 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-BFA: Targeted Bit-Flip Adversarial Weight Attack
Jul 24, 2020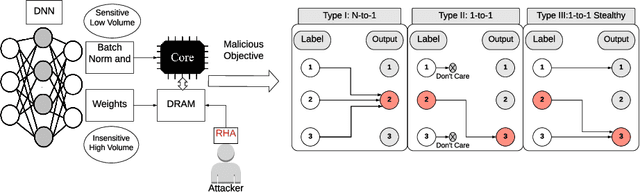

Deep Neural Network (DNN) attacks have mostly been conducted through adversarial input example generation. Recent work on adversarial attack of DNNweights, especially, Bit-Flip based adversarial weight Attack (BFA) has proved to be very powerful. BFA is an un-targeted attack that can classify all inputs into a random output class by flipping a very small number of weight bits stored in computer memory. This paper presents the first work on targeted adversarial weight attack for quantized DNN models. Specifically, we propose Targeted variants of BFA (T-BFA), which can intentionally mislead selected inputs to a target output class. The objective is achieved by identifying the weight bits that are highly associated with the classification of a targeted output through a novel class-dependant weight bit ranking algorithm. T-BFA performance has been successfully demonstrated on multiple network architectures for the image classification task. For example, by merely flipping 27 (out of 88 million) weight bits, T-BFA can misclassify all the images in Ibex class into Proboscis Monkey class (i.e., 100% attack success rate) on ImageNet dataset, while maintaining 59.35% validation accuracy on ResNet-18.
DeepHammer: Depleting the Intelligence of Deep Neural Networks through Targeted Chain of Bit Flips
Mar 30, 2020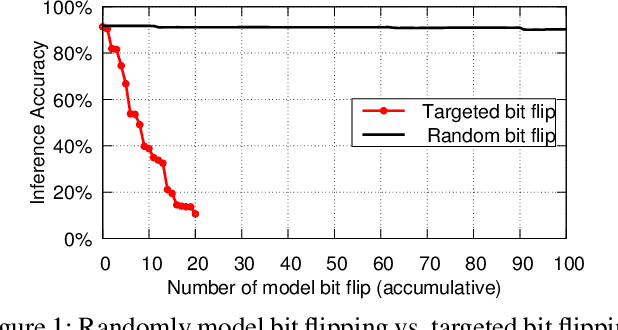
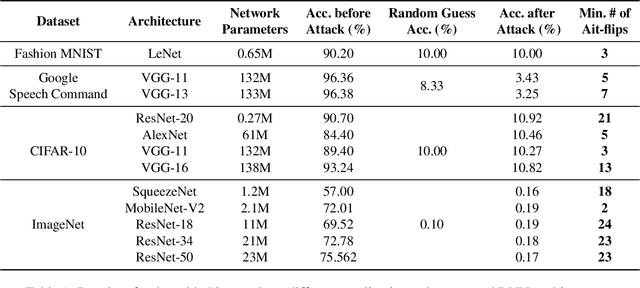
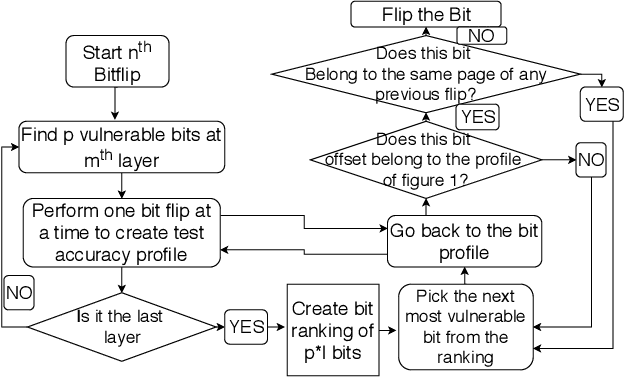

Security of machine learning is increasingly becoming a major concern due to the ubiquitous deployment of deep learning in many security-sensitive domains. Many prior studies have shown external attacks such as adversarial examples that tamper with the integrity of DNNs using maliciously crafted inputs. However, the security implication of internal threats (i.e., hardware vulnerability) to DNN models has not yet been well understood. In this paper, we demonstrate the first hardware-based attack on quantized deep neural networks-DeepHammer-that deterministically induces bit flips in model weights to compromise DNN inference by exploiting the rowhammer vulnerability. DeepHammer performs aggressive bit search in the DNN model to identify the most vulnerable weight bits that are flippable under system constraints. To trigger deterministic bit flips across multiple pages within reasonable amount of time, we develop novel system-level techniques that enable fast deployment of victim pages, memory-efficient rowhammering and precise flipping of targeted bits. DeepHammer can deliberately degrade the inference accuracy of the victim DNN system to a level that is only as good as random guess, thus completely depleting the intelligence of targeted DNN systems. We systematically demonstrate our attacks on real systems against 12 DNN architectures with 4 different datasets and different application domains. Our evaluation shows that DeepHammer is able to successfully tamper DNN inference behavior at run-time within a few minutes. We further discuss several mitigation techniques from both algorithm and system levels to protect DNNs against such attacks. Our work highlights the need to incorporate security mechanisms in future deep learning system to enhance the robustness of DNN against hardware-based deterministic fault injections.
Representable Matrices: Enabling High Accuracy Analog Computation for Inference of DNNs using Memristors
Nov 27, 2019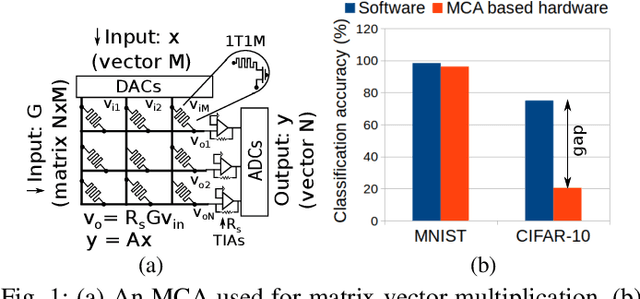
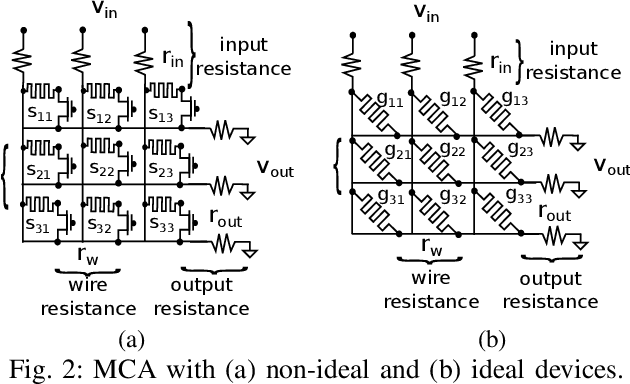
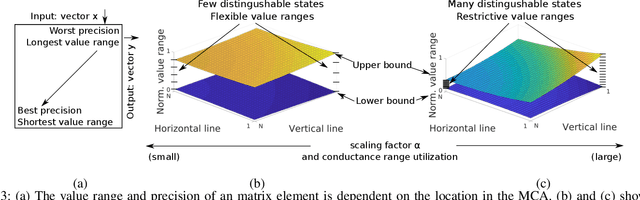
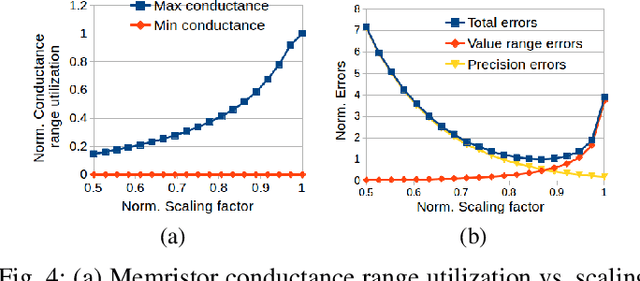
Analog computing based on memristor technology is a promising solution to accelerating the inference phase of deep neural networks (DNNs). A fundamental problem is to map an arbitrary matrix to a memristor crossbar array (MCA) while maximizing the resulting computational accuracy. The state-of-the-art mapping technique is based on a heuristic that only guarantees to produce the correct output for two input vectors. In this paper, a technique that aims to produce the correct output for every input vector is proposed, which involves specifying the memristor conductance values and a scaling factor realized by the peripheral circuitry. The key insight of the paper is that the conductance matrix realized by an MCA is only required to be proportional to the target matrix. The selection of the scaling factor between the two regulates the utilization of the programmable memristor conductance range and the representability of the target matrix. Consequently, the scaling factor is set to balance precision and value range errors. Moreover, a technique of converting conductance values into state variables and vice versa is proposed to handle memristors with non-ideal device characteristics. Compared with the state-of-the-art technique, the proposed mapping results in 4X-9X smaller errors. The improvements translate into that the classification accuracy of a seven-layer convolutional neural network (CNN) on CIFAR-10 is improved from 20.5% to 71.8%.
TBT: Targeted Neural Network Attack with Bit Trojan
Sep 10, 2019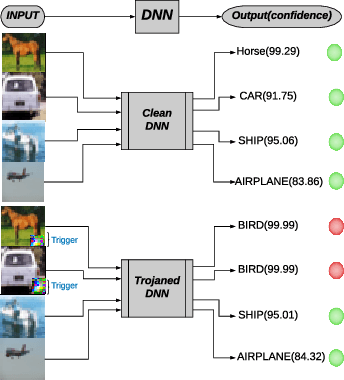
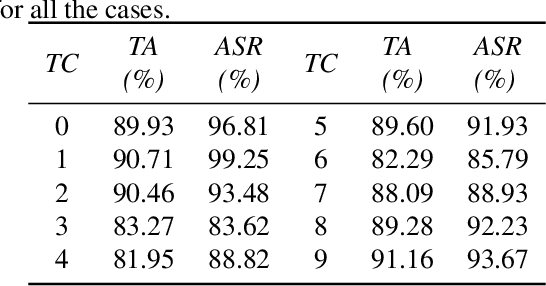
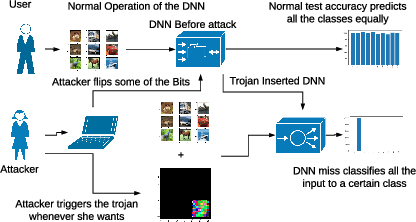
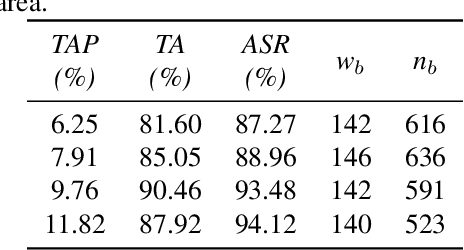
Security of modern Deep Neural Networks (DNNs) is under severe scrutiny as the deployment of these models become widespread in many intelligence-based applications. Most recently, DNNs are attacked through Trojan which can effectively infect the model during the training phase and get activated only through specific input patterns (i.e, trigger) during inference. However, in this work, for the first time, we propose a novel Targeted Bit Trojan(TBT), which eliminates the need for model re-training to insert the targeted Trojan. Our algorithm efficiently generates a trigger specifically designed to locate certain vulnerable bits of DNN weights stored in main memory (i.e., DRAM). The objective is that once the attacker flips these vulnerable bits, the network still operates with normal inference accuracy. However, when the attacker activates the trigger embedded with input images, the network classifies all the inputs to a certain target class. We demonstrate that flipping only several vulnerable bits founded by our method, using available bit-flip techniques (i.e, row-hammer), can transform a fully functional DNN model into a Trojan infected model. We perform extensive experiments of CIFAR-10, SVHN and ImageNet datasets on both VGG-16 and Resnet-18 architectures. Our proposed TBT could classify 93% of the test images to a target class with as little as 82 bit-flips out of 88 million weight bits on Resnet-18 for CIFAR10 dataset.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019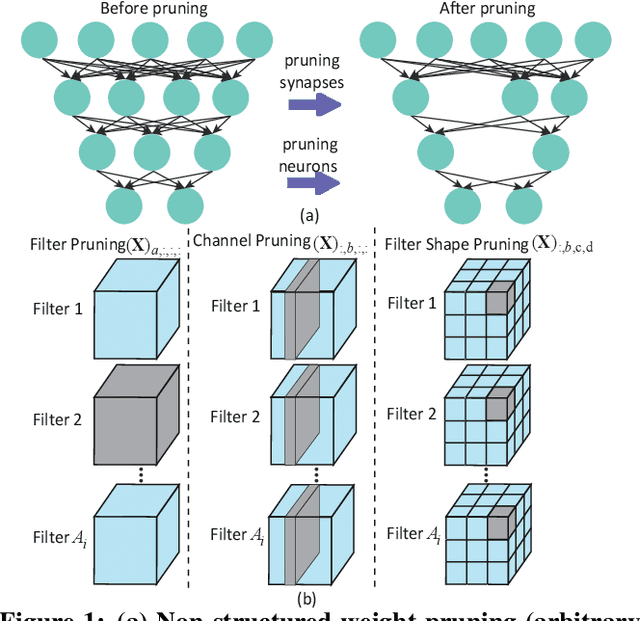
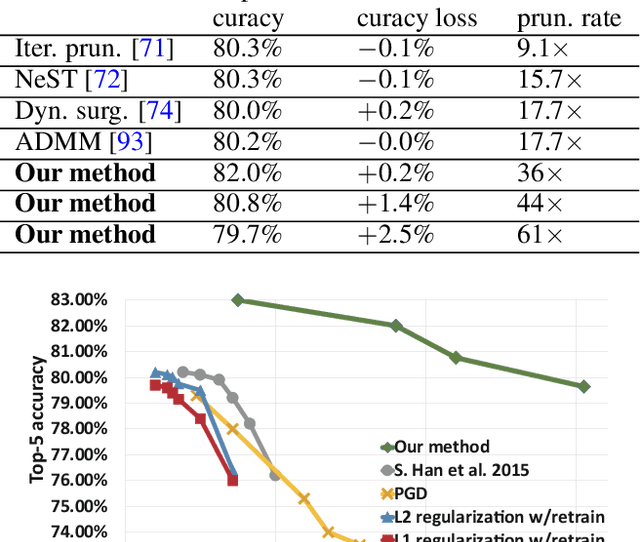
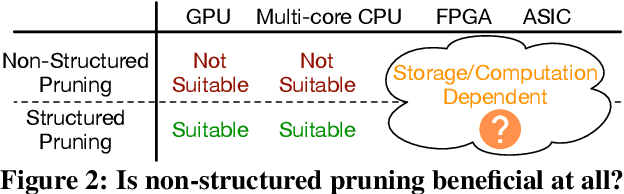
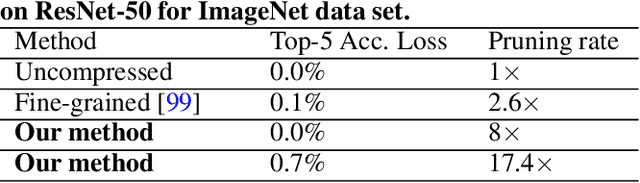
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
Defending Against Adversarial Attacks Using Random Forests
Jun 16, 2019



As deep neural networks (DNNs) have become increasingly important and popular, the robustness of DNNs is the key to the safety of both the Internet and the physical world. Unfortunately, some recent studies show that adversarial examples, which are hard to be distinguished from real examples, can easily fool DNNs and manipulate their predictions. Upon observing that adversarial examples are mostly generated by gradient-based methods, in this paper, we first propose to use a simple yet very effective non-differentiable hybrid model that combines DNNs and random forests, rather than hide gradients from attackers, to defend against the attacks. Our experiments show that our model can successfully and completely defend the white-box attacks, has a lower transferability, and is quite resistant to three representative types of black-box attacks; while at the same time, our model achieves similar classification accuracy as the original DNNs. Finally, we investigate and suggest a criterion to define where to grow random forests in DNNs.
Robust Sparse Regularization: Simultaneously Optimizing Neural Network Robustness and Compactness
May 30, 2019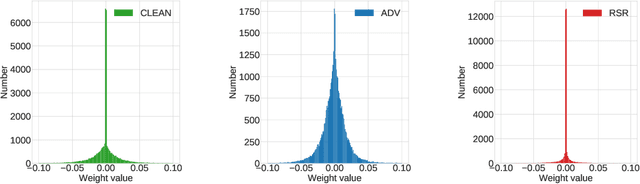
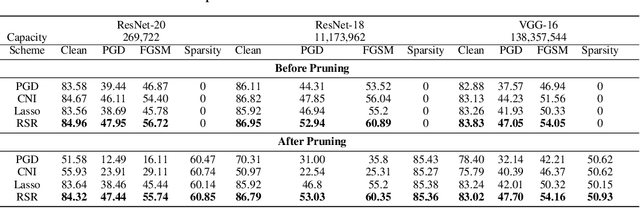
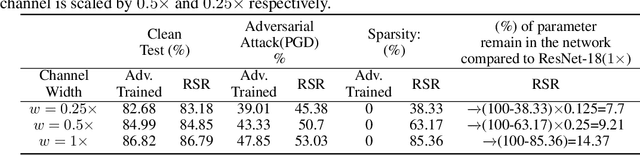
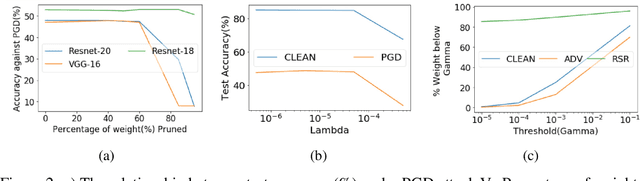
Deep Neural Network (DNN) trained by the gradient descent method is known to be vulnerable to maliciously perturbed adversarial input, aka. adversarial attack. As one of the countermeasures against adversarial attack, increasing the model capacity for DNN robustness enhancement was discussed and reported as an effective approach by many recent works. In this work, we show that shrinking the model size through proper weight pruning can even be helpful to improve the DNN robustness under adversarial attack. For obtaining a simultaneously robust and compact DNN model, we propose a multi-objective training method called Robust Sparse Regularization (RSR), through the fusion of various regularization techniques, including channel-wise noise injection, lasso weight penalty, and adversarial training. We conduct extensive experiments across popular ResNet-20, ResNet-18 and VGG-16 DNN architectures to demonstrate the effectiveness of RSR against popular white-box (i.e., PGD and FGSM) and black-box attacks. Thanks to RSR, 85% weight connections of ResNet-18 can be pruned while still achieving 0.68% and 8.72% improvement in clean- and perturbed-data accuracy respectively on CIFAR-10 dataset, in comparison to its PGD adversarial training baseline.
Processing-In-Memory Acceleration of Convolutional Neural Networks for Energy-Efficiency, and Power-Intermittency Resilience
Apr 16, 2019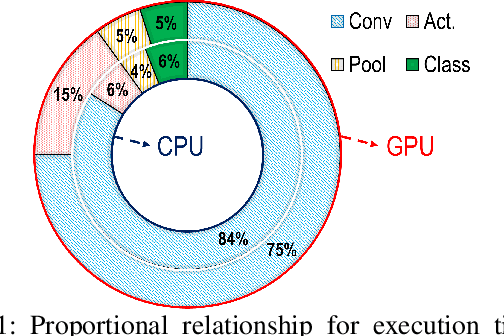
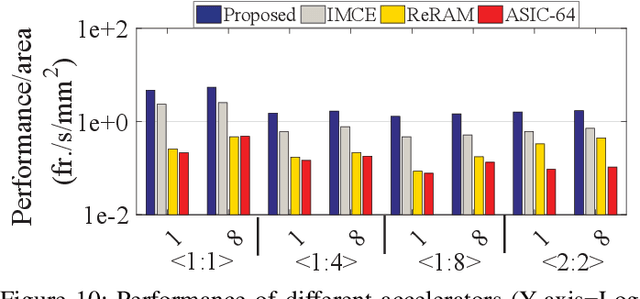
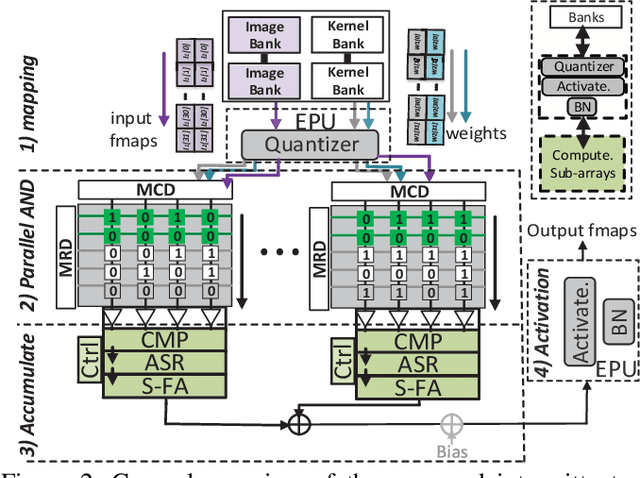
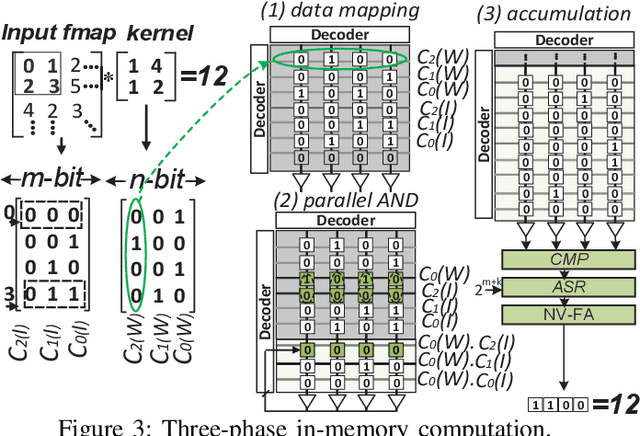
Herein, a bit-wise Convolutional Neural Network (CNN) in-memory accelerator is implemented using Spin-Orbit Torque Magnetic Random Access Memory (SOT-MRAM) computational sub-arrays. It utilizes a novel AND-Accumulation method capable of significantly-reduced energy consumption within convolutional layers and performs various low bit-width CNN inference operations entirely within MRAM. Power-intermittence resiliency is also enhanced by retaining the partial state information needed to maintain computational forward-progress, which is advantageous for battery-less IoT nodes. Simulation results indicate $\sim$5.4$\times$ higher energy-efficiency and 9$\times$ speedup over ReRAM-based acceleration, or roughly $\sim$9.7$\times$ higher energy-efficiency and 13.5$\times$ speedup over recent CMOS-only approaches, while maintaining inference accuracy comparable to baseline designs.
Bit-Flip Attack: Crushing Neural Network with Progressive Bit Search
Apr 07, 2019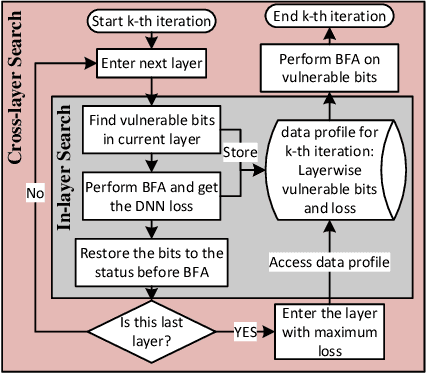
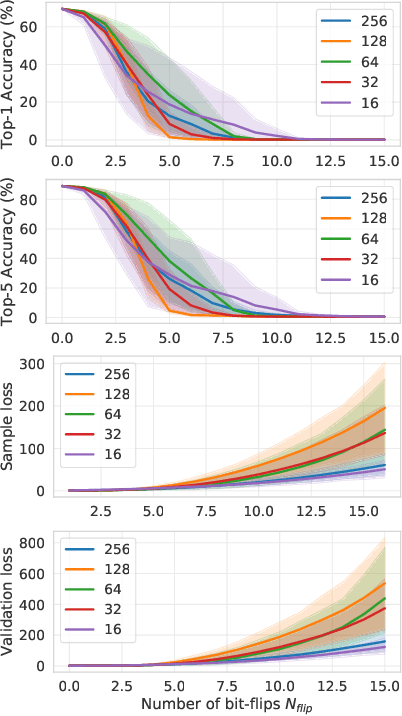
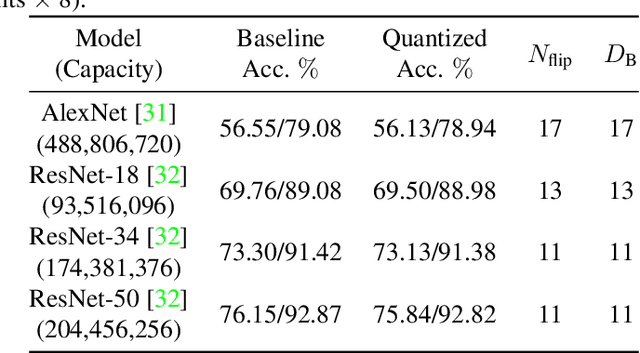
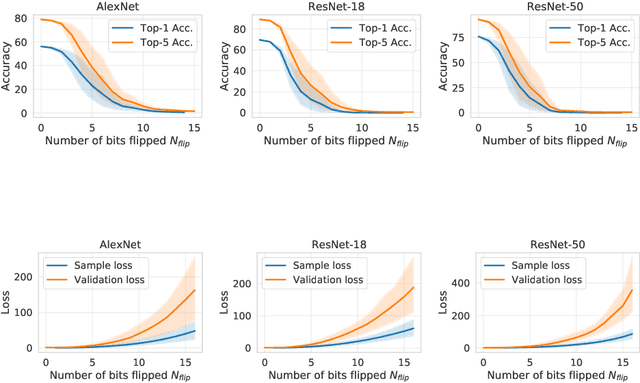
Several important security issues of Deep Neural Network (DNN) have been raised recently associated with different applications and components. The most widely investigated security concern of DNN is from its malicious input, a.k.a adversarial example. Nevertheless, the security challenge of DNN's parameters is not well explored yet. In this work, we are the first to propose a novel DNN weight attack methodology called Bit-Flip Attack (BFA) which can crush a neural network through maliciously flipping extremely small amount of bits within its weight storage memory system (i.e., DRAM). The bit-flip operations could be conducted through well-known Row-Hammer attack, while our main contribution is to develop an algorithm to identify the most vulnerable bits of DNN weight parameters (stored in memory as binary bits), that could maximize the accuracy degradation with a minimum number of bit-flips. Our proposed BFA utilizes a Progressive Bit Search (PBS) method which combines gradient ranking and progressive search to identify the most vulnerable bit to be flipped. With the aid of PBS, we can successfully attack a ResNet-18 fully malfunction (i.e., top-1 accuracy degrade from 69.8% to 0.1%) only through 13 bit-flips out of 93 million bits, while randomly flipping 100 bits merely degrades the accuracy by less than 1%.
Parametric Noise Injection: Trainable Randomness to Improve Deep Neural Network Robustness against Adversarial Attack
Nov 22, 2018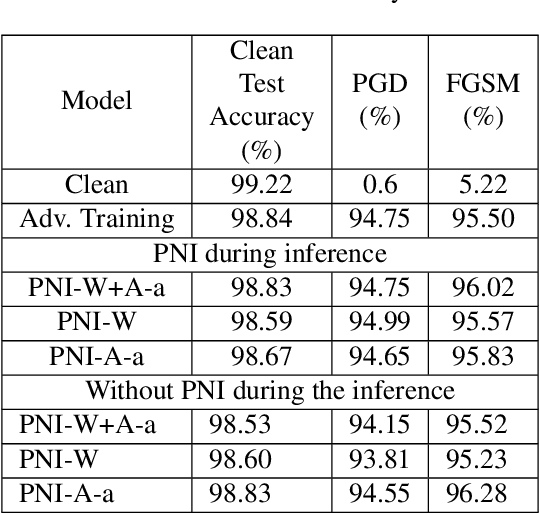
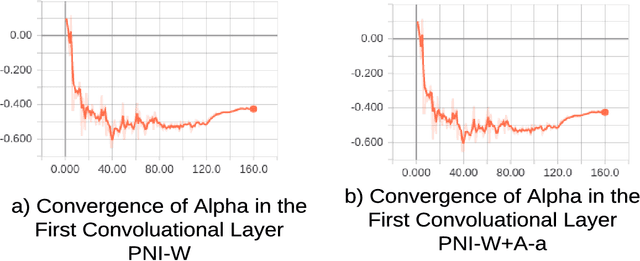
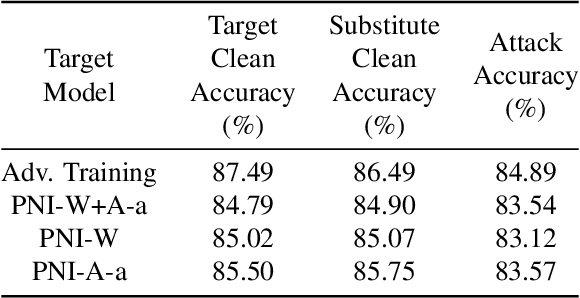
Recent development in the field of Deep Learning have exposed the underlying vulnerability of Deep Neural Network (DNN) against adversarial examples. In image classification, an adversarial example is a carefully modified image that is visually imperceptible to the original image but can cause DNN model to misclassify it. Training the network with Gaussian noise is an effective technique to perform model regularization, thus improving model robustness against input variation. Inspired by this classical method, we explore to utilize the regularization characteristic of noise injection to improve DNN's robustness against adversarial attack. In this work, we propose Parametric-Noise-Injection (PNI) which involves trainable Gaussian noise injection at each layer on either activation or weights through solving the min-max optimization problem, embedded with adversarial training. These parameters are trained explicitly to achieve improved robustness. To the best of our knowledge, this is the first work that uses trainable noise injection to improve network robustness against adversarial attacks, rather than manually configuring the injected noise level through cross-validation. The extensive results show that our proposed PNI technique effectively improves the robustness against a variety of powerful white-box and black-box attacks such as PGD, C & W, FGSM, transferable attack and ZOO attack. Last but not the least, PNI method improves both clean- and perturbed-data accuracy in comparison to the state-of-the-art defense methods, which outperforms current unbroken PGD defense by 1.1 % and 6.8 % on clean test data and perturbed test data respectively using Resnet-20 architecture.