 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Video Description With Cluster-Regularized Ensemble Ranking
Jul 29, 2020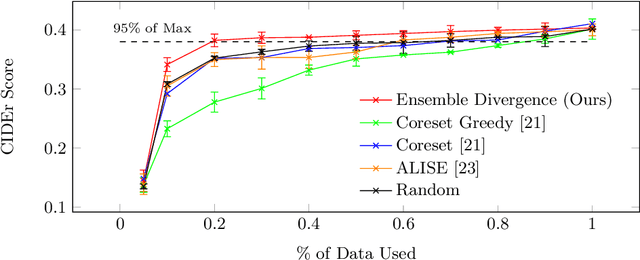
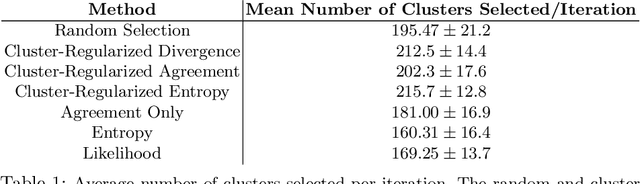
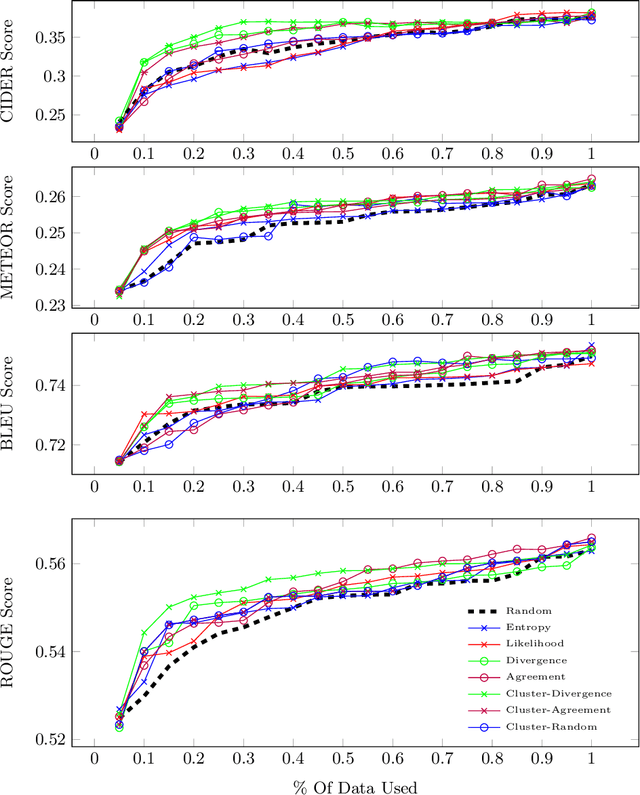
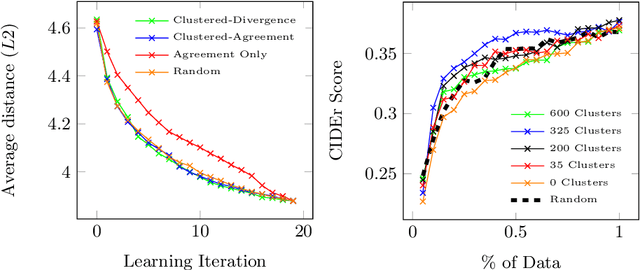
Automatic video captioning aims to train models to generate text descriptions for all segments in a video, however, the most effective approaches require large amounts of manual annotation which is slow and expensive. Active learning is a promising way to efficiently build a training set for video captioning tasks while reducing the need to manually label uninformative examples. In this work we both explore various active learning approaches for automatic video captioning and show that a cluster-regularized ensemble strategy provides the best active learning approach to efficiently gather training sets for video captioning. We evaluate our approaches on the MSR-VTT and LSMDC datasets using both transformer and LSTM based captioning models and show that our novel strategy can achieve high performance while using up to 60% fewer training data than the strong state of the art baselines.
Learning Video Representations from Textual Web Supervision
Jul 29, 2020
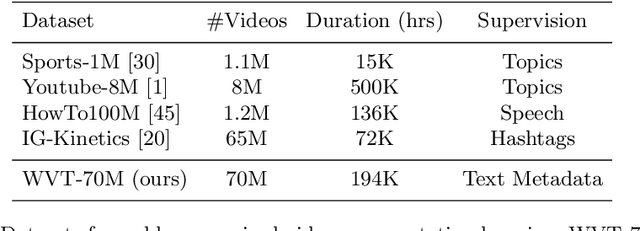
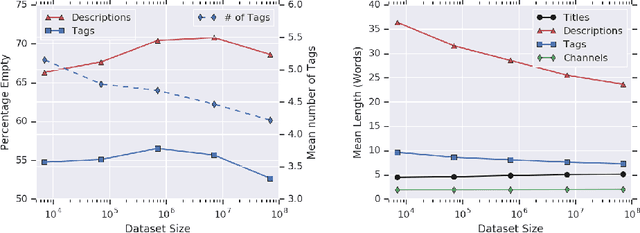

Videos found on the Internet are paired with pieces of text, such as titles and descriptions. This text typically describes the most important content in the video, such as the objects in the scene and the actions being performed. Based on this observation, we propose to use such text as a method for learning video representations. To accomplish this, we propose a data collection process and use it to collect 70M video clips shared publicly on the Internet, and we then train a model to pair each video with its associated text. We fine-tune the model on several down-stream action recognition tasks, including Kinetics, HMDB-51, and UCF-101. We find that this approach is an effective method of pretraining video representations. Specifically, it leads to improvements over from-scratch training on all benchmarks, outperforms many methods for self-supervised and webly-supervised video representation learning, and achieves an improvement of 2.2% accuracy on HMDB-51.
The AVA-Kinetics Localized Human Actions Video Dataset
May 20, 2020
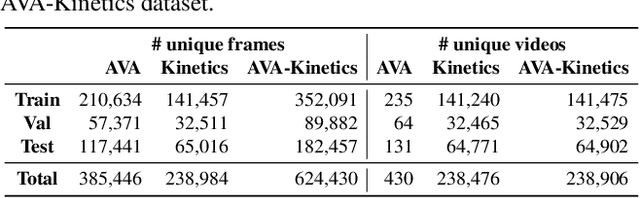
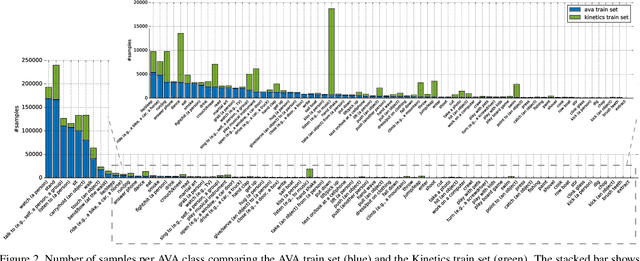
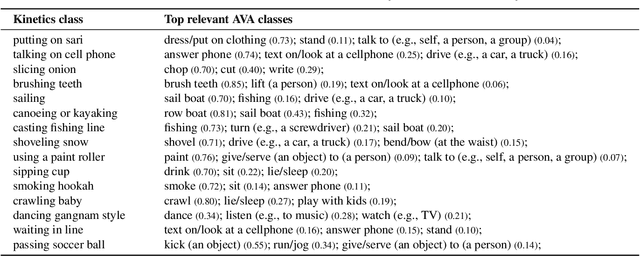
This paper describes the AVA-Kinetics localized human actions video dataset. The dataset is collected by annotating videos from the Kinetics-700 dataset using the AVA annotation protocol, and extending the original AVA dataset with these new AVA annotated Kinetics clips. The dataset contains over 230k clips annotated with the 80 AVA action classes for each of the humans in key-frames. We describe the annotation process and provide statistics about the new dataset. We also include a baseline evaluation using the Video Action Transformer Network on the AVA-Kinetics dataset, demonstrating improved performance for action classification on the AVA test set. The dataset can be downloaded from https://research.google.com/ava/
D3D: Distilled 3D Networks for Video Action Recognition
Dec 19, 2018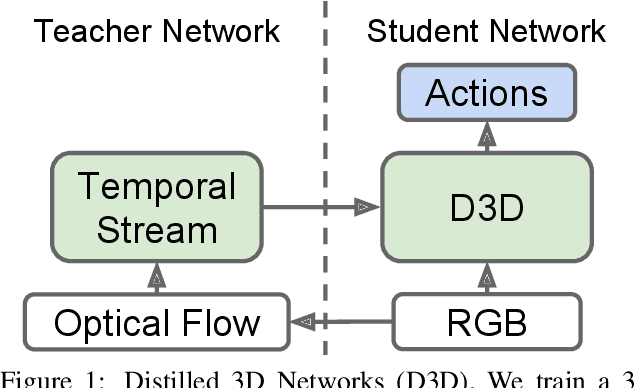
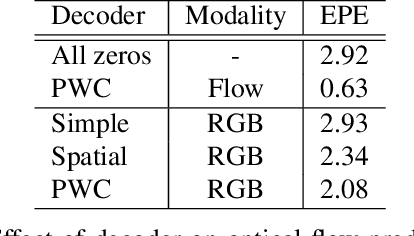
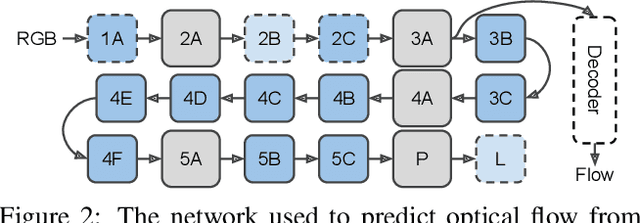
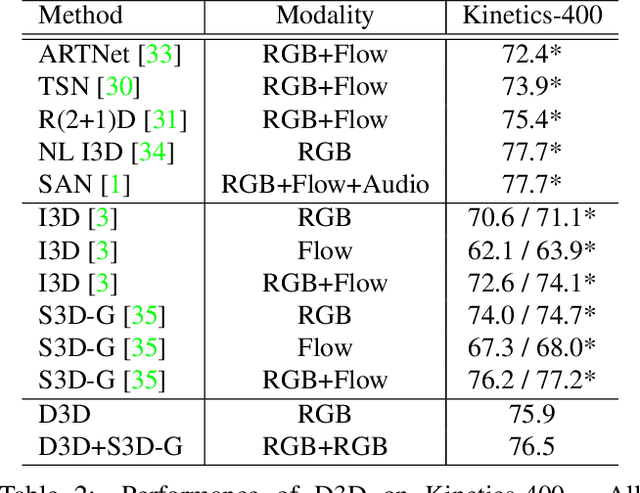
State-of-the-art methods for video action recognition commonly use an ensemble of two networks: the spatial stream, which takes RGB frames as input, and the temporal stream, which takes optical flow as input. In recent work, both of these streams consist of 3D Convolutional Neural Networks, which apply spatiotemporal filters to the video clip before performing classification. Conceptually, the temporal filters should allow the spatial stream to learn motion representations, making the temporal stream redundant. However, we still see significant benefits in action recognition performance by including an entirely separate temporal stream, indicating that the spatial stream is "missing" some of the signal captured by the temporal stream. In this work, we first investigate whether motion representations are indeed missing in the spatial stream of 3D CNNs. Second, we demonstrate that these motion representations can be improved by distillation, by tuning the spatial stream to predict the outputs of the temporal stream, effectively combining both models into a single stream. Finally, we show that our Distilled 3D Network (D3D) achieves performance on par with two-stream approaches, using only a single model and with no need to compute optical flow.
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


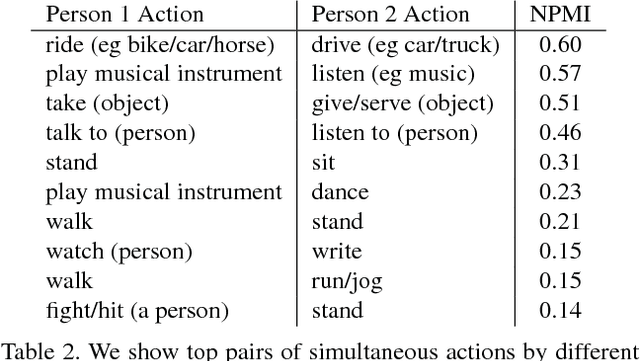
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.
Rethinking the Faster R-CNN Architecture for Temporal Action Localization
Apr 20, 2018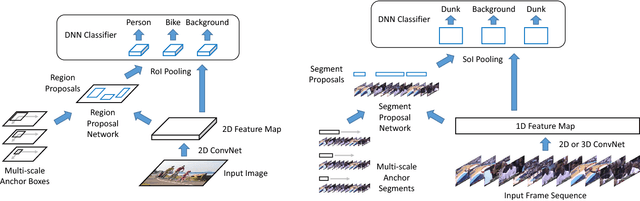
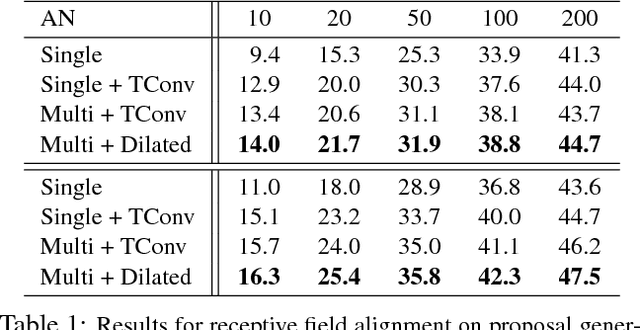
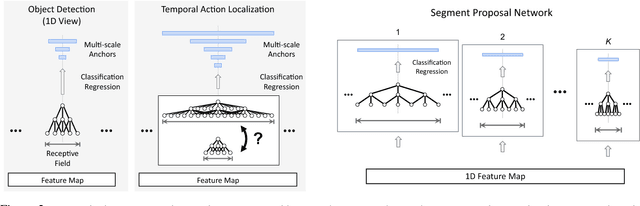
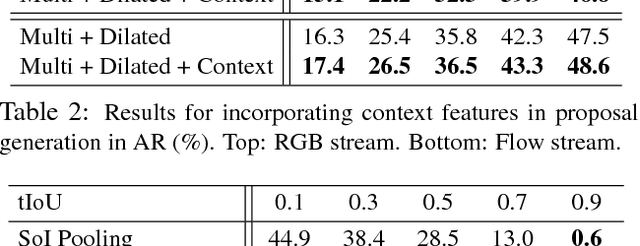
We propose TAL-Net, an improved approach to temporal action localization in video that is inspired by the Faster R-CNN object detection framework. TAL-Net addresses three key shortcomings of existing approaches: (1) we improve receptive field alignment using a multi-scale architecture that can accommodate extreme variation in action durations; (2) we better exploit the temporal context of actions for both proposal generation and action classification by appropriately extending receptive fields; and (3) we explicitly consider multi-stream feature fusion and demonstrate that fusing motion late is important. We achieve state-of-the-art performance for both action proposal and localization on THUMOS'14 detection benchmark and competitive performance on ActivityNet challenge.