 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Teachers Can Be Dense with Knowledge
Oct 08, 2022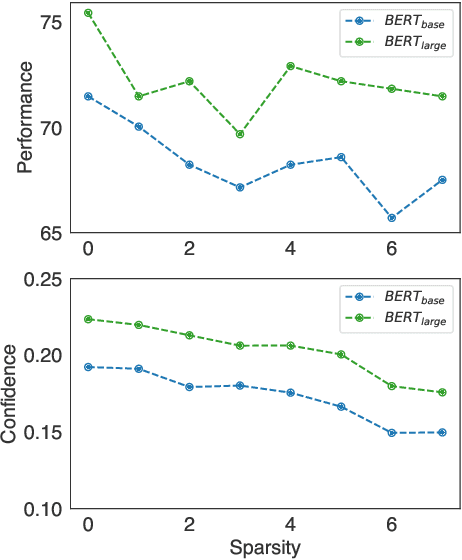
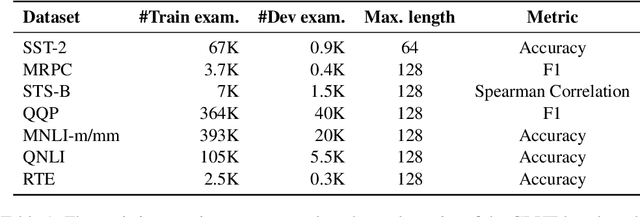
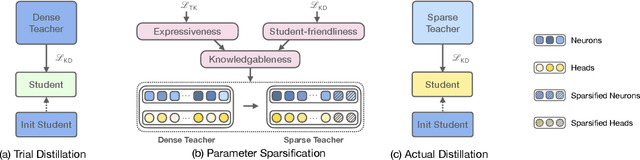
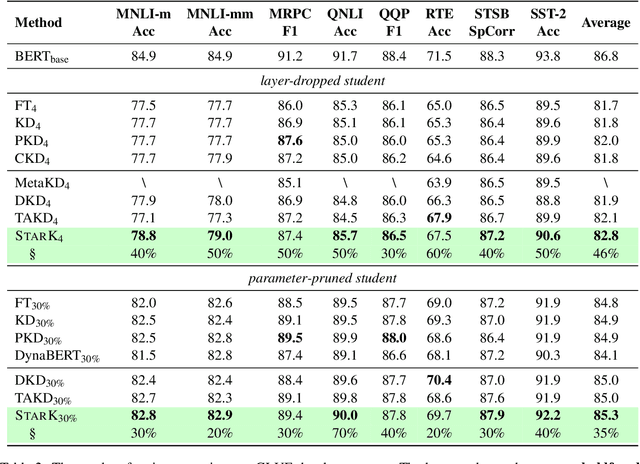
Recent advances in distilling pretrained language models have discovered that, besides the expressiveness of knowledge, the student-friendliness should be taken into consideration to realize a truly knowledgable teacher. Based on a pilot study, we find that over-parameterized teachers can produce expressive yet student-unfriendly knowledge, and are thus limited in overall knowledgableness. To remove the parameters that result in student-unfriendliness, we propose a sparse teacher trick under the guidance of an overall knowledgable score for each teacher parameter. The knowledgable score is essentially an interpolation of the expressiveness and student-friendliness scores. The aim is to ensure that the expressive parameters are retained while the student-unfriendly ones are removed. Extensive experiments on the GLUE benchmark show that the proposed sparse teachers can be dense with knowledge and lead to students with compelling performance in comparison with a series of competitive baselines.
Structural Bias for Aspect Sentiment Triplet Extraction
Sep 02, 2022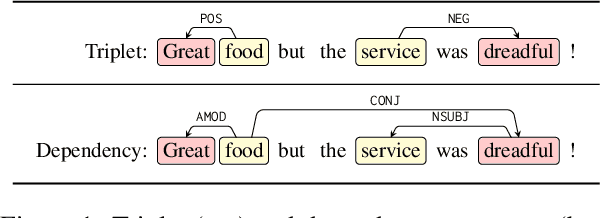
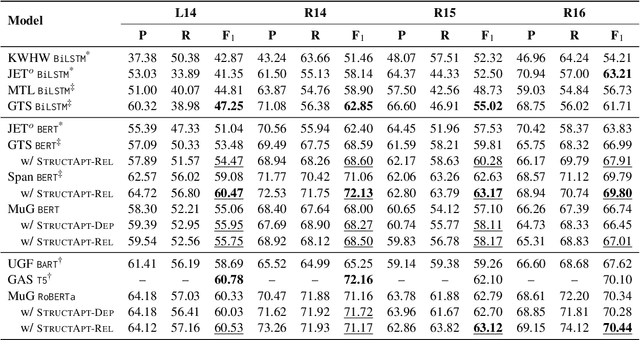
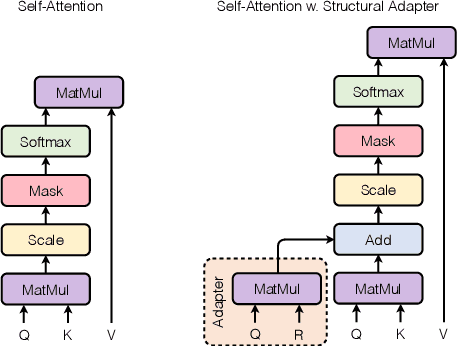
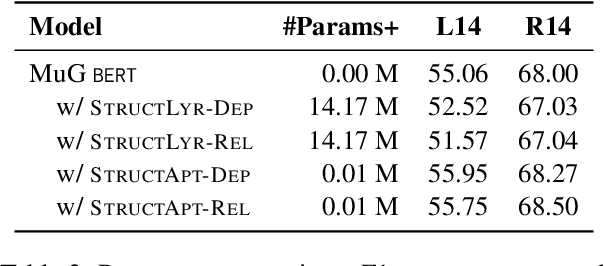
Structural bias has recently been exploited for aspect sentiment triplet extraction (ASTE) and led to improved performance. On the other hand, it is recognized that explicitly incorporating structural bias would have a negative impact on efficiency, whereas pretrained language models (PLMs) can already capture implicit structures. Thus, a natural question arises: Is structural bias still a necessity in the context of PLMs? To answer the question, we propose to address the efficiency issues by using an adapter to integrate structural bias in the PLM and using a cheap-to-compute relative position structure in place of the syntactic dependency structure. Benchmarking evaluation is conducted on the SemEval datasets. The results show that our proposed structural adapter is beneficial to PLMs and achieves state-of-the-art performance over a range of strong baselines, yet with a light parameter demand and low latency. Meanwhile, we give rise to the concern that the current evaluation default with data of small scale is under-confident. Consequently, we release a large-scale dataset for ASTE. The results on the new dataset hint that the structural adapter is confidently effective and efficient to a large scale. Overall, we draw the conclusion that structural bias shall still be a necessity even with PLMs.
Doge Tickets: Uncovering Domain-general Language Models by Playing Lottery Tickets
Jul 20, 2022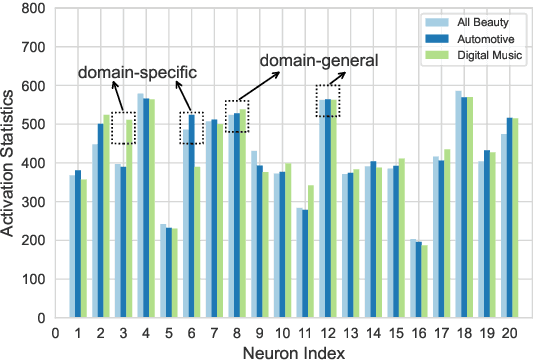
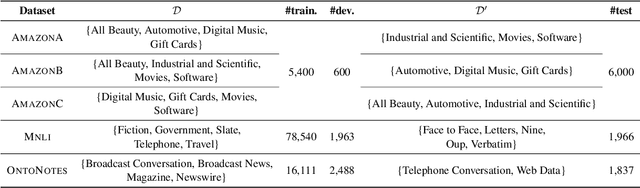
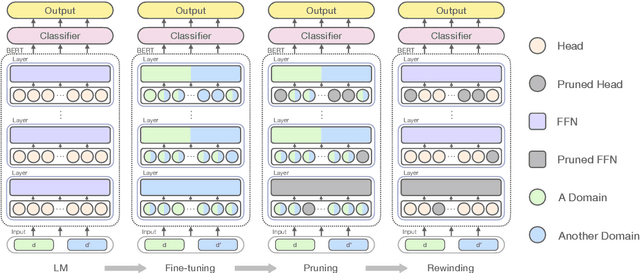
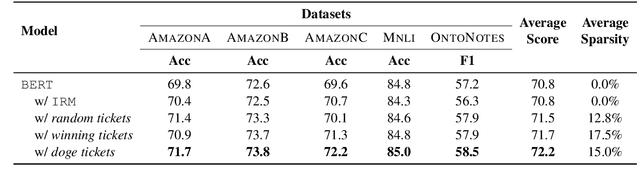
Over-parameterized models, typically pre-trained language models (LMs), have shown an appealing expressive power due to their small learning bias. However, the huge learning capacity of LMs can also lead to large learning variance. In a pilot study, we find that, when faced with multiple domains, a critical portion of parameters behave unexpectedly in a domain-specific manner while others behave in a domain-general one. Motivated by this phenomenon, we for the first time posit that domain-general parameters can underpin a domain-general LM that can be derived from the original LM. To uncover the domain-general LM, we propose to identify domain-general parameters by playing lottery tickets (dubbed doge tickets). In order to intervene the lottery, we propose a domain-general score, which depicts how domain-invariant a parameter is by associating it with the variance. Comprehensive experiments are conducted on the Amazon, Mnli and OntoNotes datasets. The results show that the doge tickets obtains an improved out-of-domain generalization in comparison with a range of competitive baselines. Analysis results further hint the existence of domain-general parameters and the performance consistency of doge tickets.
A Multibias-mitigated and Sentiment Knowledge Enriched Transformer for Debiasing in Multimodal Conversational Emotion Recognition
Jul 17, 2022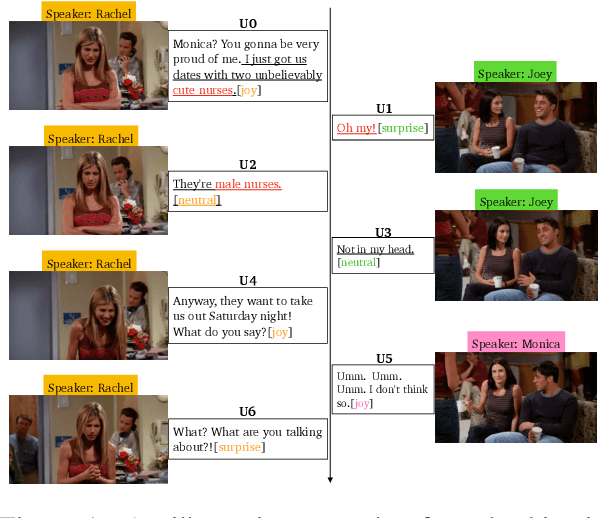

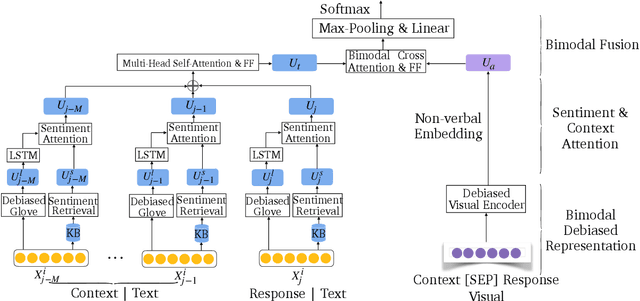
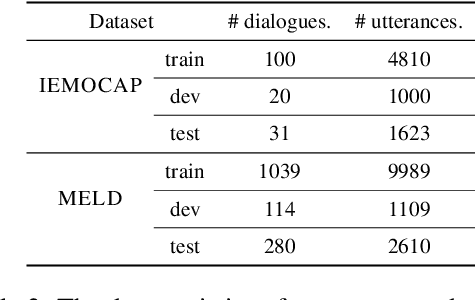
Multimodal emotion recognition in conversations (mERC) is an active research topic in natural language processing (NLP), which aims to predict human's emotional states in communications of multiple modalities, e,g., natural language and facial gestures. Innumerable implicit prejudices and preconceptions fill human language and conversations, leading to the question of whether the current data-driven mERC approaches produce a biased error. For example, such approaches may offer higher emotional scores on the utterances by females than males. In addition, the existing debias models mainly focus on gender or race, where multibias mitigation is still an unexplored task in mERC. In this work, we take the first step to solve these issues by proposing a series of approaches to mitigate five typical kinds of bias in textual utterances (i.e., gender, age, race, religion and LGBTQ+) and visual representations (i.e, gender and age), followed by a Multibias-Mitigated and sentiment Knowledge Enriched bi-modal Transformer (MMKET). Comprehensive experimental results show the effectiveness of the proposed model and prove that the debias operation has a great impact on the classification performance for mERC. We hope our study will benefit the development of bias mitigation in mERC and related emotion studies.
Aspect-specific Context Modeling for Aspect-based Sentiment Analysis
Jul 17, 2022
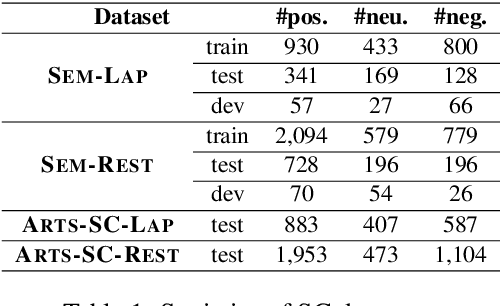
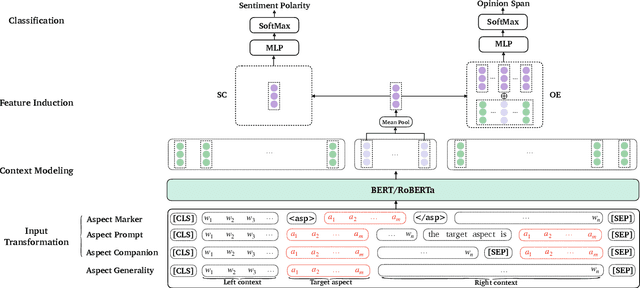
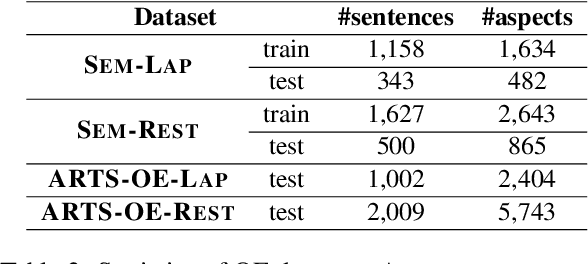
Aspect-based sentiment analysis (ABSA) aims at predicting sentiment polarity (SC) or extracting opinion span (OE) expressed towards a given aspect. Previous work in ABSA mostly relies on rather complicated aspect-specific feature induction. Recently, pretrained language models (PLMs), e.g., BERT, have been used as context modeling layers to simplify the feature induction structures and achieve state-of-the-art performance. However, such PLM-based context modeling can be not that aspect-specific. Therefore, a key question is left under-explored: how the aspect-specific context can be better modeled through PLMs? To answer the question, we attempt to enhance aspect-specific context modeling with PLM in a non-intrusive manner. We propose three aspect-specific input transformations, namely aspect companion, aspect prompt, and aspect marker. Informed by these transformations, non-intrusive aspect-specific PLMs can be achieved to promote the PLM to pay more attention to the aspect-specific context in a sentence. Additionally, we craft an adversarial benchmark for ABSA (advABSA) to see how aspect-specific modeling can impact model robustness. Extensive experimental results on standard and adversarial benchmarks for SC and OE demonstrate the effectiveness and robustness of the proposed method, yielding new state-of-the-art performance on OE and competitive performance on SC.
AutoDisc: Automatic Distillation Schedule for Large Language Model Compression
May 29, 2022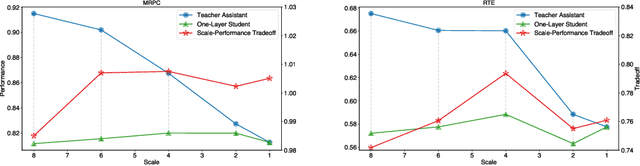
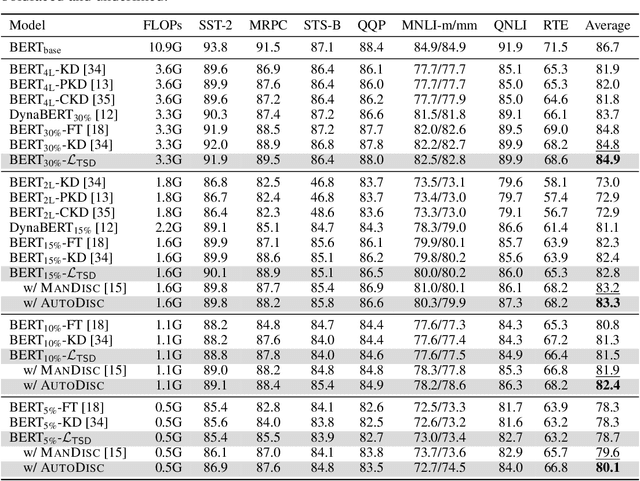

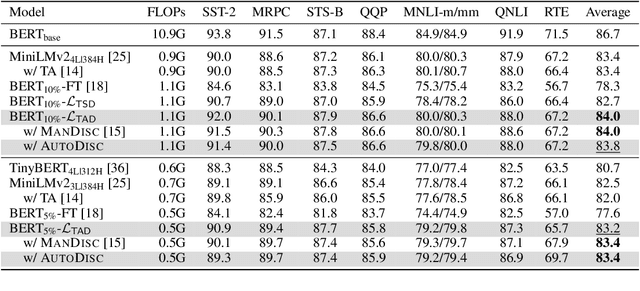
Driven by the teacher-student paradigm, knowledge distillation is one of the de facto ways for language model compression. Recent studies have uncovered that conventional distillation is less effective when facing a large capacity gap between the teacher and the student, and introduced teacher assistant-based distillation to bridge the gap. As a connection, the scale and the performance of the teacher assistant is crucial for transferring the knowledge from the teacher to the student. However, existing teacher assistant-based methods manually select the scale of the teacher assistant, which fails to identify the teacher assistant with the optimal scale-performance tradeoff. To this end, we propose an Automatic Distillation Schedule (AutoDisc) for large language model compression. In particular, AutoDisc first specifies a set of teacher assistant candidates at different scales with gridding and pruning, and then optimizes all candidates in an once-for-all optimization with two approximations. The best teacher assistant scale is automatically selected according to the scale-performance tradeoff. AutoDisc is evaluated with an extensive set of experiments on a language understanding benchmark GLUE. Experimental results demonstrate the improved performance and applicability of our AutoDisc. We further apply AutoDisc on a language model with over one billion parameters and show the scalability of AutoDisc.
Making Pre-trained Language Models Good Long-tailed Learners
May 11, 2022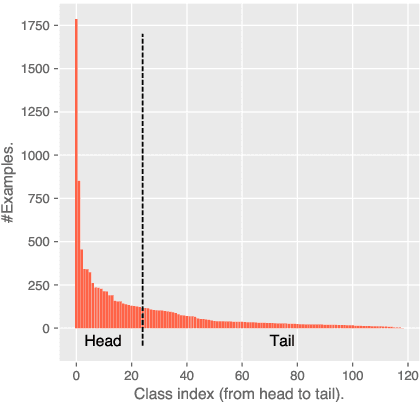
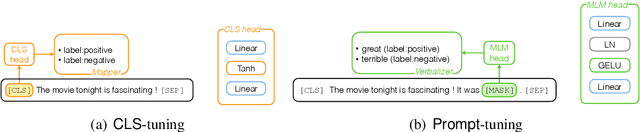
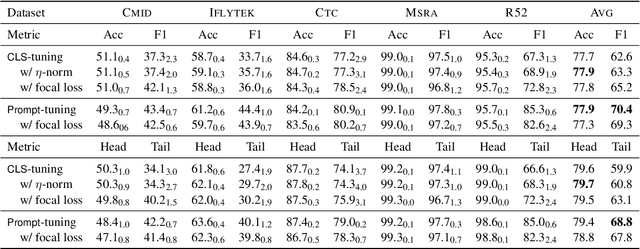
Prompt-tuning has shown appealing performance in few-shot classification by virtue of its capability in effectively exploiting pre-trained knowledge. This motivates us to check the hypothesis that prompt-tuning is also a promising choice for long-tailed classification, since the tail classes are intuitively few-shot ones. To achieve this aim, we conduct empirical studies to examine the hypothesis. The results demonstrate that prompt-tuning exactly makes pre-trained language models at least good long-tailed learners. For intuitions on why prompt-tuning can achieve good performance in long-tailed classification, we carry out an in-depth analysis by progressively bridging the gap between prompt-tuning and commonly used fine-tuning. The summary is that the classifier structure and parameterization form the key to making good long-tailed learners, in comparison with the less important input structure. Finally, we verify the applicability of our finding to few-shot classification.
Adaptable Text Matching via Meta-Weight Regulator
Apr 27, 2022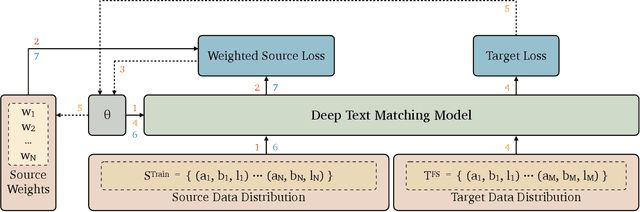
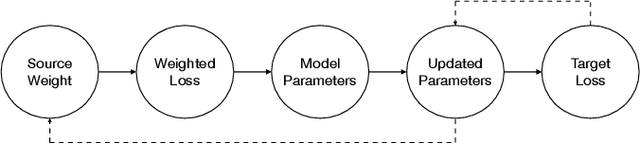
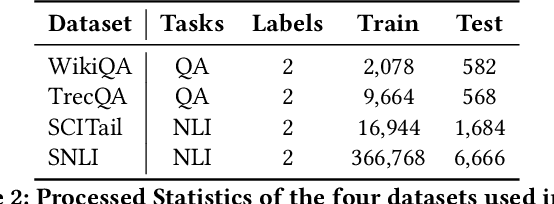
Neural text matching models have been used in a range of applications such as question answering and natural language inference, and have yielded a good performance. However, these neural models are of a limited adaptability, resulting in a decline in performance when encountering test examples from a different dataset or even a different task. The adaptability is particularly important in the few-shot setting: in many cases, there is only a limited amount of labeled data available for a target dataset or task, while we may have access to a richly labeled source dataset or task. However, adapting a model trained on the abundant source data to a few-shot target dataset or task is challenging. To tackle this challenge, we propose a Meta-Weight Regulator (MWR), which is a meta-learning approach that learns to assign weights to the source examples based on their relevance to the target loss. Specifically, MWR first trains the model on the uniformly weighted source examples, and measures the efficacy of the model on the target examples via a loss function. By iteratively performing a (meta) gradient descent, high-order gradients are propagated to the source examples. These gradients are then used to update the weights of source examples, in a way that is relevant to the target performance. As MWR is model-agnostic, it can be applied to any backbone neural model. Extensive experiments are conducted with various backbone text matching models, on four widely used datasets and two tasks. The results demonstrate that our proposed approach significantly outperforms a number of existing adaptation methods and effectively improves the cross-dataset and cross-task adaptability of the neural text matching models in the few-shot setting.
EEG based Emotion Recognition: A Tutorial and Review
Mar 16, 2022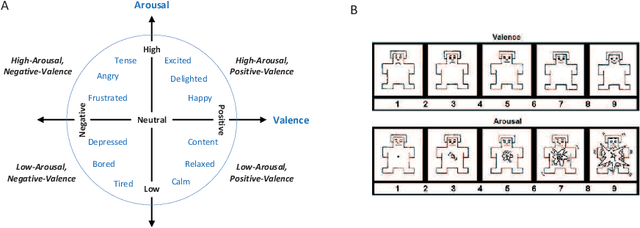
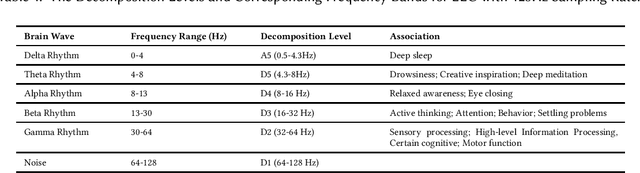
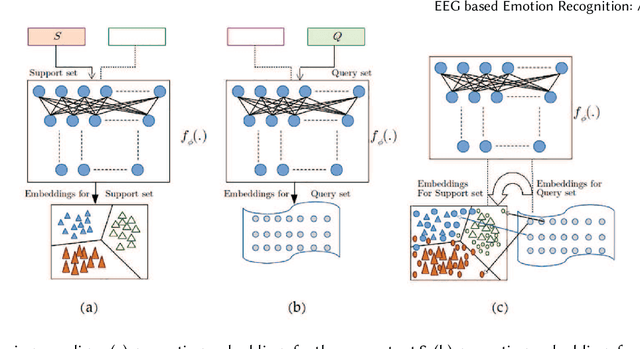
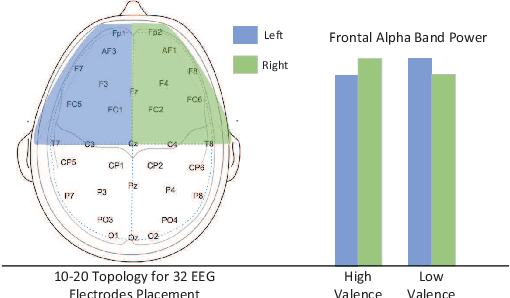
Emotion recognition technology through analyzing the EEG signal is currently an essential concept in Artificial Intelligence and holds great potential in emotional health care, human-computer interaction, multimedia content recommendation, etc. Though there have been several works devoted to reviewing EEG-based emotion recognition, the content of these reviews needs to be updated. In addition, those works are either fragmented in content or only focus on specific techniques adopted in this area but neglect the holistic perspective of the entire technical routes. Hence, in this paper, we review from the perspective of researchers who try to take the first step on this topic. We review the recent representative works in the EEG-based emotion recognition research and provide a tutorial to guide the researchers to start from the beginning. The scientific basis of EEG-based emotion recognition in the psychological and physiological levels is introduced. Further, we categorize these reviewed works into different technical routes and illustrate the theoretical basis and the research motivation, which will help the readers better understand why those techniques are studied and employed. At last, existing challenges and future investigations are also discussed in this paper, which guides the researchers to decide potential future research directions.
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
Jan 14, 2022
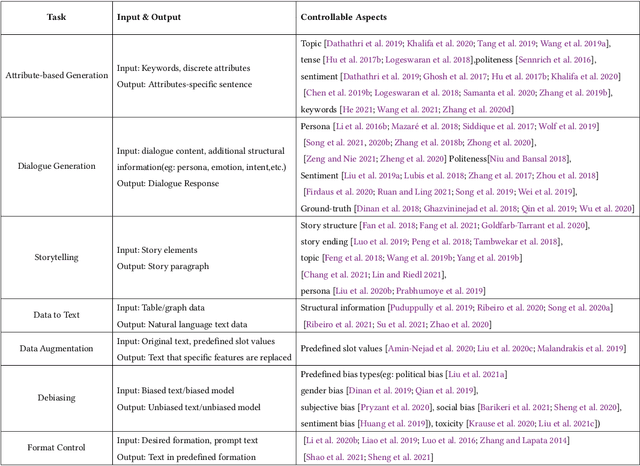
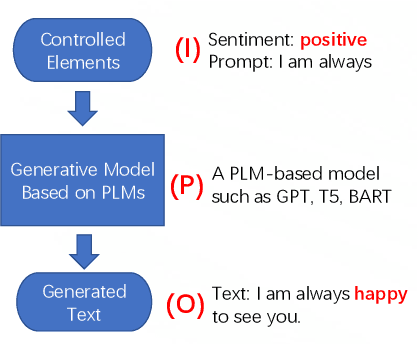
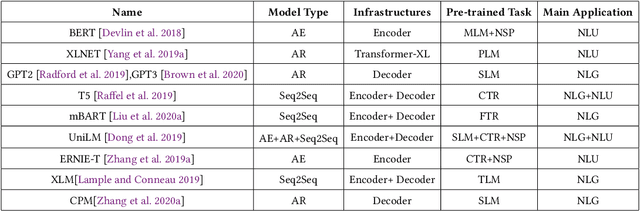
Controllable Text Generation (CTG) is emerging area in the field of natural language generation (NLG). It is regarded as crucial for the development of advanced text generation technologies that are more natural and better meet the specific constraints in practical applications. In recent years, methods using large-scale pre-trained language models (PLMs), in particular the widely used transformer-based PLMs, have become a new paradigm of NLG, allowing generation of more diverse and fluent text. However, due to the lower level of interpretability of deep neural networks, the controllability of these methods need to be guaranteed. To this end, controllable text generation using transformer-based PLMs has become a rapidly growing yet challenging new research hotspot. A diverse range of approaches have emerged in the recent 3-4 years, targeting different CTG tasks which may require different types of controlled constraints. In this paper, we present a systematic critical review on the common tasks, main approaches and evaluation methods in this area. Finally, we discuss the challenges that the field is facing, and put forward various promising future directions. To the best of our knowledge, this is the first survey paper to summarize CTG techniques from the perspective of PLMs. We hope it can help researchers in related fields to quickly track the academic frontier, providing them with a landscape of the area and a roadmap for future research.