 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
Look Ma, no markers: holistic performance capture without the hassle
Oct 15, 2024



We tackle the problem of highly-accurate, holistic performance capture for the face, body and hands simultaneously. Motion-capture technologies used in film and game production typically focus only on face, body or hand capture independently, involve complex and expensive hardware and a high degree of manual intervention from skilled operators. While machine-learning-based approaches exist to overcome these problems, they usually only support a single camera, often operate on a single part of the body, do not produce precise world-space results, and rarely generalize outside specific contexts. In this work, we introduce the first technique for marker-free, high-quality reconstruction of the complete human body, including eyes and tongue, without requiring any calibration, manual intervention or custom hardware. Our approach produces stable world-space results from arbitrary camera rigs as well as supporting varied capture environments and clothing. We achieve this through a hybrid approach that leverages machine learning models trained exclusively on synthetic data and powerful parametric models of human shape and motion. We evaluate our method on a number of body, face and hand reconstruction benchmarks and demonstrate state-of-the-art results that generalize on diverse datasets.
3DiFACE: Diffusion-based Speech-driven 3D Facial Animation and Editing
Dec 01, 2023



We present 3DiFACE, a novel method for personalized speech-driven 3D facial animation and editing. While existing methods deterministically predict facial animations from speech, they overlook the inherent one-to-many relationship between speech and facial expressions, i.e., there are multiple reasonable facial expression animations matching an audio input. It is especially important in content creation to be able to modify generated motion or to specify keyframes. To enable stochasticity as well as motion editing, we propose a lightweight audio-conditioned diffusion model for 3D facial motion. This diffusion model can be trained on a small 3D motion dataset, maintaining expressive lip motion output. In addition, it can be finetuned for specific subjects, requiring only a short video of the person. Through quantitative and qualitative evaluations, we show that our method outperforms existing state-of-the-art techniques and yields speech-driven animations with greater fidelity and diversity.
HMD-NeMo: Online 3D Avatar Motion Generation From Sparse Observations
Aug 22, 2023



Generating both plausible and accurate full body avatar motion is the key to the quality of immersive experiences in mixed reality scenarios. Head-Mounted Devices (HMDs) typically only provide a few input signals, such as head and hands 6-DoF. Recently, different approaches achieved impressive performance in generating full body motion given only head and hands signal. However, to the best of our knowledge, all existing approaches rely on full hand visibility. While this is the case when, e.g., using motion controllers, a considerable proportion of mixed reality experiences do not involve motion controllers and instead rely on egocentric hand tracking. This introduces the challenge of partial hand visibility owing to the restricted field of view of the HMD. In this paper, we propose the first unified approach, HMD-NeMo, that addresses plausible and accurate full body motion generation even when the hands may be only partially visible. HMD-NeMo is a lightweight neural network that predicts the full body motion in an online and real-time fashion. At the heart of HMD-NeMo is the spatio-temporal encoder with novel temporally adaptable mask tokens that encourage plausible motion in the absence of hand observations. We perform extensive analysis of the impact of different components in HMD-NeMo and introduce a new state-of-the-art on AMASS dataset through our evaluation.
Probabilistic Human Mesh Recovery in 3D Scenes from Egocentric Views
Apr 12, 2023



Automatic perception of human behaviors during social interactions is crucial for AR/VR applications, and an essential component is estimation of plausible 3D human pose and shape of our social partners from the egocentric view. One of the biggest challenges of this task is severe body truncation due to close social distances in egocentric scenarios, which brings large pose ambiguities for unseen body parts. To tackle this challenge, we propose a novel scene-conditioned diffusion method to model the body pose distribution. Conditioned on the 3D scene geometry, the diffusion model generates bodies in plausible human-scene interactions, with the sampling guided by a physics-based collision score to further resolve human-scene inter-penetrations. The classifier-free training enables flexible sampling with different conditions and enhanced diversity. A visibility-aware graph convolution model guided by per-joint visibility serves as the diffusion denoiser to incorporate inter-joint dependencies and per-body-part control. Extensive evaluations show that our method generates bodies in plausible interactions with 3D scenes, achieving both superior accuracy for visible joints and diversity for invisible body parts. The code will be available at https://sanweiliti.github.io/egohmr/egohmr.html.
Imitator: Personalized Speech-driven 3D Facial Animation
Dec 30, 2022Speech-driven 3D facial animation has been widely explored, with applications in gaming, character animation, virtual reality, and telepresence systems. State-of-the-art methods deform the face topology of the target actor to sync the input audio without considering the identity-specific speaking style and facial idiosyncrasies of the target actor, thus, resulting in unrealistic and inaccurate lip movements. To address this, we present Imitator, a speech-driven facial expression synthesis method, which learns identity-specific details from a short input video and produces novel facial expressions matching the identity-specific speaking style and facial idiosyncrasies of the target actor. Specifically, we train a style-agnostic transformer on a large facial expression dataset which we use as a prior for audio-driven facial expressions. Based on this prior, we optimize for identity-specific speaking style based on a short reference video. To train the prior, we introduce a novel loss function based on detected bilabial consonants to ensure plausible lip closures and consequently improve the realism of the generated expressions. Through detailed experiments and a user study, we show that our approach produces temporally coherent facial expressions from input audio while preserving the speaking style of the target actors.
DynaDog+T: A Parametric Animal Model for Synthetic Canine Image Generation
Jul 20, 2021
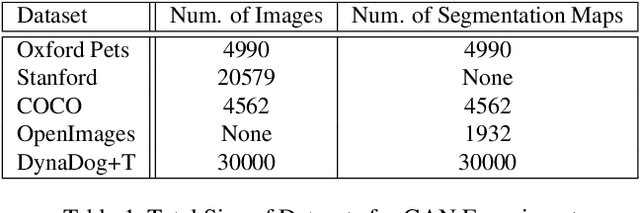


Synthetic data is becoming increasingly common for training computer vision models for a variety of tasks. Notably, such data has been applied in tasks related to humans such as 3D pose estimation where data is either difficult to create or obtain in realistic settings. Comparatively, there has been less work into synthetic animal data and it's uses for training models. Consequently, we introduce a parametric canine model, DynaDog+T, for generating synthetic canine images and data which we use for a common computer vision task, binary segmentation, which would otherwise be difficult due to the lack of available data.
RGBD-Dog: Predicting Canine Pose from RGBD Sensors
Apr 16, 2020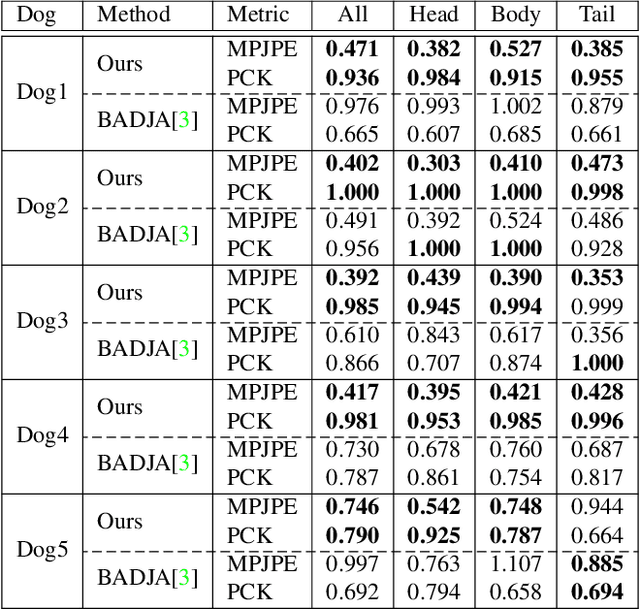
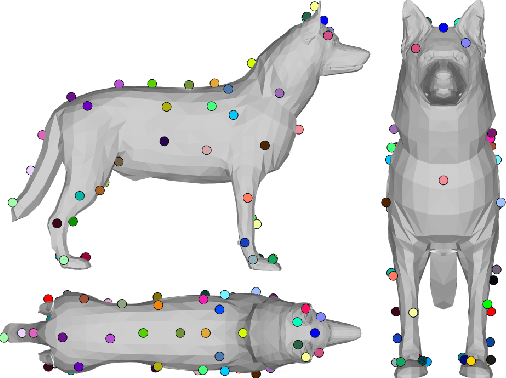
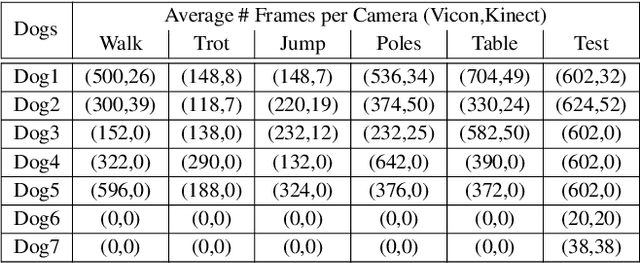
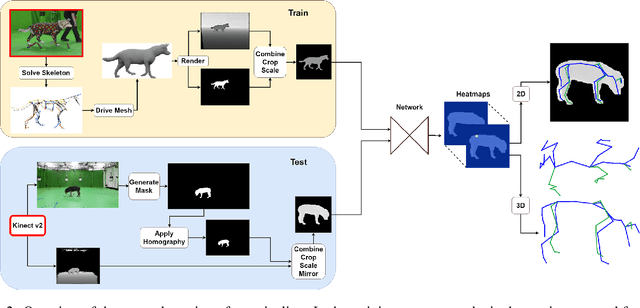
The automatic extraction of animal \reb{3D} pose from images without markers is of interest in a range of scientific fields. Most work to date predicts animal pose from RGB images, based on 2D labelling of joint positions. However, due to the difficult nature of obtaining training data, no ground truth dataset of 3D animal motion is available to quantitatively evaluate these approaches. In addition, a lack of 3D animal pose data also makes it difficult to train 3D pose-prediction methods in a similar manner to the popular field of body-pose prediction. In our work, we focus on the problem of 3D canine pose estimation from RGBD images, recording a diverse range of dog breeds with several Microsoft Kinect v2s, simultaneously obtaining the 3D ground truth skeleton via a motion capture system. We generate a dataset of synthetic RGBD images from this data. A stacked hourglass network is trained to predict 3D joint locations, which is then constrained using prior models of shape and pose. We evaluate our model on both synthetic and real RGBD images and compare our results to previously published work fitting canine models to images. Finally, despite our training set consisting only of dog data, visual inspection implies that our network can produce good predictions for images of other quadrupeds -- e.g. horses or cats -- when their pose is similar to that contained in our training set.
Unsupervised Attention-guided Image to Image Translation
Jun 19, 2018
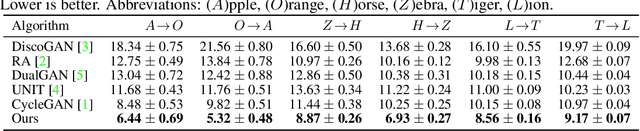
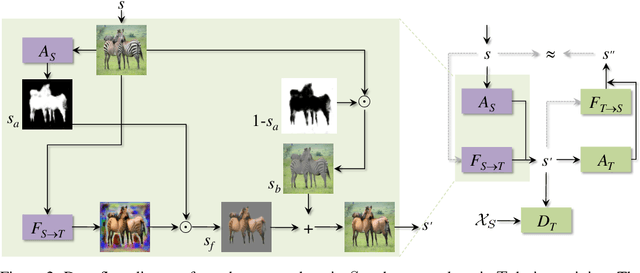

Current unsupervised image-to-image translation techniques struggle to focus their attention on individual objects without altering the background or the way multiple objects interact within a scene. Motivated by the important role of attention in human perception, we tackle this limitation by introducing unsupervised attention mechanisms that are jointly adversarialy trained with the generators and discriminators. We demonstrate qualitatively and quantitatively that our approach is able to attend to relevant regions in the image without requiring supervision, and that by doing so it achieves more realistic mappings compared to recent approaches.
Learn to Model Motion from Blurry Footages
Apr 19, 2017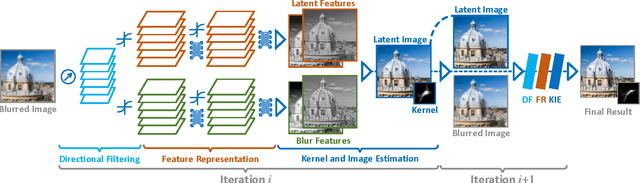
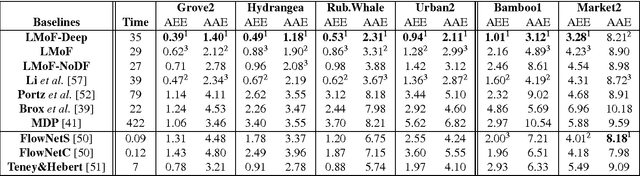


It is difficult to recover the motion field from a real-world footage given a mixture of camera shake and other photometric effects. In this paper we propose a hybrid framework by interleaving a Convolutional Neural Network (CNN) and a traditional optical flow energy. We first conduct a CNN architecture using a novel learnable directional filtering layer. Such layer encodes the angle and distance similarity matrix between blur and camera motion, which is able to enhance the blur features of the camera-shake footages. The proposed CNNs are then integrated into an iterative optical flow framework, which enable the capability of modelling and solving both the blind deconvolution and the optical flow estimation problems simultaneously. Our framework is trained end-to-end on a synthetic dataset and yields competitive precision and performance against the state-of-the-art approaches.