 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Self-Play and Scale: A Behavior Benchmark for Generalization in Autonomous Driving
May 11, 2026Recent Autonomous Driving (AD) works such as GigaFlow and PufferDrive have unlocked Reinforcement Learning (RL) at scale as a training strategy for driving policies. Yet such policies remain disconnected from established benchmarks, leaving the performance of large-scale RL for driving on standardized evaluations unknown. We present BehaviorBench -- a comprehensive test suite that closes this gap along three axes: Evaluation, Complexity, and Behavior Diversity. In terms of Evaluation, we provide an interface connecting PufferDrive to nuPlan, which, for the first time, enables policies trained via RL at scale to be evaluated on an established planning benchmark for autonomous driving. Complementarily, we offer an evaluation framework that allows planners to be benchmarked directly inside the PufferDrive simulation, at a fraction of the time. Regarding Complexity, we observe that today's standardized benchmarks are so simple that near-perfect scores are achievable by straight lane following with collision checking. We extract a meaningful, interaction-rich split from the Waymo Open Motion Dataset (WOMD) on which strong performance is impossible without multi-agent reasoning. Lastly, we address Behavior Diversity. Existing benchmarks commonly evaluate planners against a single rule-based traffic model, the Intelligent Driver Model (IDM). We provide a diverse suite of interactive traffic agents to stress-test policies under heterogeneous behaviors, beyond just using IDM. Overall, our benchmarking analysis uncovers the following insight: despite learning interactive behaviors in an emergent manner, policies trained via pure self-play under standard reward functions overfit to their training opponents and fail to generalize to other traffic agent behaviors. Building on this observation, we propose a hybrid planner that combines a PPO policy with a rule-based planner.
Artificial Intelligence for Modeling and Simulation of Mixed Automated and Human Traffic
Apr 14, 2026Autonomous vehicles (AVs) are now operating on public roads, which makes their testing and validation more critical than ever. Simulation offers a safe and controlled environment for evaluating AV performance in varied conditions. However, existing simulation tools mainly focus on graphical realism and rely on simple rule-based models and therefore fail to accurately represent the complexity of driving behaviors and interactions. Artificial intelligence (AI) has shown strong potential to address these limitations; however, despite the rapid progress across AI methodologies, a comprehensive survey of their application to mixed autonomy traffic simulation remains lacking. Existing surveys either focus on simulation tools without examining the AI methods behind them, or cover ego-centric decision-making without addressing the broader challenge of modeling surrounding traffic. Moreover, they do not offer a unified taxonomy of AI methods covering individual behavior modeling to full scene simulation. To address these gaps, this survey provides a structured review and synthesis of AI methods for modeling AV and human driving behavior in mixed autonomy traffic simulation. We introduce a taxonomy that organizes methods into three families: agent-level behavior models, environment-level simulation methods, and cognitive and physics-informed methods. The survey analyzes how existing simulation platforms fall short of the needs of mixed autonomy research and outlines directions to narrow this gap. It also provides a chronological overview of AI methods and reviews evaluation protocols and metrics, simulation tools, and datasets. By covering both traffic engineering and computer science perspectives, we aim to bridge the gap between these two communities.
Estimating cognitive biases with attention-aware inverse planning
Oct 29, 2025



People's goal-directed behaviors are influenced by their cognitive biases, and autonomous systems that interact with people should be aware of this. For example, people's attention to objects in their environment will be biased in a way that systematically affects how they perform everyday tasks such as driving to work. Here, building on recent work in computational cognitive science, we formally articulate the attention-aware inverse planning problem, in which the goal is to estimate a person's attentional biases from their actions. We demonstrate how attention-aware inverse planning systematically differs from standard inverse reinforcement learning and how cognitive biases can be inferred from behavior. Finally, we present an approach to attention-aware inverse planning that combines deep reinforcement learning with computational cognitive modeling. We use this approach to infer the attentional strategies of RL agents in real-life driving scenarios selected from the Waymo Open Dataset, demonstrating the scalability of estimating cognitive biases with attention-aware inverse planning.
Building reliable sim driving agents by scaling self-play
Feb 20, 2025



Simulation agents are essential for designing and testing systems that interact with humans, such as autonomous vehicles (AVs). These agents serve various purposes, from benchmarking AV performance to stress-testing the system's limits, but all use cases share a key requirement: reliability. A simulation agent should behave as intended by the designer, minimizing unintended actions like collisions that can compromise the signal-to-noise ratio of analyses. As a foundation for reliable sim agents, we propose scaling self-play to thousands of scenarios on the Waymo Open Motion Dataset under semi-realistic limits on human perception and control. Training from scratch on a single GPU, our agents nearly solve the full training set within a day. They generalize effectively to unseen test scenes, achieving a 99.8% goal completion rate with less than 0.8% combined collision and off-road incidents across 10,000 held-out scenarios. Beyond in-distribution generalization, our agents show partial robustness to out-of-distribution scenes and can be fine-tuned in minutes to reach near-perfect performance in those cases. Demonstrations of agent behaviors can be found at this link. We open-source both the pre-trained agents and the complete code base. Demonstrations of agent behaviors can be found at \url{https://sites.google.com/view/reliable-sim-agents}.
GPUDrive: Data-driven, multi-agent driving simulation at 1 million FPS
Aug 02, 2024



Multi-agent learning algorithms have been successful at generating superhuman planning in a wide variety of games but have had little impact on the design of deployed multi-agent planners. A key bottleneck in applying these techniques to multi-agent planning is that they require billions of steps of experience. To enable the study of multi-agent planning at this scale, we present GPUDrive, a GPU-accelerated, multi-agent simulator built on top of the Madrona Game Engine that can generate over a million steps of experience per second. Observation, reward, and dynamics functions are written directly in C++, allowing users to define complex, heterogeneous agent behaviors that are lowered to high-performance CUDA. We show that using GPUDrive we are able to effectively train reinforcement learning agents over many scenes in the Waymo Motion dataset, yielding highly effective goal-reaching agents in minutes for individual scenes and generally capable agents in a few hours. We ship these trained agents as part of the code base at https://github.com/Emerge-Lab/gpudrive.
Human-compatible driving partners through data-regularized self-play reinforcement learning
Mar 28, 2024



A central challenge for autonomous vehicles is coordinating with humans. Therefore, incorporating realistic human agents is essential for scalable training and evaluation of autonomous driving systems in simulation. Simulation agents are typically developed by imitating large-scale, high-quality datasets of human driving. However, pure imitation learning agents empirically have high collision rates when executed in a multi-agent closed-loop setting. To build agents that are realistic and effective in closed-loop settings, we propose Human-Regularized PPO (HR-PPO), a multi-agent algorithm where agents are trained through self-play with a small penalty for deviating from a human reference policy. In contrast to prior work, our approach is RL-first and only uses 30 minutes of imperfect human demonstrations. We evaluate agents in a large set of multi-agent traffic scenes. Results show our HR-PPO agents are highly effective in achieving goals, with a success rate of 93%, an off-road rate of 3.5%, and a collision rate of 3%. At the same time, the agents drive in a human-like manner, as measured by their similarity to existing human driving logs. We also find that HR-PPO agents show considerable improvements on proxy measures for coordination with human driving, particularly in highly interactive scenarios. We open-source our code and trained agents at https://github.com/Emerge-Lab/nocturne_lab and provide demonstrations of agent behaviors at https://sites.google.com/view/driving-partners.
Using Cooperative Game Theory to Prune Neural Networks
Nov 17, 2023



We show how solution concepts from cooperative game theory can be used to tackle the problem of pruning neural networks. The ever-growing size of deep neural networks (DNNs) increases their performance, but also their computational requirements. We introduce a method called Game Theory Assisted Pruning (GTAP), which reduces the neural network's size while preserving its predictive accuracy. GTAP is based on eliminating neurons in the network based on an estimation of their joint impact on the prediction quality through game theoretic solutions. Specifically, we use a power index akin to the Shapley value or Banzhaf index, tailored using a procedure similar to Dropout (commonly used to tackle overfitting problems in machine learning). Empirical evaluation of both feedforward networks and convolutional neural networks shows that this method outperforms existing approaches in the achieved tradeoff between the number of parameters and model accuracy.
Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members
Aug 18, 2022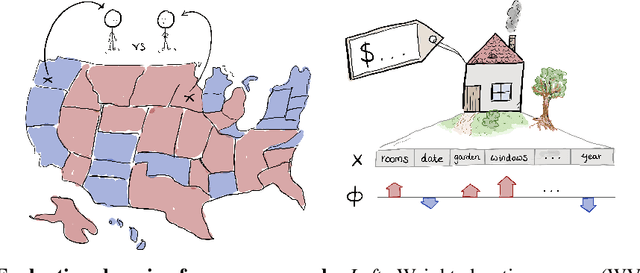
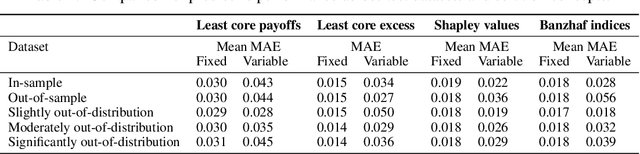
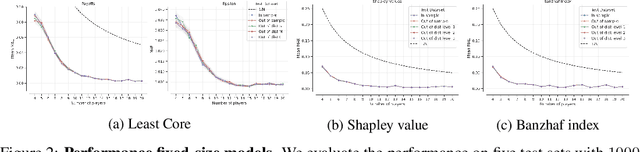
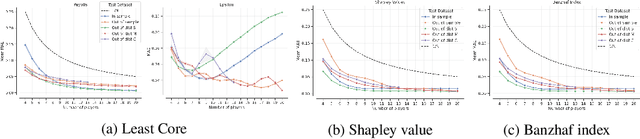
In many multi-agent settings, participants can form teams to achieve collective outcomes that may far surpass their individual capabilities. Measuring the relative contributions of agents and allocating them shares of the reward that promote long-lasting cooperation are difficult tasks. Cooperative game theory offers solution concepts identifying distribution schemes, such as the Shapley value, that fairly reflect the contribution of individuals to the performance of the team or the Core, which reduces the incentive of agents to abandon their team. Applications of such methods include identifying influential features and sharing the costs of joint ventures or team formation. Unfortunately, using these solutions requires tackling a computational barrier as they are hard to compute, even in restricted settings. In this work, we show how cooperative game-theoretic solutions can be distilled into a learned model by training neural networks to propose fair and stable payoff allocations. We show that our approach creates models that can generalize to games far from the training distribution and can predict solutions for more players than observed during training. An important application of our framework is Explainable AI: our approach can be used to speed-up Shapley value computations on many instances.