 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep the Core: Adversarial Priors for Significance-Preserving Brain MRI Segmentation
Dec 17, 2025



Medical image segmentation is constrained by sparse pathological annotations. Existing augmentation strategies, from conventional transforms to random masking for self-supervision, are feature-agnostic: they often corrupt critical diagnostic semantics or fail to prioritize essential features. We introduce "Keep the Core," a novel data-centric paradigm that uses adversarial priors to guide both augmentation and masking in a significance-preserving manner. Our approach uses SAGE (Sparse Adversarial Gated Estimator), an offline module identifying minimal tokens whose micro-perturbation flips segmentation boundaries. SAGE forges the Token Importance Map $W$ by solving an adversarial optimization problem to maximally degrade performance, while an $\ell_1$ sparsity penalty encourages a compact set of sensitive tokens. The online KEEP (Key-region Enhancement \& Preservation) module uses $W$ for a two-pronged augmentation strategy: (1) Semantic-Preserving Augmentation: High-importance tokens are augmented, but their original pixel values are strictly restored. (2) Guided-Masking Augmentation: Low-importance tokens are selectively masked for an $\text{MAE}$-style reconstruction, forcing the model to learn robust representations from preserved critical features. "Keep the Core" is backbone-agnostic with no inference overhead. Extensive experiments show SAGE's structured priors and KEEP's region-selective mechanism are highly complementary, achieving state-of-the-art segmentation robustness and generalization on 2D medical datasets.
OAD-Promoter: Enhancing Zero-shot VQA using Large Language Models with Object Attribute Description
Nov 15, 2025Large Language Models (LLMs) have become a crucial tool in Visual Question Answering (VQA) for handling knowledge-intensive questions in few-shot or zero-shot scenarios. However, their reliance on massive training datasets often causes them to inherit language biases during the acquisition of knowledge. This limitation imposes two key constraints on existing methods: (1) LLM predictions become less reliable due to bias exploitation, and (2) despite strong knowledge reasoning capabilities, LLMs still struggle with out-of-distribution (OOD) generalization. To address these issues, we propose Object Attribute Description Promoter (OAD-Promoter), a novel approach for enhancing LLM-based VQA by mitigating language bias and improving domain-shift robustness. OAD-Promoter comprises three components: the Object-concentrated Example Generation (OEG) module, the Memory Knowledge Assistance (MKA) module, and the OAD Prompt. The OEG module generates global captions and object-concentrated samples, jointly enhancing visual information input to the LLM and mitigating bias through complementary global and regional visual cues. The MKA module assists the LLM in handling OOD samples by retrieving relevant knowledge from stored examples to support questions from unseen domains. Finally, the OAD Prompt integrates the outputs of the preceding modules to optimize LLM inference. Experiments demonstrate that OAD-Promoter significantly improves the performance of LLM-based VQA methods in few-shot or zero-shot settings, achieving new state-of-the-art results.
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Aug 24, 2025Recent advancements in Large Language Models (LLMs) have leveraged increased test-time computation to enhance reasoning capabilities, a strategy that, while effective, incurs significant latency and resource costs, limiting their applicability in real-world time-constrained or cost-sensitive scenarios. This paper introduces BudgetThinker, a novel framework designed to empower LLMs with budget-aware reasoning, enabling precise control over the length of their thought processes. We propose a methodology that periodically inserts special control tokens during inference to continuously inform the model of its remaining token budget. This approach is coupled with a comprehensive two-stage training pipeline, beginning with Supervised Fine-Tuning (SFT) to familiarize the model with budget constraints, followed by a curriculum-based Reinforcement Learning (RL) phase that utilizes a length-aware reward function to optimize for both accuracy and budget adherence. We demonstrate that BudgetThinker significantly surpasses strong baselines in maintaining performance across a variety of reasoning budgets on challenging mathematical benchmarks. Our method provides a scalable and effective solution for developing efficient and controllable LLM reasoning, making advanced models more practical for deployment in resource-constrained and real-time environments.
QIRL: Boosting Visual Question Answering via Optimized Question-Image Relation Learning
Apr 04, 2025Existing debiasing approaches in Visual Question Answering (VQA) primarily focus on enhancing visual learning, integrating auxiliary models, or employing data augmentation strategies. However, these methods exhibit two major drawbacks. First, current debiasing techniques fail to capture the superior relation between images and texts because prevalent learning frameworks do not enable models to extract deeper correlations from highly contrasting samples. Second, they do not assess the relevance between the input question and image during inference, as no prior work has examined the degree of input relevance in debiasing studies. Motivated by these limitations, we propose a novel framework, Optimized Question-Image Relation Learning (QIRL), which employs a generation-based self-supervised learning strategy. Specifically, two modules are introduced to address the aforementioned issues. The Negative Image Generation (NIG) module automatically produces highly irrelevant question-image pairs during training to enhance correlation learning, while the Irrelevant Sample Identification (ISI) module improves model robustness by detecting and filtering irrelevant inputs, thereby reducing prediction errors. Furthermore, to validate our concept of reducing output errors through filtering unrelated question-image inputs, we propose a specialized metric to evaluate the performance of the ISI module. Notably, our approach is model-agnostic and can be integrated with various VQA models. Extensive experiments on VQA-CPv2 and VQA-v2 demonstrate the effectiveness and generalization ability of our method. Among data augmentation strategies, our approach achieves state-of-the-art results.
Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition
Jan 13, 2021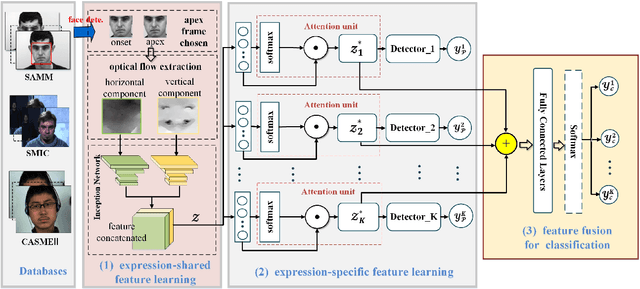

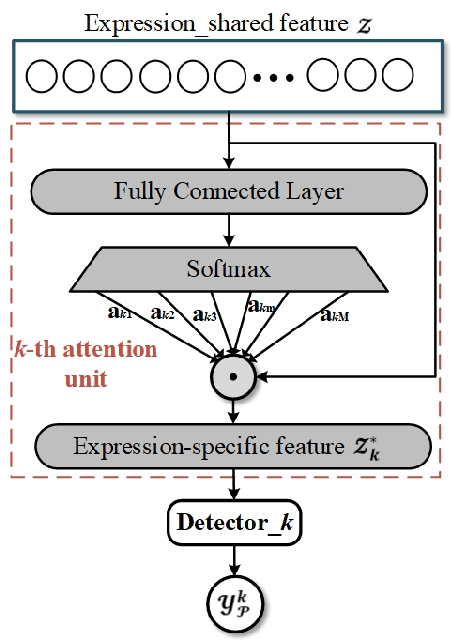
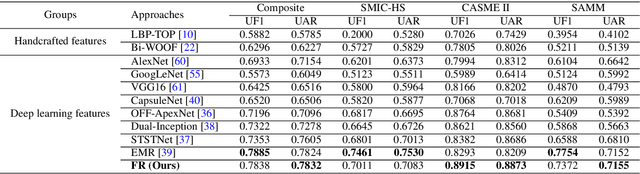
Micro-Expression Recognition has become challenging, as it is extremely difficult to extract the subtle facial changes of micro-expressions. Recently, several approaches proposed several expression-shared features algorithms for micro-expression recognition. However, they do not reveal the specific discriminative characteristics, which lead to sub-optimal performance. This paper proposes a novel Feature Refinement ({FR}) with expression-specific feature learning and fusion for micro-expression recognition. It aims to obtain salient and discriminative features for specific expressions and also predict expression by fusing the expression-specific features. FR consists of an expression proposal module with attention mechanism and a classification branch. First, an inception module is designed based on optical flow to obtain expression-shared features. Second, in order to extract salient and discriminative features for specific expression, expression-shared features are fed into an expression proposal module with attention factors and proposal loss. Last, in the classification branch, labels of categories are predicted by a fusion of the expression-specific features. Experiments on three publicly available databases validate the effectiveness of FR under different protocol. Results on public benchmarks demonstrate that our FR provides salient and discriminative information for micro-expression recognition. The results also show our FR achieves better or competitive performance with the existing state-of-the-art methods on micro-expression recognition.