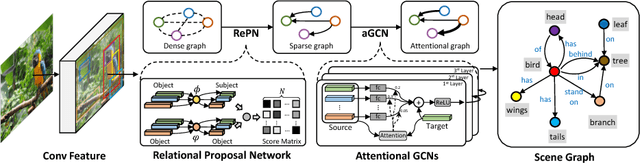
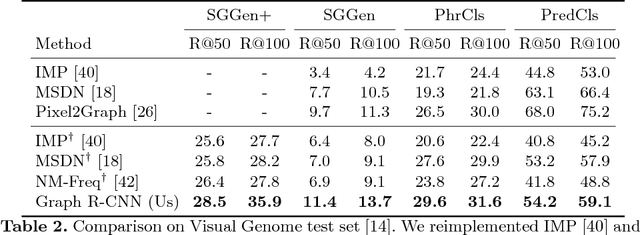
We propose a novel scene graph generation model called Graph R-CNN, that is both effective and efficient at detecting objects and their relations in images. Our model contains a Relation Proposal Network (RePN) that efficiently deals with the quadratic number of potential relations between objects in an image. We also propose an attentional Graph Convolutional Network (aGCN) that effectively captures contextual information between objects and relations. Finally, we introduce a new evaluation metric that is more holistic and realistic than existing metrics. We report state-of-the-art performance on scene graph generation as evaluated using both existing and our proposed metrics.
Pythia v0.1: the Winning Entry to the VQA Challenge 2018
Jul 27, 2018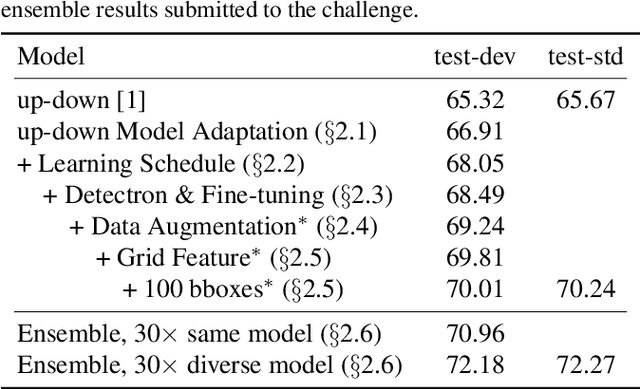
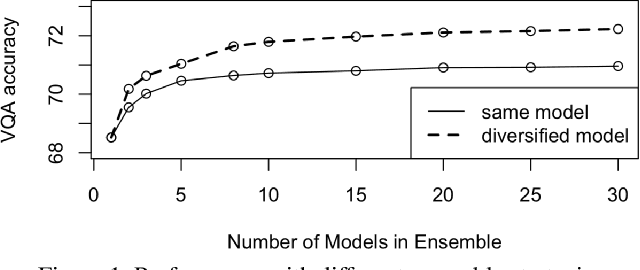
This document describes Pythia v0.1, the winning entry from Facebook AI Research (FAIR)'s A-STAR team to the VQA Challenge 2018. Our starting point is a modular re-implementation of the bottom-up top-down (up-down) model. We demonstrate that by making subtle but important changes to the model architecture and the learning rate schedule, fine-tuning image features, and adding data augmentation, we can significantly improve the performance of the up-down model on VQA v2.0 dataset -- from 65.67% to 70.22%. Furthermore, by using a diverse ensemble of models trained with different features and on different datasets, we are able to significantly improve over the 'standard' way of ensembling (i.e. same model with different random seeds) by 1.31%. Overall, we achieve 72.27% on the test-std split of the VQA v2.0 dataset. Our code in its entirety (training, evaluation, data-augmentation, ensembling) and pre-trained models are publicly available at: https://github.com/facebookresearch/pythia