 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescribe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach
Aug 10, 2020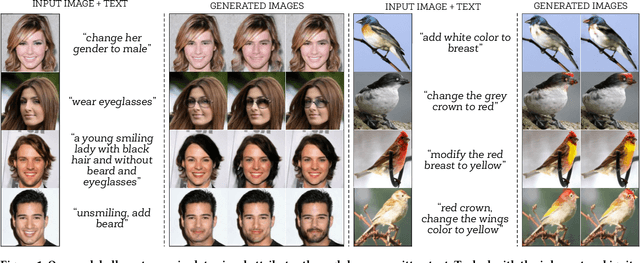
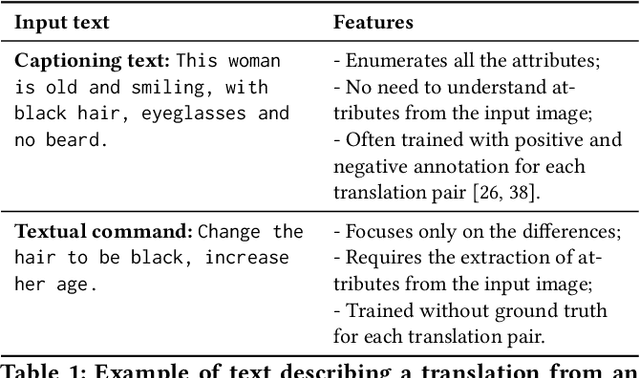
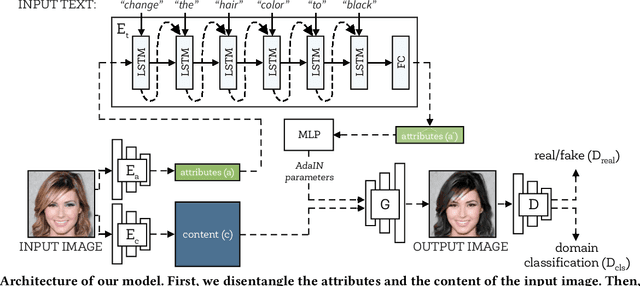

Manipulating visual attributes of images through human-written text is a very challenging task. On the one hand, models have to learn the manipulation without the ground truth of the desired output. On the other hand, models have to deal with the inherent ambiguity of natural language. Previous research usually requires either the user to describe all the characteristics of the desired image or to use richly-annotated image captioning datasets. In this work, we propose a novel unsupervised approach, based on image-to-image translation, that alters the attributes of a given image through a command-like sentence such as "change the hair color to black". Contrarily to state-of-the-art approaches, our model does not require a human-annotated dataset nor a textual description of all the attributes of the desired image, but only those that have to be modified. Our proposed model disentangles the image content from the visual attributes, and it learns to modify the latter using the textual description, before generating a new image from the content and the modified attribute representation. Because text might be inherently ambiguous (blond hair may refer to different shadows of blond, e.g. golden, icy, sandy), our method generates multiple stochastic versions of the same translation. Experiments show that the proposed model achieves promising performances on two large-scale public datasets: CelebA and CUB. We believe our approach will pave the way to new avenues of research combining textual and speech commands with visual attributes.
Stable Learning via Causality-based Feature Rectification
Jul 30, 2020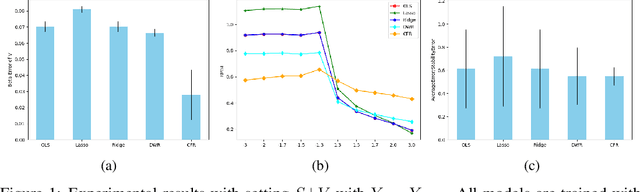
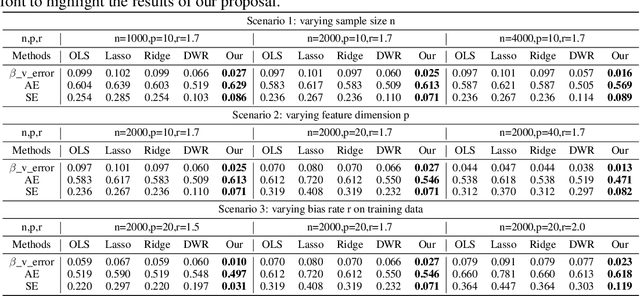
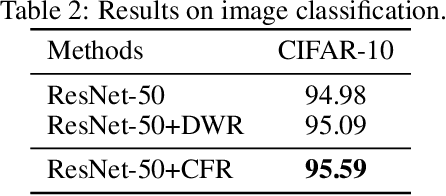
How to learn a stable model under agnostic distribution shift between training and testing datasets is an essential problem in machine learning tasks. The agnostic distribution shift caused by data generation bias can lead to model misspecification and unstable performance across different test datasets. Most of the recently proposed methods are causality-based sample reweighting methods, whose performance is affected by sample size. Moreover, these works are restricted to linear models, not to deep-learning based nonlinear models. In this work, we propose a novel Causality-based Feature Rectification (CFR) method to address the model misspecification problem under agnostic distribution shift by using a weight matrix to rectify features. Our proposal based on the fact that the causality between stable features and the ground truth is consistent under agnostic distribution shift, but is partly omitted and statistically correlated with other features. We propose the feature rectification weight matrix to reconstruct the omitted causality by using other features as proxy variables. We further propose an algorithm that jointly optimizes the weight matrix and the regressor (or classifier). Our proposal can not only improve the stability of linear models, but also deep-learning based models. Extensive experiments on both synthetic and real-world datasets demonstrate that our proposal outperforms previous state-of-the-art stable learning methods. The code will be released later on.
Adversarial Mutual Information for Text Generation
Jun 30, 2020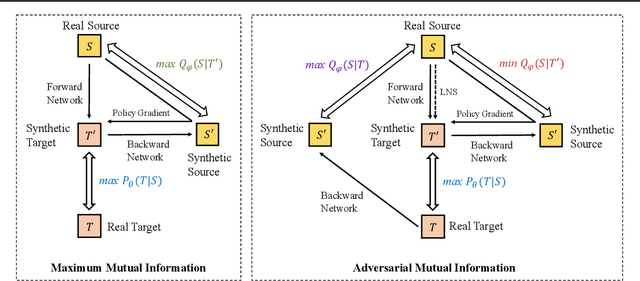
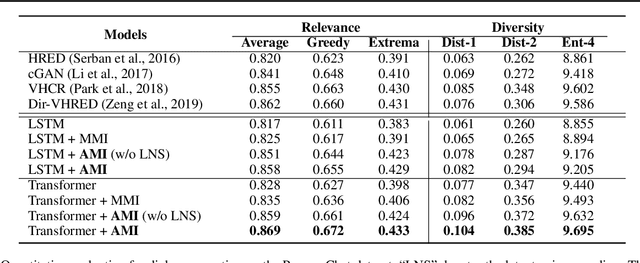

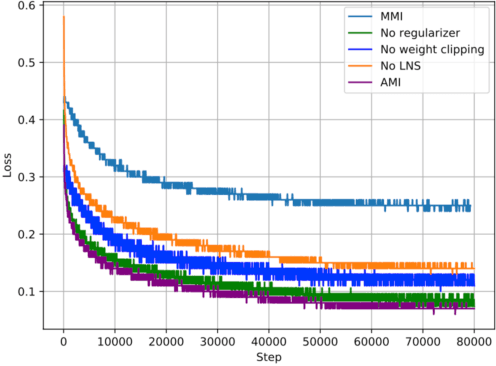
Recent advances in maximizing mutual information (MI) between the source and target have demonstrated its effectiveness in text generation. However, previous works paid little attention to modeling the backward network of MI (i.e., dependency from the target to the source), which is crucial to the tightness of the variational information maximization lower bound. In this paper, we propose Adversarial Mutual Information (AMI): a text generation framework which is formed as a novel saddle point (min-max) optimization aiming to identify joint interactions between the source and target. Within this framework, the forward and backward networks are able to iteratively promote or demote each other's generated instances by comparing the real and synthetic data distributions. We also develop a latent noise sampling strategy that leverages random variations at the high-level semantic space to enhance the long term dependency in the generation process. Extensive experiments based on different text generation tasks demonstrate that the proposed AMI framework can significantly outperform several strong baselines, and we also show that AMI has potential to lead to a tighter lower bound of maximum mutual information for the variational information maximization problem.
AMR Parsing via Graph-Sequence Iterative Inference
Apr 29, 2020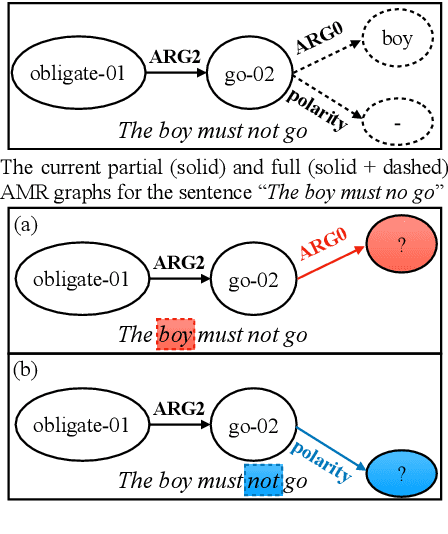
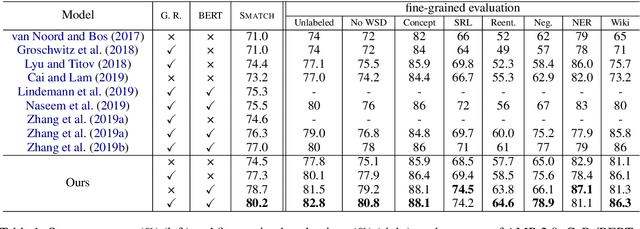
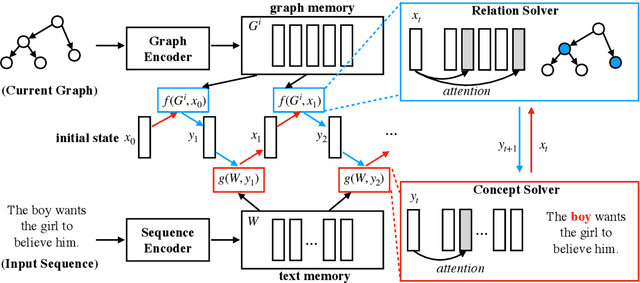
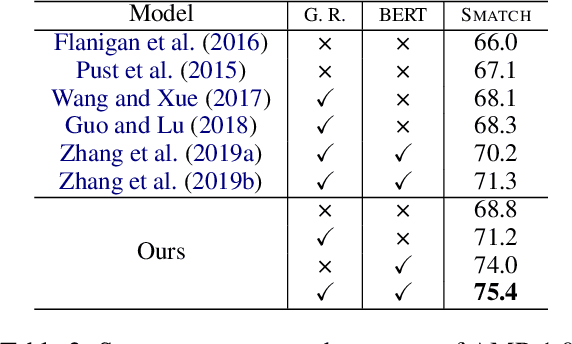
We propose a new end-to-end model that treats AMR parsing as a series of dual decisions on the input sequence and the incrementally constructed graph. At each time step, our model performs multiple rounds of attention, reasoning, and composition that aim to answer two critical questions: (1) which part of the input \textit{sequence} to abstract; and (2) where in the output \textit{graph} to construct the new concept. We show that the answers to these two questions are mutually causalities. We design a model based on iterative inference that helps achieve better answers in both perspectives, leading to greatly improved parsing accuracy. Our experimental results significantly outperform all previously reported \textsc{Smatch} scores by large margins. Remarkably, without the help of any large-scale pre-trained language model (e.g., BERT), our model already surpasses previous state-of-the-art using BERT. With the help of BERT, we can push the state-of-the-art results to 80.2\% on LDC2017T10 (AMR 2.0) and 75.4\% on LDC2014T12 (AMR 1.0).
Grayscale Data Construction and Multi-Level Ranking Objective for Dialogue Response Selection
Apr 28, 2020
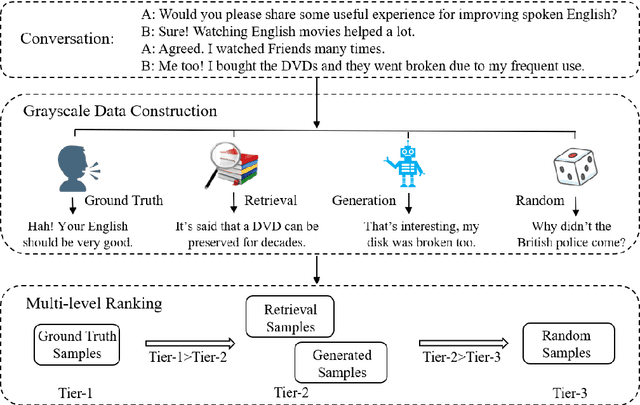
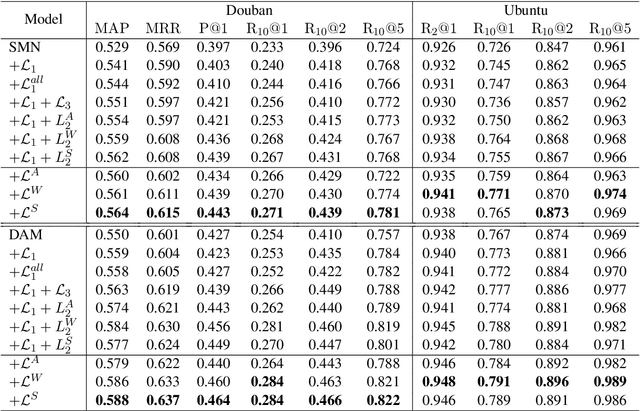
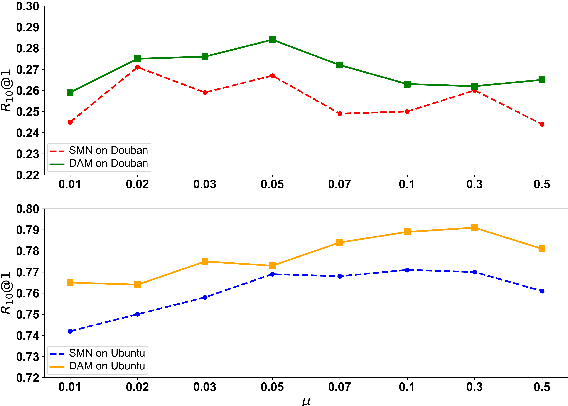
Response selection plays a vital role in building retrieval-based conversation systems. Recent works on enhancing response selection mainly focus on inventing new neural architectures for better modeling the relation between dialogue context and response candidates. In almost all these previous works, binary-labeled training data are assumed: Every response candidate is either positive (relevant) or negative (irrelevant). We propose to automatically build training data with grayscale labels. To make full use of the grayscale training data, we propose a multi-level ranking strategy. Experimental results on two benchmark datasets show that our new training strategy significantly improves performance over existing state-of-the-art matching models in terms of various evaluation metrics.
Prototype-to-Style: Dialogue Generation with Style-Aware Editing on Retrieval Memory
Apr 05, 2020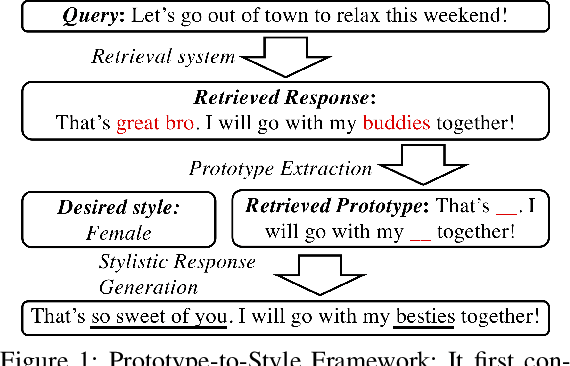
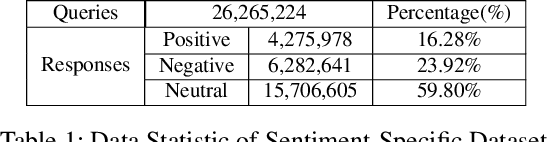

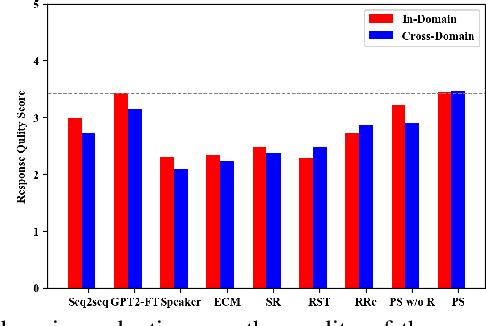
The ability of a dialog system to express prespecified language style during conversations has a direct, positive impact on its usability and on user satisfaction. We introduce a new prototype-to-style (PS) framework to tackle the challenge of stylistic dialogue generation. The framework uses an Information Retrieval (IR) system and extracts a response prototype from the retrieved response. A stylistic response generator then takes the prototype and the desired language style as model input to obtain a high-quality and stylistic response. To effectively train the proposed model, we propose a new style-aware learning objective as well as a de-noising learning strategy. Results on three benchmark datasets from two languages demonstrate that the proposed approach significantly outperforms existing baselines in both in-domain and cross-domain evaluations
Stylistic Dialogue Generation via Information-Guided Reinforcement Learning Strategy
Apr 05, 2020
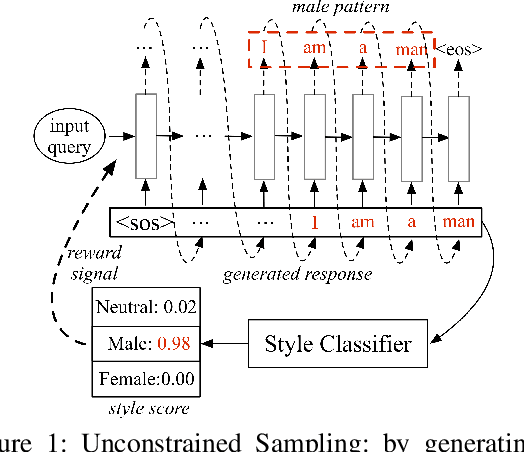
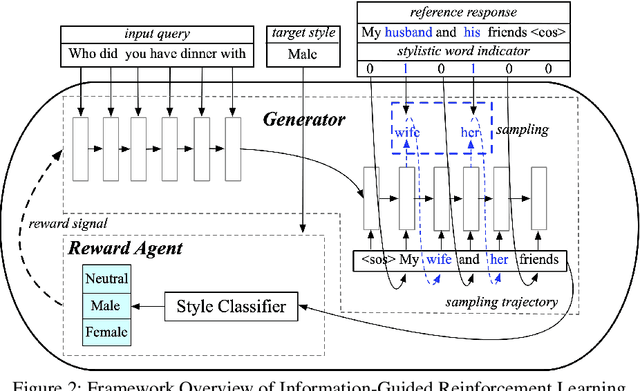
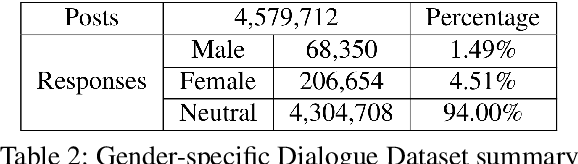
Stylistic response generation is crucial for building an engaging dialogue system for industrial use. While it has attracted much research interest, existing methods often generate stylistic responses at the cost of the content quality (relevance and fluency). To enable better balance between the content quality and the style, we introduce a new training strategy, know as Information-Guided Reinforcement Learning (IG-RL). In IG-RL, a training model is encouraged to explore stylistic expressions while being constrained to maintain its content quality. This is achieved by adopting reinforcement learning strategy with statistical style information guidance for quality-preserving explorations. Experiments on two datasets show that the proposed approach outperforms several strong baselines in terms of the overall response performance.
Boundary-Aware Dense Feature Indicator for Single-Stage 3D Object Detection from Point Clouds
Apr 01, 2020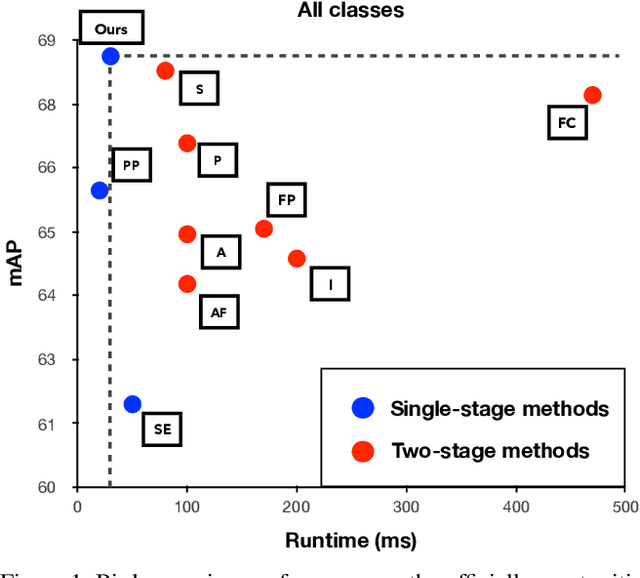

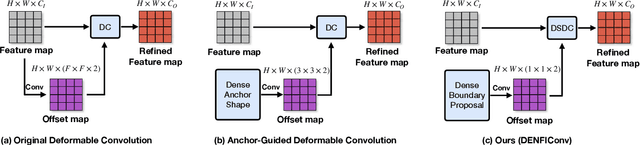
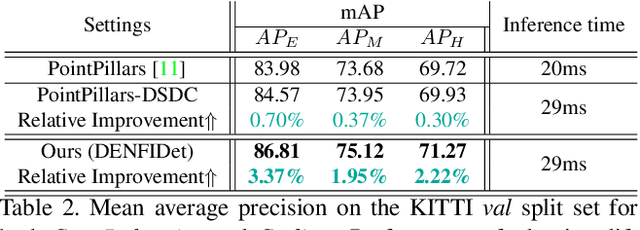
3D object detection based on point clouds has become more and more popular. Some methods propose localizing 3D objects directly from raw point clouds to avoid information loss. However, these methods come with complex structures and significant computational overhead, limiting its broader application in real-time scenarios. Some methods choose to transform the point cloud data into compact tensors first and leverage off-the-shelf 2D detectors to propose 3D objects, which is much faster and achieves state-of-the-art results. However, because of the inconsistency between 2D and 3D data, we argue that the performance of compact tensor-based 3D detectors is restricted if we use 2D detectors without corresponding modification. Specifically, the distribution of point clouds is uneven, with most points gather on the boundary of objects, while detectors for 2D data always extract features evenly. Motivated by this observation, we propose DENse Feature Indicator (DENFI), a universal module that helps 3D detectors focus on the densest region of the point clouds in a boundary-aware manner. Moreover, DENFI is lightweight and guarantees real-time speed when applied to 3D object detectors. Experiments on KITTI dataset show that DENFI improves the performance of the baseline single-stage detector remarkably, which achieves new state-of-the-art performance among previous 3D detectors, including both two-stage and multi-sensor fusion methods, in terms of mAP with a 34FPS detection speed.
Bi-Decoder Augmented Network for Neural Machine Translation
Jan 14, 2020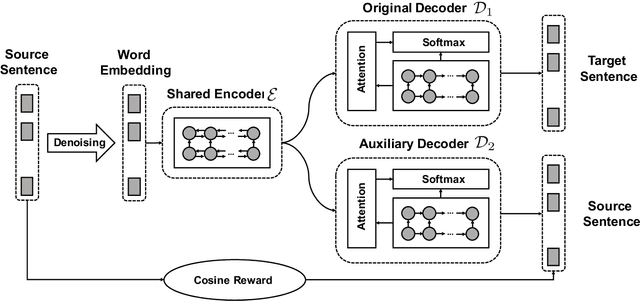
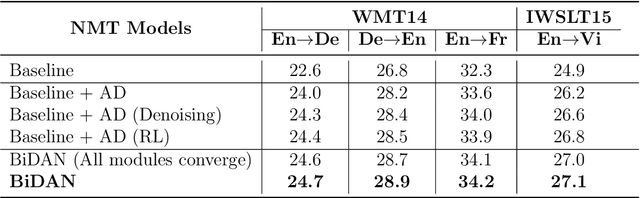
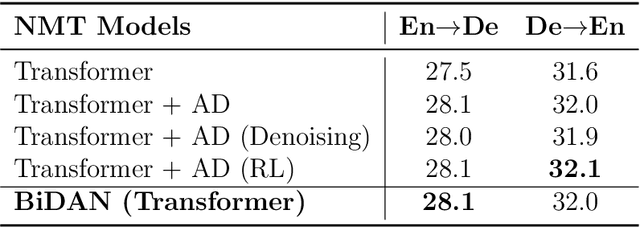
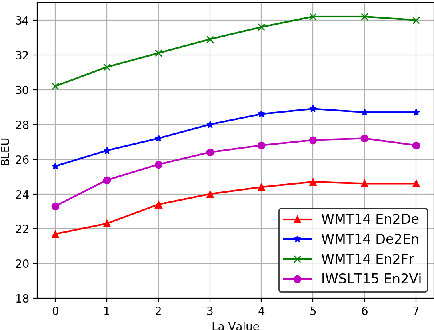
Neural Machine Translation (NMT) has become a popular technology in recent years, and the encoder-decoder framework is the mainstream among all the methods. It's obvious that the quality of the semantic representations from encoding is very crucial and can significantly affect the performance of the model. However, existing unidirectional source-to-target architectures may hardly produce a language-independent representation of the text because they rely heavily on the specific relations of the given language pairs. To alleviate this problem, in this paper, we propose a novel Bi-Decoder Augmented Network (BiDAN) for the neural machine translation task. Besides the original decoder which generates the target language sequence, we add an auxiliary decoder to generate back the source language sequence at the training time. Since each decoder transforms the representations of the input text into its corresponding language, jointly training with two target ends can make the shared encoder has the potential to produce a language-independent semantic space. We conduct extensive experiments on several NMT benchmark datasets and the results demonstrate the effectiveness of our proposed approach.
Adversarial-Learned Loss for Domain Adaptation
Jan 04, 2020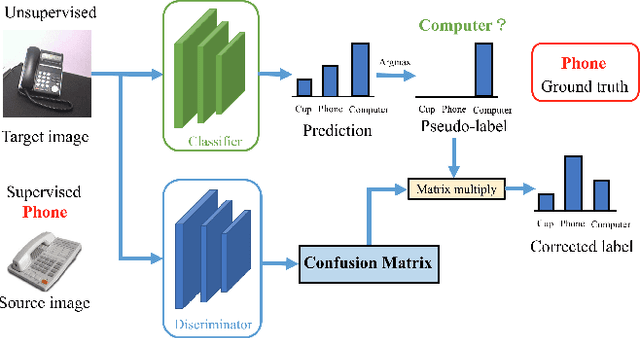
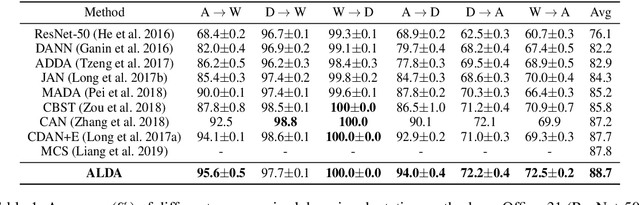
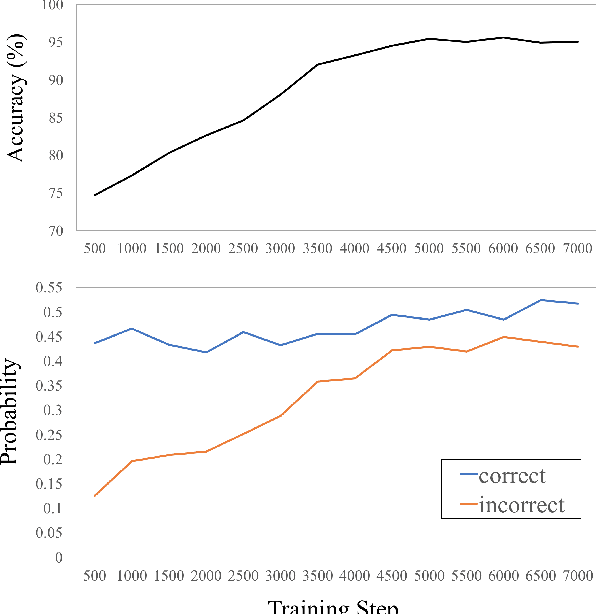
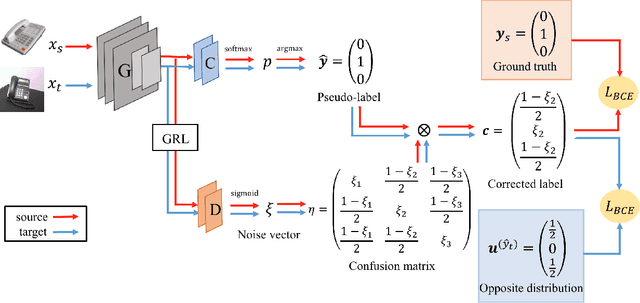
Recently, remarkable progress has been made in learning transferable representation across domains. Previous works in domain adaptation are majorly based on two techniques: domain-adversarial learning and self-training. However, domain-adversarial learning only aligns feature distributions between domains but does not consider whether the target features are discriminative. On the other hand, self-training utilizes the model predictions to enhance the discrimination of target features, but it is unable to explicitly align domain distributions. In order to combine the strengths of these two methods, we propose a novel method called Adversarial-Learned Loss for Domain Adaptation (ALDA). We first analyze the pseudo-label method, a typical self-training method. Nevertheless, there is a gap between pseudo-labels and the ground truth, which can cause incorrect training. Thus we introduce the confusion matrix, which is learned through an adversarial manner in ALDA, to reduce the gap and align the feature distributions. Finally, a new loss function is auto-constructed from the learned confusion matrix, which serves as the loss for unlabeled target samples. Our ALDA outperforms state-of-the-art approaches in four standard domain adaptation datasets. Our code is available at https://github.com/ZJULearning/ALDA.