 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSePaint: Semantic Map Inpainting via Multinomial Diffusion
Mar 05, 2023



Prediction beyond partial observations is crucial for robots to navigate in unknown environments because it can provide extra information regarding the surroundings beyond the current sensing range or resolution. In this work, we consider the inpainting of semantic Bird's-Eye-View maps. We propose SePaint, an inpainting model for semantic data based on generative multinomial diffusion. To maintain semantic consistency, we need to condition the prediction for the missing regions on the known regions. We propose a novel and efficient condition strategy, Look-Back Condition (LB-Con), which performs one-step look-back operations during the reverse diffusion process. By doing so, we are able to strengthen the harmonization between unknown and known parts, leading to better completion performance. We have conducted extensive experiments on different datasets, showing our proposed model outperforms commonly used interpolation methods in various robotic applications.
LoCoNet: Long-Short Context Network for Active Speaker Detection
Jan 19, 2023



Active Speaker Detection (ASD) aims to identify who is speaking in each frame of a video. ASD reasons from audio and visual information from two contexts: long-term intra-speaker context and short-term inter-speaker context. Long-term intra-speaker context models the temporal dependencies of the same speaker, while short-term inter-speaker context models the interactions of speakers in the same scene. These two contexts are complementary to each other and can help infer the active speaker. Motivated by these observations, we propose LoCoNet, a simple yet effective Long-Short Context Network that models the long-term intra-speaker context and short-term inter-speaker context. We use self-attention to model long-term intra-speaker context due to its effectiveness in modeling long-range dependencies, and convolutional blocks that capture local patterns to model short-term inter-speaker context. Extensive experiments show that LoCoNet achieves state-of-the-art performance on multiple datasets, achieving an mAP of 95.2%(+1.1%) on AVA-ActiveSpeaker, 68.1%(+22%) on Columbia dataset, 97.2%(+2.8%) on Talkies dataset and 59.7%(+8.0%) on Ego4D dataset. Moreover, in challenging cases where multiple speakers are present, or face of active speaker is much smaller than other faces in the same scene, LoCoNet outperforms previous state-of-the-art methods by 3.4% on the AVA-ActiveSpeaker dataset. The code will be released at https://github.com/SJTUwxz/LoCoNet_ASD.
VindLU: A Recipe for Effective Video-and-Language Pretraining
Dec 09, 2022



The last several years have witnessed remarkable progress in video-and-language (VidL) understanding. However, most modern VidL approaches use complex and specialized model architectures and sophisticated pretraining protocols, making the reproducibility, analysis and comparisons of these frameworks difficult. Hence, instead of proposing yet another new VidL model, this paper conducts a thorough empirical study demystifying the most important factors in the VidL model design. Among the factors that we investigate are (i) the spatiotemporal architecture design, (ii) the multimodal fusion schemes, (iii) the pretraining objectives, (iv) the choice of pretraining data, (v) pretraining and finetuning protocols, and (vi) dataset and model scaling. Our empirical study reveals that the most important design factors include: temporal modeling, video-to-text multimodal fusion, masked modeling objectives, and joint training on images and videos. Using these empirical insights, we then develop a step-by-step recipe, dubbed VindLU, for effective VidL pretraining. Our final model trained using our recipe achieves comparable or better than state-of-the-art results on several VidL tasks without relying on external CLIP pretraining. In particular, on the text-to-video retrieval task, our approach obtains 61.2% on DiDeMo, and 55.0% on ActivityNet, outperforming current SOTA by 7.8% and 6.1% respectively. Furthermore, our model also obtains state-of-the-art video question-answering results on ActivityNet-QA, MSRVTT-QA, MSRVTT-MC and TVQA. Our code and pretrained models are publicly available at: https://github.com/klauscc/VindLU.
Attention is All They Need: Exploring the Media Archaeology of the Computer Vision Research Paper
Sep 22, 2022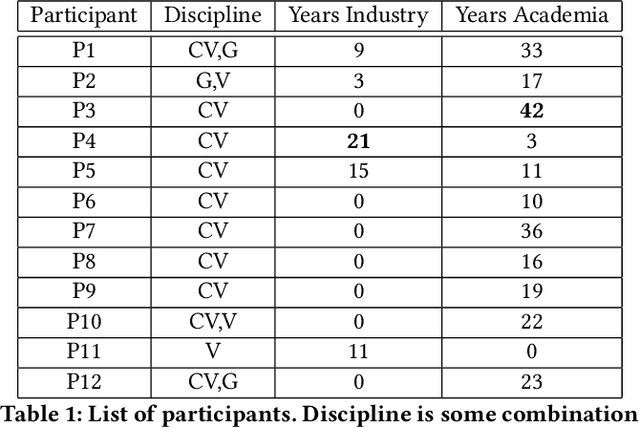

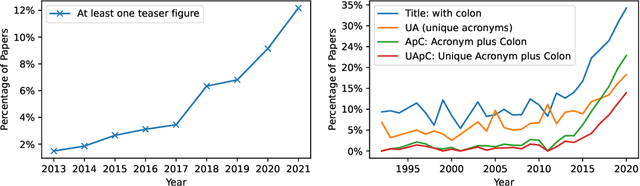
The success of deep learning has led to the rapid transformation and growth of many areas of computer science, including computer vision. In this work, we examine the effects of this growth through the computer vision research paper itself by analyzing the figures and tables in research papers from a media archaeology perspective. We ground our investigation both through interviews with veteran researchers spanning computer vision, graphics and visualization, and computational analysis of a decade of vision conference papers. Our analysis focuses on elements with roles in advertising, measuring and disseminating an increasingly commodified "contribution." We argue that each of these elements has shaped and been shaped by the climate of computer vision, ultimately contributing to that commodification. Through this work, we seek to motivate future discussion surrounding the design of the research paper and the broader socio-technical publishing system.
Action Recognition based on Cross-Situational Action-object Statistics
Aug 15, 2022

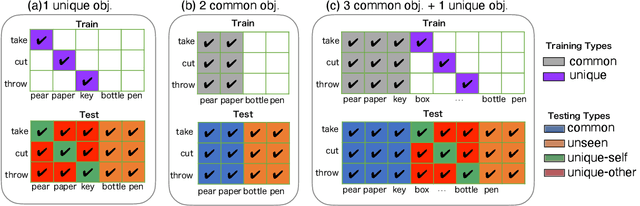
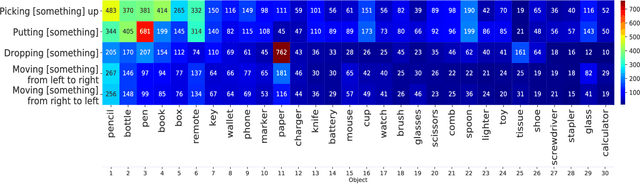
Machine learning models of visual action recognition are typically trained and tested on data from specific situations where actions are associated with certain objects. It is an open question how action-object associations in the training set influence a model's ability to generalize beyond trained situations. We set out to identify properties of training data that lead to action recognition models with greater generalization ability. To do this, we take inspiration from a cognitive mechanism called cross-situational learning, which states that human learners extract the meaning of concepts by observing instances of the same concept across different situations. We perform controlled experiments with various types of action-object associations, and identify key properties of action-object co-occurrence in training data that lead to better classifiers. Given that these properties are missing in the datasets that are typically used to train action classifiers in the computer vision literature, our work provides useful insights on how we should best construct datasets for efficiently training for better generalization.
Graph Neural Network and Spatiotemporal Transformer Attention for 3D Video Object Detection from Point Clouds
Jul 26, 2022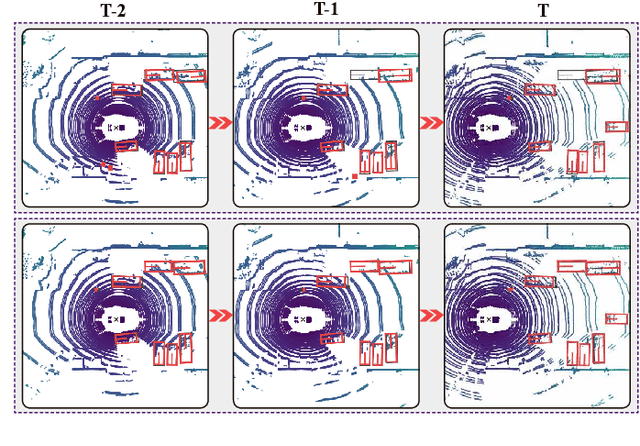
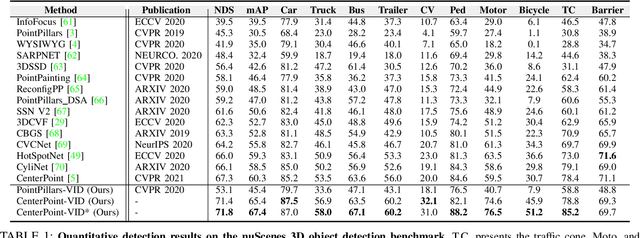
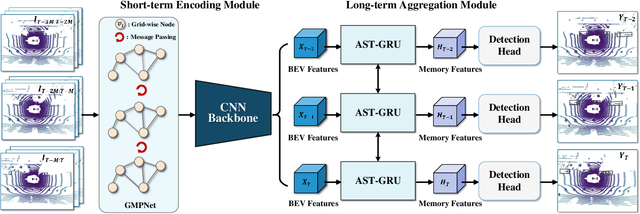

Previous works for LiDAR-based 3D object detection mainly focus on the single-frame paradigm. In this paper, we propose to detect 3D objects by exploiting temporal information in multiple frames, i.e., the point cloud videos. We empirically categorize the temporal information into short-term and long-term patterns. To encode the short-term data, we present a Grid Message Passing Network (GMPNet), which considers each grid (i.e., the grouped points) as a node and constructs a k-NN graph with the neighbor grids. To update features for a grid, GMPNet iteratively collects information from its neighbors, thus mining the motion cues in grids from nearby frames. To further aggregate the long-term frames, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU), which contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module. STA and TTA enhance the vanilla GRU to focus on small objects and better align the moving objects. Our overall framework supports both online and offline video object detection in point clouds. We implement our algorithm based on prevalent anchor-based and anchor-free detectors. The evaluation results on the challenging nuScenes benchmark show the superior performance of our method, achieving the 1st on the leaderboard without any bells and whistles, by the time the paper is submitted.
Reinforcing Generated Images via Meta-learning for One-Shot Fine-Grained Visual Recognition
Apr 22, 2022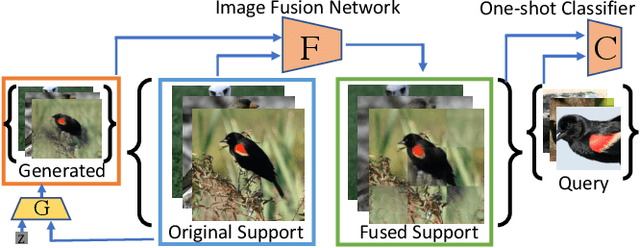

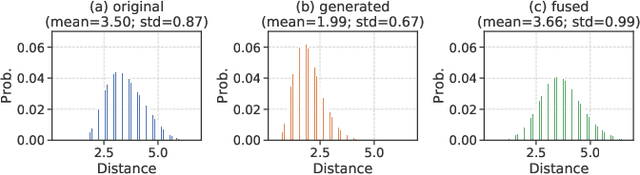
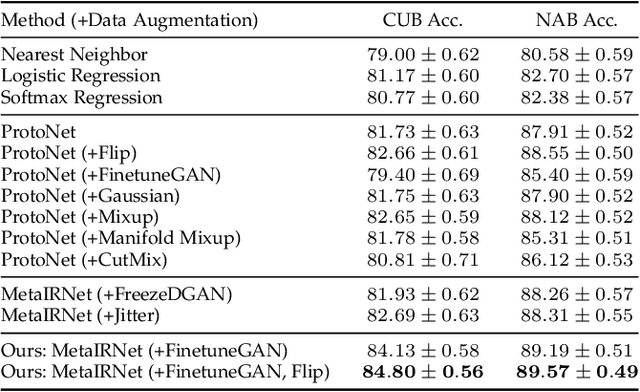
One-shot fine-grained visual recognition often suffers from the problem of having few training examples for new fine-grained classes. To alleviate this problem, off-the-shelf image generation techniques based on Generative Adversarial Networks (GANs) can potentially create additional training images. However, these GAN-generated images are often not helpful for actually improving the accuracy of one-shot fine-grained recognition. In this paper, we propose a meta-learning framework to combine generated images with original images, so that the resulting "hybrid" training images improve one-shot learning. Specifically, the generic image generator is updated by a few training instances of novel classes, and a Meta Image Reinforcing Network (MetaIRNet) is proposed to conduct one-shot fine-grained recognition as well as image reinforcement. Our experiments demonstrate consistent improvement over baselines on one-shot fine-grained image classification benchmarks. Furthermore, our analysis shows that the reinforced images have more diversity compared to the original and GAN-generated images.
Controlling the Quality of Distillation in Response-Based Network Compression
Dec 19, 2021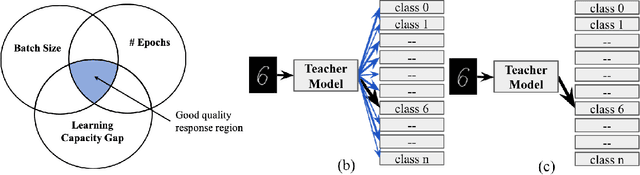


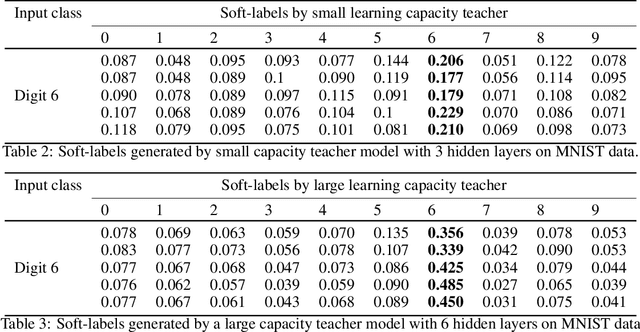
The performance of a distillation-based compressed network is governed by the quality of distillation. The reason for the suboptimal distillation of a large network (teacher) to a smaller network (student) is largely attributed to the gap in the learning capacities of given teacher-student pair. While it is hard to distill all the knowledge of a teacher, the quality of distillation can be controlled to a large extent to achieve better performance. Our experiments show that the quality of distillation is largely governed by the quality of teacher's response, which in turn is heavily affected by the presence of similarity information in its response. A well-trained large capacity teacher loses similarity information between classes in the process of learning fine-grained discriminative properties for classification. The absence of similarity information causes the distillation process to be reduced from one example-many class learning to one example-one class learning, thereby throttling the flow of diverse knowledge from the teacher. With the implicit assumption that only the instilled knowledge can be distilled, instead of focusing only on the knowledge distilling process, we scrutinize the knowledge inculcation process. We argue that for a given teacher-student pair, the quality of distillation can be improved by finding the sweet spot between batch size and number of epochs while training the teacher. We discuss the steps to find this sweet spot for better distillation. We also propose the distillation hypothesis to differentiate the behavior of the distillation process between knowledge distillation and regularization effect. We conduct all our experiments on three different datasets.
Polyline Based Generative Navigable Space Segmentation for Autonomous Visual Navigation
Oct 29, 2021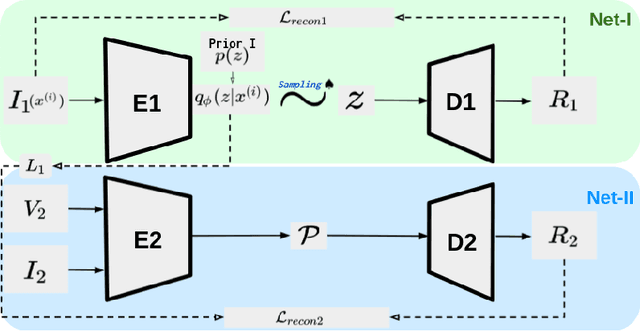
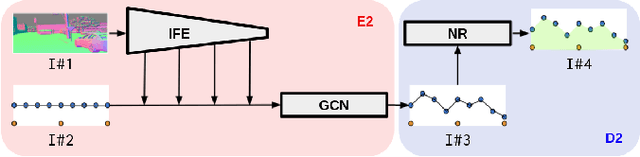
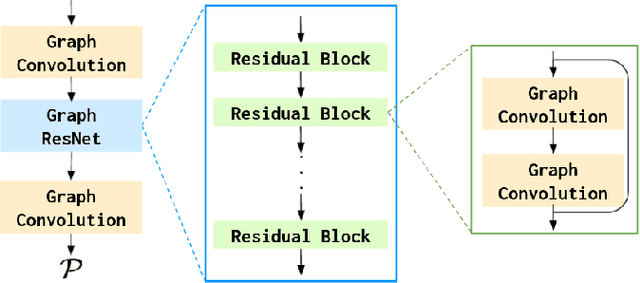
Detecting navigable space is a fundamental capability for mobile robots navigating in unknown or unmapped environments. In this work, we treat the visual navigable space segmentation as a scene decomposition problem and propose Polyline Segmentation Variational AutoEncoder Networks (PSV-Nets), a representation-learning-based framework to enable robots to learn the navigable space segmentation in an unsupervised manner. Current segmentation techniques heavily rely on supervised learning strategies which demand a large amount of pixel-level annotated images. In contrast, the proposed framework leverages a generative model - Variational AutoEncoder (VAE) and an AutoEncoder (AE) to learn a polyline representation that compactly outlines the desired navigable space boundary in an unsupervised way. We also propose a visual receding horizon planning method that uses the learned navigable space and a Scaled Euclidean Distance Field (SEDF) to achieve autonomous navigation without an explicit map. Through extensive experiments, we have validated that the proposed PSV-Nets can learn the visual navigable space with high accuracy, even without any single label. We also show that the prediction of the PSV-Nets can be further improved with a small number of labels (if available) and can significantly outperform the state-of-the-art fully supervised-learning-based segmentation methods.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/