 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClimbing the Ladder of Reasoning: What LLMs Can-and Still Can't-Solve after SFT?
Apr 16, 2025



Recent supervised fine-tuning (SFT) approaches have significantly improved language models' performance on mathematical reasoning tasks, even when models are trained at a small scale. However, the specific capabilities enhanced through such fine-tuning remain poorly understood. In this paper, we conduct a detailed analysis of model performance on the AIME24 dataset to understand how reasoning capabilities evolve. We discover a ladder-like structure in problem difficulty, categorize questions into four tiers (Easy, Medium, Hard, and Extremely Hard (Exh)), and identify the specific requirements for advancing between tiers. We find that progression from Easy to Medium tier requires adopting an R1 reasoning style with minimal SFT (500-1K instances), while Hard-level questions suffer from frequent model's errors at each step of the reasoning chain, with accuracy plateauing at around 65% despite logarithmic scaling. Exh-level questions present a fundamentally different challenge; they require unconventional problem-solving skills that current models uniformly struggle with. Additional findings reveal that carefully curated small-scale datasets offer limited advantage-scaling dataset size proves far more effective. Our analysis provides a clearer roadmap for advancing language model capabilities in mathematical reasoning.
Progent: Programmable Privilege Control for LLM Agents
Apr 16, 2025



LLM agents are an emerging form of AI systems where large language models (LLMs) serve as the central component, utilizing a diverse set of tools to complete user-assigned tasks. Despite their great potential, LLM agents pose significant security risks. When interacting with the external world, they may encounter malicious commands from attackers, leading to the execution of dangerous actions. A promising way to address this is by enforcing the principle of least privilege: allowing only essential actions for task completion while blocking unnecessary ones. However, achieving this is challenging, as it requires covering diverse agent scenarios while preserving both security and utility. We introduce Progent, the first privilege control mechanism for LLM agents. At its core is a domain-specific language for flexibly expressing privilege control policies applied during agent execution. These policies provide fine-grained constraints over tool calls, deciding when tool calls are permissible and specifying fallbacks if they are not. This enables agent developers and users to craft suitable policies for their specific use cases and enforce them deterministically to guarantee security. Thanks to its modular design, integrating Progent does not alter agent internals and requires only minimal changes to agent implementation, enhancing its practicality and potential for widespread adoption. To automate policy writing, we leverage LLMs to generate policies based on user queries, which are then updated dynamically for improved security and utility. Our extensive evaluation shows that it enables strong security while preserving high utility across three distinct scenarios or benchmarks: AgentDojo, ASB, and AgentPoison. Furthermore, we perform an in-depth analysis, showcasing the effectiveness of its core components and the resilience of its automated policy generation against adaptive attacks.
DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks
Apr 15, 2025LLM-integrated applications and agents are vulnerable to prompt injection attacks, where an attacker injects prompts into their inputs to induce attacker-desired outputs. A detection method aims to determine whether a given input is contaminated by an injected prompt. However, existing detection methods have limited effectiveness against state-of-the-art attacks, let alone adaptive ones. In this work, we propose DataSentinel, a game-theoretic method to detect prompt injection attacks. Specifically, DataSentinel fine-tunes an LLM to detect inputs contaminated with injected prompts that are strategically adapted to evade detection. We formulate this as a minimax optimization problem, with the objective of fine-tuning the LLM to detect strong adaptive attacks. Furthermore, we propose a gradient-based method to solve the minimax optimization problem by alternating between the inner max and outer min problems. Our evaluation results on multiple benchmark datasets and LLMs show that DataSentinel effectively detects both existing and adaptive prompt injection attacks.
Assessing Judging Bias in Large Reasoning Models: An Empirical Study
Apr 14, 2025



Large Reasoning Models (LRMs) like DeepSeek-R1 and OpenAI-o1 have demonstrated remarkable reasoning capabilities, raising important questions about their biases in LLM-as-a-judge settings. We present a comprehensive benchmark comparing judging biases between LLMs and LRMs across both subjective preference-alignment datasets and objective fact-based datasets. Through investigation of bandwagon, authority, position, and distraction biases, we uncover four key findings: (1) despite their advanced reasoning capabilities, LRMs remain susceptible to the above biases; (2) LRMs demonstrate better robustness than LLMs specifically on fact-related datasets; (3) LRMs exhibit notable position bias, preferring options in later positions; and (4) we identify a novel "superficial reflection bias" where phrases mimicking reasoning (e.g., "wait, let me think...") significantly influence model judgments. To address these biases, we design and evaluate three mitigation strategies: specialized system prompts that reduce judging biases by up to 19\% in preference alignment datasets and 14\% in fact-related datasets, in-context learning that provides up to 27\% improvement on preference tasks but shows inconsistent results on factual tasks, and a self-reflection mechanism that reduces biases by up to 10\% in preference datasets and 16\% in fact-related datasets, with self-reflection proving particularly effective for LRMs. Our work provides crucial insights for developing more reliable LLM-as-a-Judge frameworks, especially as LRMs become increasingly deployed as automated judges.
Type-Constrained Code Generation with Language Models
Apr 12, 2025



Large language models (LLMs) have achieved notable success in code generation. However, they still frequently produce uncompilable output because their next-token inference procedure does not model formal aspects of code. Although constrained decoding is a promising approach to alleviate this issue, it has only been applied to handle either domain-specific languages or syntactic language features. This leaves typing errors, which are beyond the domain of syntax and generally hard to adequately constrain. To address this challenge, we introduce a type-constrained decoding approach that leverages type systems to guide code generation. We develop novel prefix automata for this purpose and introduce a sound approach to enforce well-typedness based on type inference and a search over inhabitable types. We formalize our approach on a simply-typed language and extend it to TypeScript to demonstrate practicality. Our evaluation on HumanEval shows that our approach reduces compilation errors by more than half and increases functional correctness in code synthesis, translation, and repair tasks across LLMs of various sizes and model families, including SOTA open-weight models with more than 30B parameters.
Are You Getting What You Pay For? Auditing Model Substitution in LLM APIs
Apr 07, 2025



The proliferation of Large Language Models (LLMs) accessed via black-box APIs introduces a significant trust challenge: users pay for services based on advertised model capabilities (e.g., size, performance), but providers may covertly substitute the specified model with a cheaper, lower-quality alternative to reduce operational costs. This lack of transparency undermines fairness, erodes trust, and complicates reliable benchmarking. Detecting such substitutions is difficult due to the black-box nature, typically limiting interaction to input-output queries. This paper formalizes the problem of model substitution detection in LLM APIs. We systematically evaluate existing verification techniques, including output-based statistical tests, benchmark evaluations, and log probability analysis, under various realistic attack scenarios like model quantization, randomized substitution, and benchmark evasion. Our findings reveal the limitations of methods relying solely on text outputs, especially against subtle or adaptive attacks. While log probability analysis offers stronger guarantees when available, its accessibility is often limited. We conclude by discussing the potential of hardware-based solutions like Trusted Execution Environments (TEEs) as a pathway towards provable model integrity, highlighting the trade-offs between security, performance, and provider adoption. Code is available at https://github.com/sunblaze-ucb/llm-api-audit
SoK: Frontier AI's Impact on the Cybersecurity Landscape
Apr 07, 2025



As frontier AI advances rapidly, understanding its impact on cybersecurity and inherent risks is essential to ensuring safe AI evolution (e.g., guiding risk mitigation and informing policymakers). While some studies review AI applications in cybersecurity, none of them comprehensively discuss AI's future impacts or provide concrete recommendations for navigating its safe and secure usage. This paper presents an in-depth analysis of frontier AI's impact on cybersecurity and establishes a systematic framework for risk assessment and mitigation. To this end, we first define and categorize the marginal risks of frontier AI in cybersecurity and then systemically analyze the current and future impacts of frontier AI in cybersecurity, qualitatively and quantitatively. We also discuss why frontier AI likely benefits attackers more than defenders in the short term from equivalence classes, asymmetry, and economic impact. Next, we explore frontier AI's impact on future software system development, including enabling complex hybrid systems while introducing new risks. Based on our findings, we provide security recommendations, including constructing fine-grained benchmarks for risk assessment, designing AI agents for defenses, building security mechanisms and provable defenses for hybrid systems, enhancing pre-deployment security testing and transparency, and strengthening defenses for users. Finally, we present long-term research questions essential for understanding AI's future impacts and unleashing its defensive capabilities.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
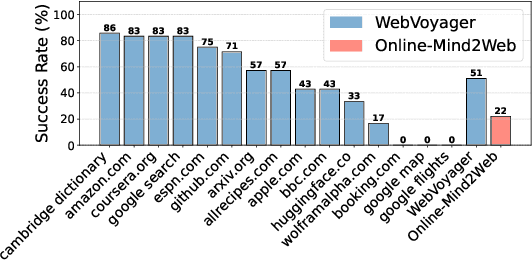

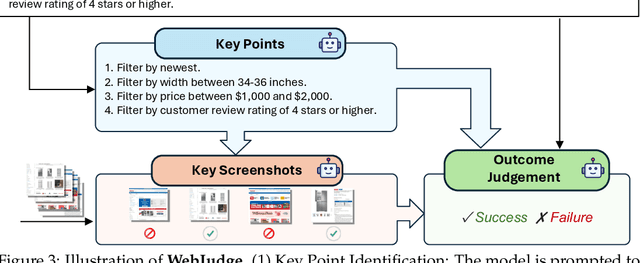
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
Improving LLM Safety Alignment with Dual-Objective Optimization
Mar 05, 2025



Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment