 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Rueckert
A Domain-specific Perceptual Metric via Contrastive Self-supervised Representation: Applications on Natural and Medical Images
Dec 03, 2022
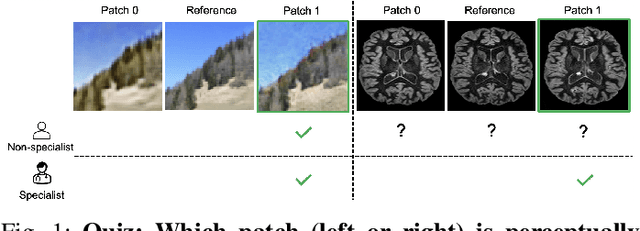
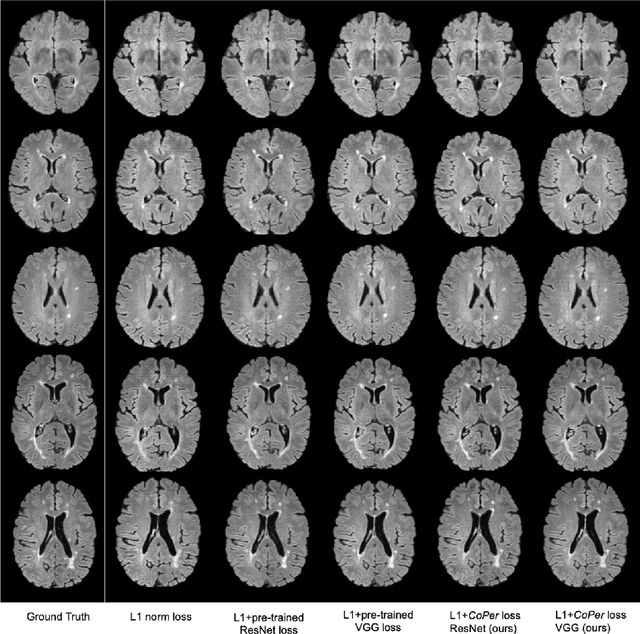
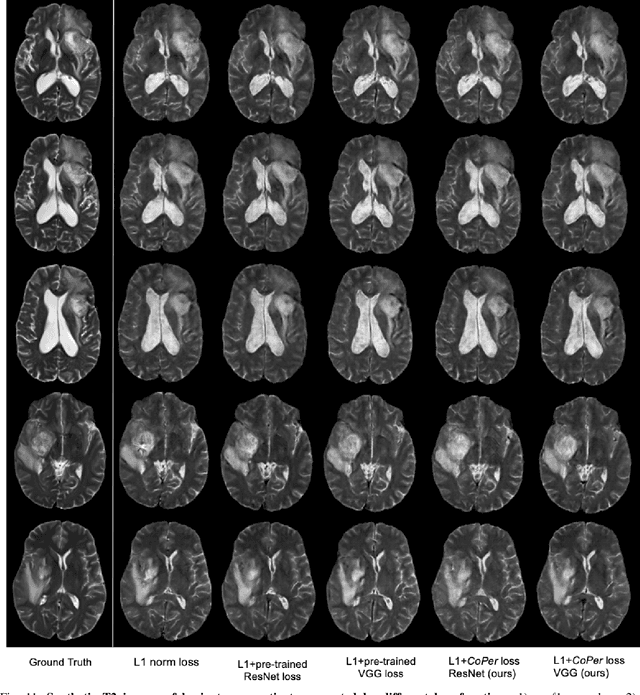
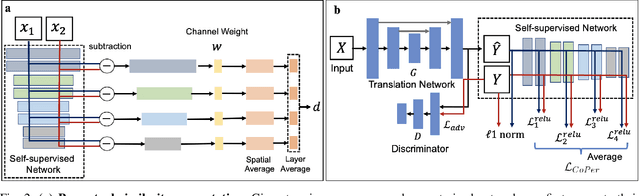
Quantifying the perceptual similarity of two images is a long-standing problem in low-level computer vision. The natural image domain commonly relies on supervised learning, e.g., a pre-trained VGG, to obtain a latent representation. However, due to domain shift, pre-trained models from the natural image domain might not apply to other image domains, such as medical imaging. Notably, in medical imaging, evaluating the perceptual similarity is exclusively performed by specialists trained extensively in diverse medical fields. Thus, medical imaging remains devoid of task-specific, objective perceptual measures. This work answers the question: Is it necessary to rely on supervised learning to obtain an effective representation that could measure perceptual similarity, or is self-supervision sufficient? To understand whether recent contrastive self-supervised representation (CSR) may come to the rescue, we start with natural images and systematically evaluate CSR as a metric across numerous contemporary architectures and tasks and compare them with existing methods. We find that in the natural image domain, CSR behaves on par with the supervised one on several perceptual tests as a metric, and in the medical domain, CSR better quantifies perceptual similarity concerning the experts' ratings. We also demonstrate that CSR can significantly improve image quality in two image synthesis tasks. Finally, our extensive results suggest that perceptuality is an emergent property of CSR, which can be adapted to many image domains without requiring annotations.
How Do Input Attributes Impact the Privacy Loss in Differential Privacy?
Nov 18, 2022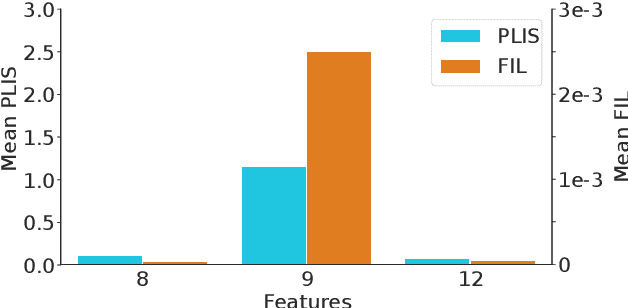

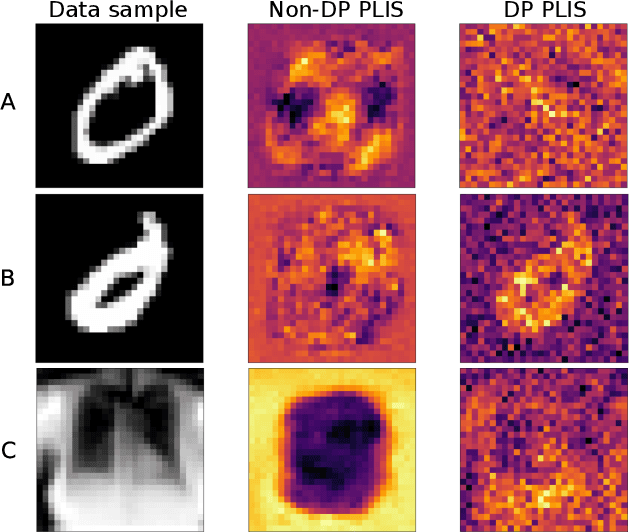

Differential privacy (DP) is typically formulated as a worst-case privacy guarantee over all individuals in a database. More recently, extensions to individual subjects or their attributes, have been introduced. Under the individual/per-instance DP interpretation, we study the connection between the per-subject gradient norm in DP neural networks and individual privacy loss and introduce a novel metric termed the Privacy Loss-Input Susceptibility (PLIS), which allows one to apportion the subject's privacy loss to their input attributes. We experimentally show how this enables the identification of sensitive attributes and of subjects at high risk of data reconstruction.
The Role of Local Alignment and Uniformity in Image-Text Contrastive Learning on Medical Images
Nov 14, 2022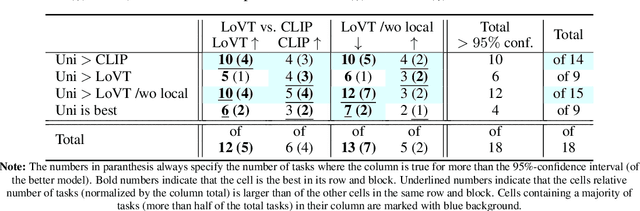
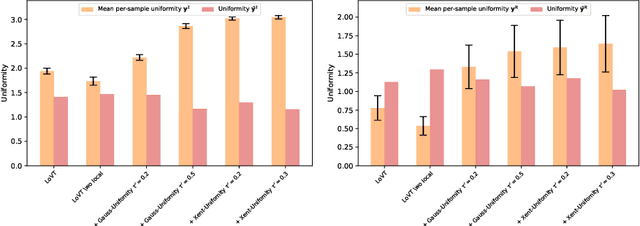
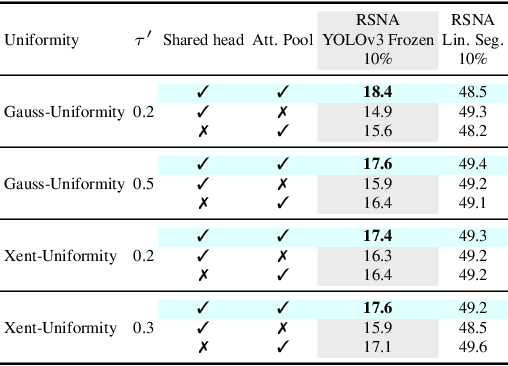
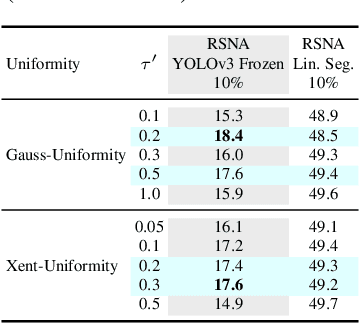
Image-text contrastive learning has proven effective for pretraining medical image models. When targeting localized downstream tasks like semantic segmentation or object detection, additional local contrastive losses that align image regions with sentences have shown promising results. We study how local contrastive losses are related to global (per-sample) contrastive losses and which effects they have on localized medical downstream tasks. Based on a theoretical comparison, we propose to remove some components of local losses and replace others by a novel distribution prior which enforces uniformity of representations within each sample. We empirically study this approach on chest X-ray tasks and find it to be very effective, outperforming methods without local losses on 12 of 18 tasks.
Exploiting segmentation labels and representation learning to forecast therapy response of PDAC patients
Nov 08, 2022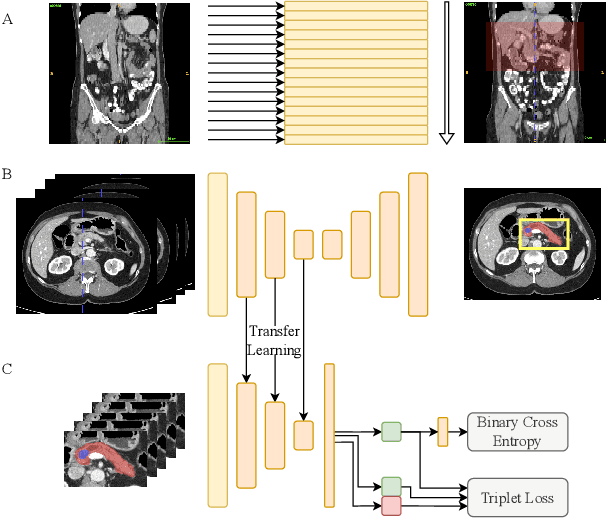
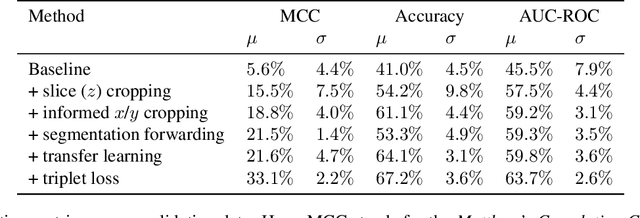

The prediction of pancreatic ductal adenocarcinoma therapy response is a clinically challenging and important task in this high-mortality tumour entity. The training of neural networks able to tackle this challenge is impeded by a lack of large datasets and the difficult anatomical localisation of the pancreas. Here, we propose a hybrid deep neural network pipeline to predict tumour response to initial chemotherapy which is based on the Response Evaluation Criteria in Solid Tumors (RECIST) score, a standardised method for cancer response evaluation by clinicians as well as tumour markers, and clinical evaluation of the patients. We leverage a combination of representation transfer from segmentation to classification, as well as localisation and representation learning. Our approach yields a remarkably data-efficient method able to predict treatment response with a ROC-AUC of 63.7% using only 477 datasets in total.
Automated analysis of diabetic retinopathy using vessel segmentation maps as inductive bias
Oct 28, 2022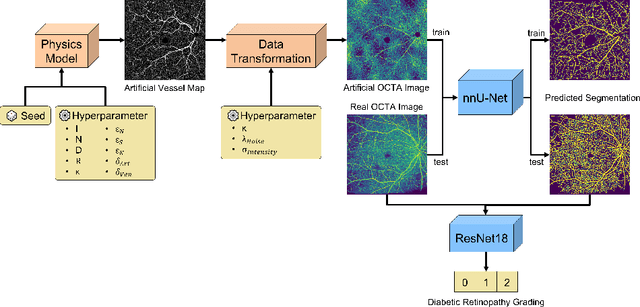

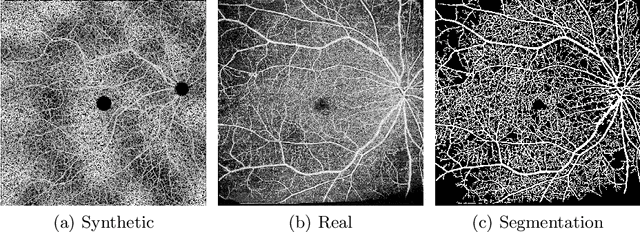
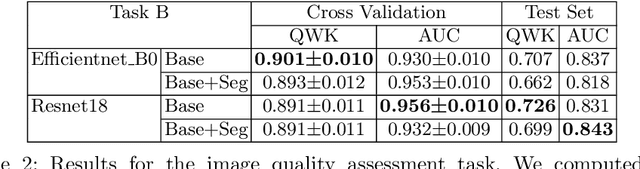
Recent studies suggest that early stages of diabetic retinopathy (DR) can be diagnosed by monitoring vascular changes in the deep vascular complex. In this work, we investigate a novel method for automated DR grading based on optical coherence tomography angiography (OCTA) images. Our work combines OCTA scans with their vessel segmentations, which then serve as inputs to task specific networks for lesion segmentation, image quality assessment and DR grading. For this, we generate synthetic OCTA images to train a segmentation network that can be directly applied on real OCTA data. We test our approach on MICCAI 2022's DR analysis challenge (DRAC). In our experiments, the proposed method performs equally well as the baseline model.
Generalised Likelihood Ratio Testing Adversaries through the Differential Privacy Lens
Oct 24, 2022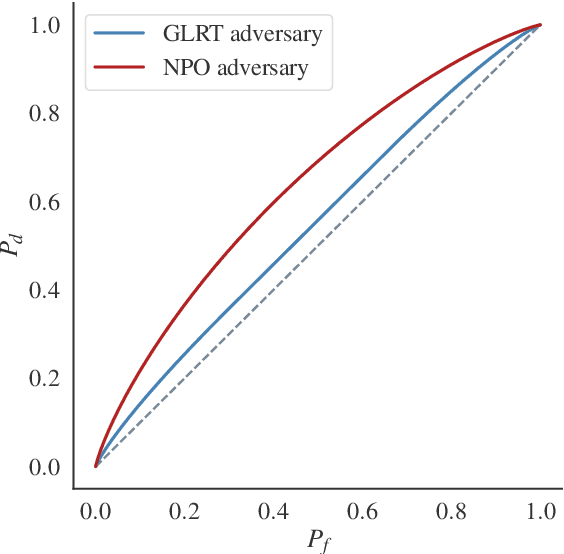
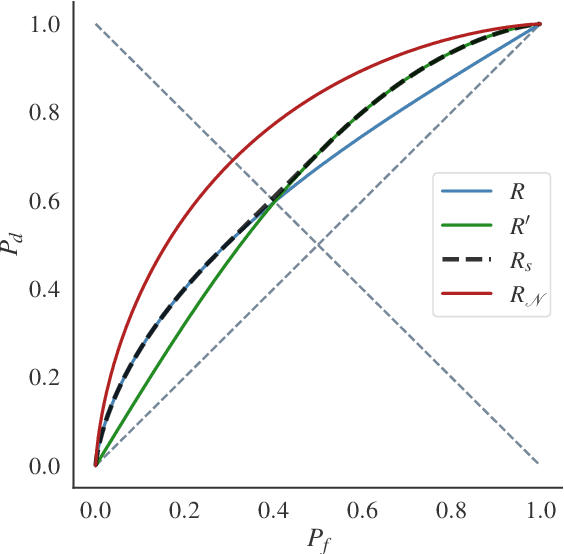
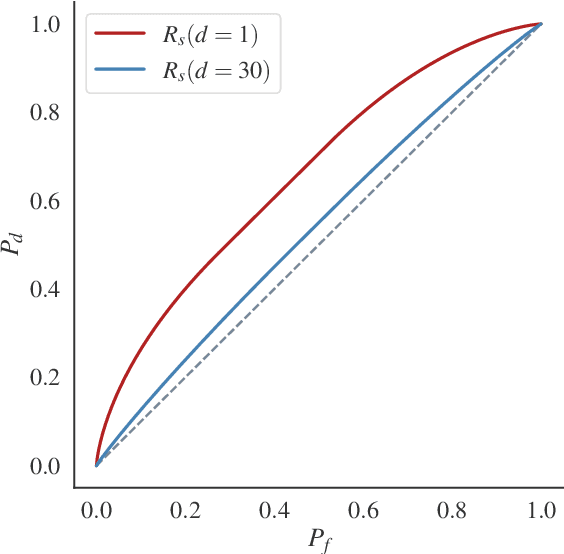
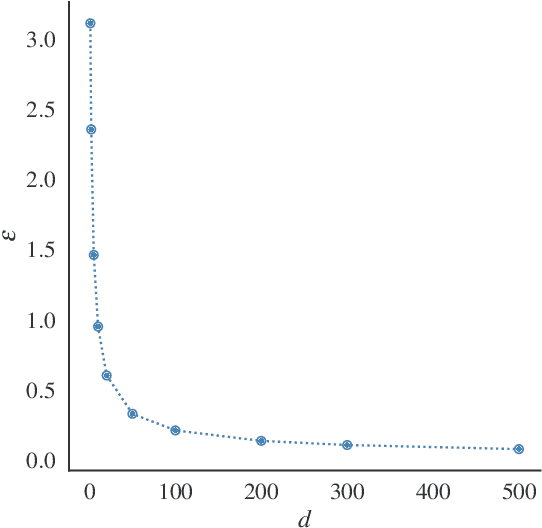
Differential Privacy (DP) provides tight upper bounds on the capabilities of optimal adversaries, but such adversaries are rarely encountered in practice. Under the hypothesis testing/membership inference interpretation of DP, we examine the Gaussian mechanism and relax the usual assumption of a Neyman-Pearson-Optimal (NPO) adversary to a Generalized Likelihood Test (GLRT) adversary. This mild relaxation leads to improved privacy guarantees, which we express in the spirit of Gaussian DP and $(\varepsilon, \delta)$-DP, including composition and sub-sampling results. We evaluate our results numerically and find them to match the theoretical upper bounds.
Label Noise-Robust Learning using a Confidence-Based Sieving Strategy
Oct 11, 2022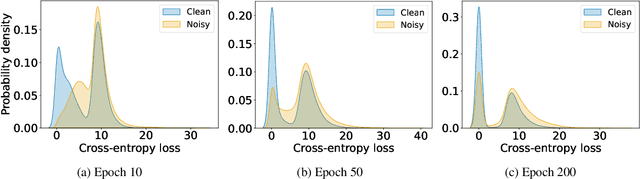
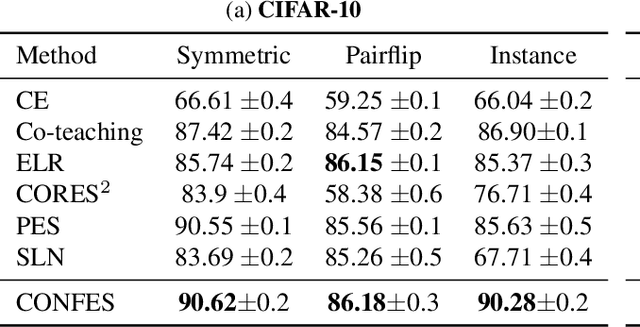
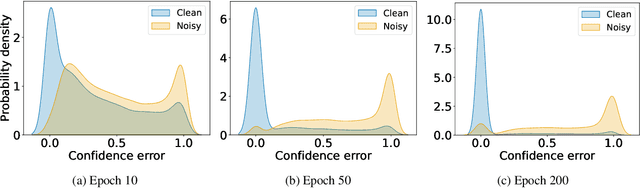
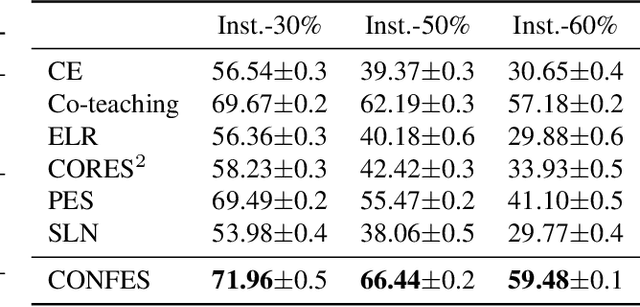
In learning tasks with label noise, boosting model robustness against overfitting is a pivotal challenge because the model eventually memorizes labels including the noisy ones. Identifying the samples with corrupted labels and preventing the model from learning them is a promising approach to address this challenge. Per-sample training loss is a previously studied metric that considers samples with small loss as clean samples on which the model should be trained. In this work, we first demonstrate the ineffectiveness of this small-loss trick. Then, we propose a novel discriminator metric called confidence error and a sieving strategy called CONFES to effectively differentiate between the clean and noisy samples. We experimentally illustrate the superior performance of our proposed approach compared to recent studies on various settings such as synthetic and real-world label noise.
Kernel Normalized Convolutional Networks for Privacy-Preserving Machine Learning
Sep 30, 2022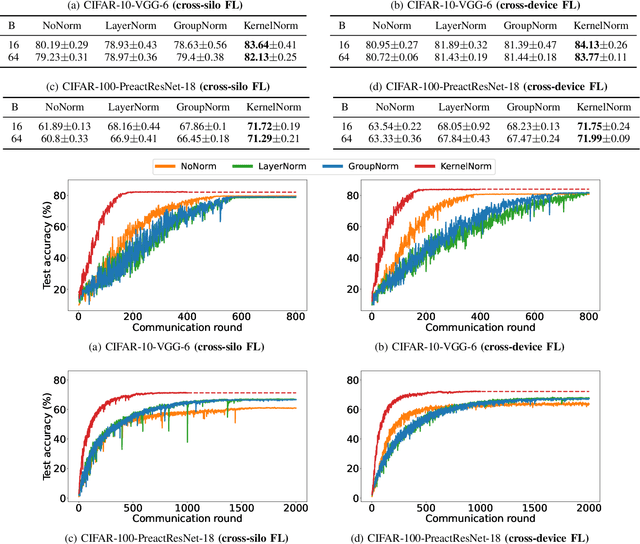
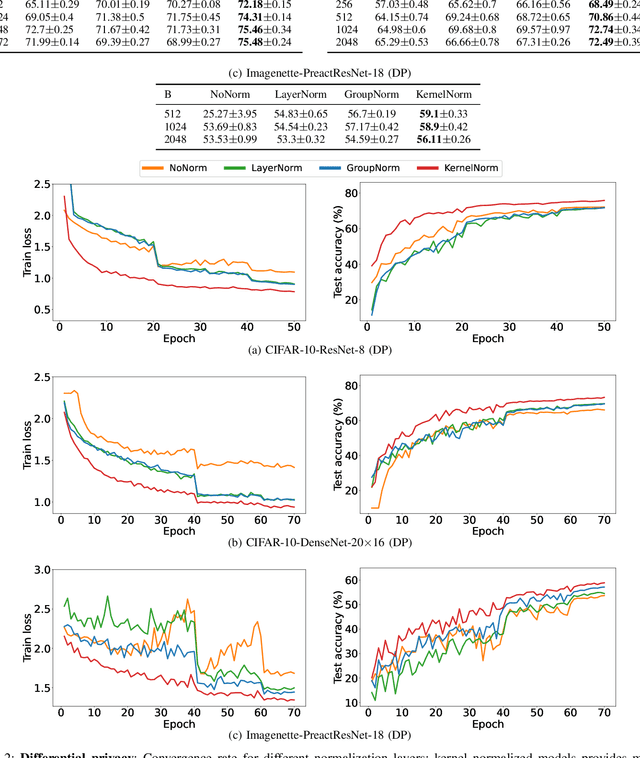
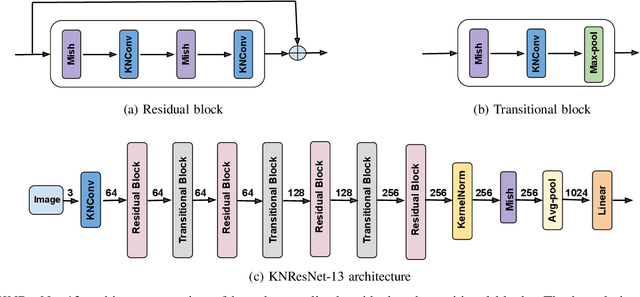

Normalization is an important but understudied challenge in privacy-related application domains such as federated learning (FL) and differential privacy (DP). While the unsuitability of batch normalization for FL and DP has already been shown, the impact of the other normalization methods on the performance of federated or differentially private models is not well-known. To address this, we draw a performance comparison among layer normalization (LayerNorm), group normalization (GroupNorm), and the recently proposed kernel normalization (KernelNorm) in FL and DP settings. Our results indicate LayerNorm and GroupNorm provide no performance gain compared to the baseline (i.e. no normalization) for shallow models, but they considerably enhance performance of deeper models. KernelNorm, on the other hand, significantly outperforms its competitors in terms of accuracy and convergence rate (or communication efficiency) for both shallow and deeper models. Given these key observations, we propose a kernel normalized ResNet architecture called KNResNet-13 for differentially private learning environments. Using the proposed architecture, we provide new state-of-the-art accuracy values on the CIFAR-10 and Imagenette datasets.
Artificial Intelligence-Based Image Reconstruction in Cardiac Magnetic Resonance
Sep 21, 2022Artificial intelligence (AI) and Machine Learning (ML) have shown great potential in improving the medical imaging workflow, from image acquisition and reconstruction to disease diagnosis and treatment. Particularly, in recent years, there has been a significant growth in the use of AI and ML algorithms, especially Deep Learning (DL) based methods, for medical image reconstruction. DL techniques have shown to be competitive and often superior over conventional reconstruction methods in terms of both reconstruction quality and computational efficiency. The use of DL-based image reconstruction also provides promising opportunities to transform the way cardiac images are acquired and reconstructed. In this chapter, we will review recent advances in DL-based reconstruction techniques for cardiac imaging, with emphasis on cardiac magnetic resonance (CMR) image reconstruction. We mainly focus on supervised DL methods for the application, including image post-processing techniques, model-driven approaches and k-space based methods. Current limitations, challenges and future opportunities of DL for cardiac image reconstruction are also discussed.
Review of data types and model dimensionality for cardiac DTI SMS-related artefact removal
Sep 20, 2022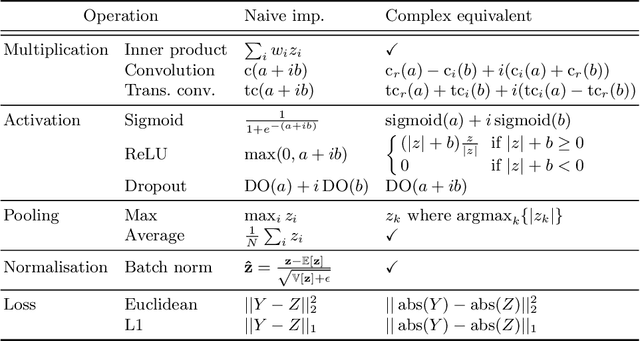
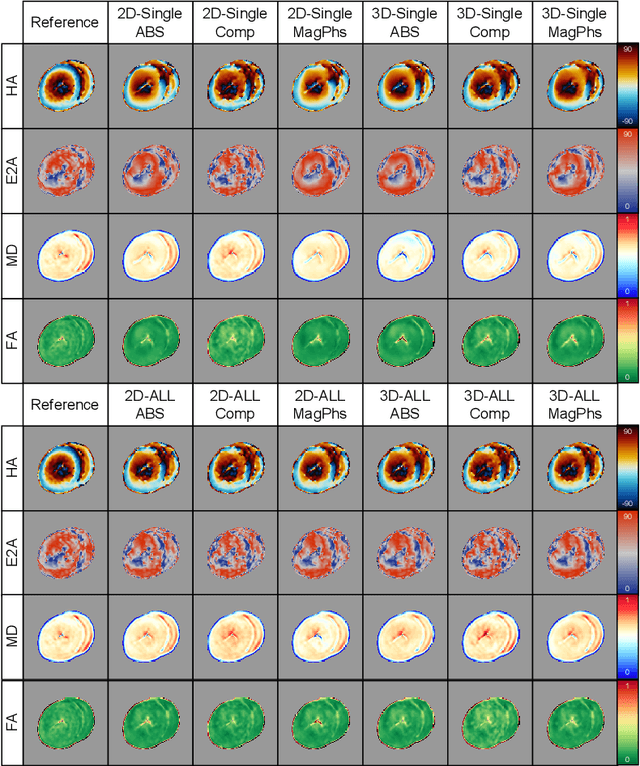
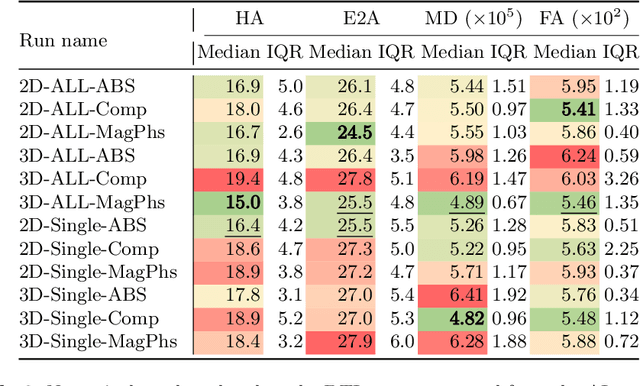
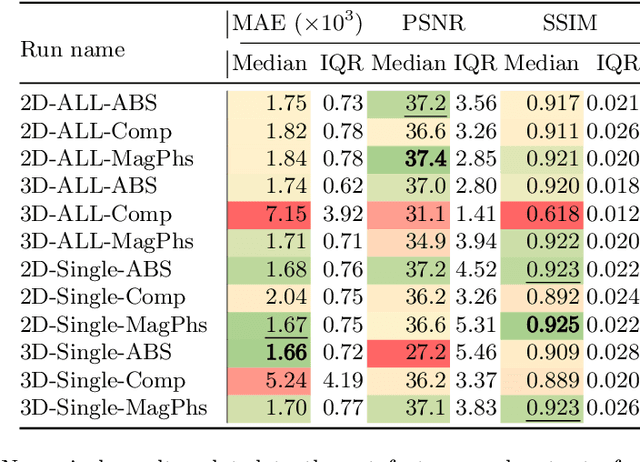
As diffusion tensor imaging (DTI) gains popularity in cardiac imaging due to its unique ability to non-invasively assess the cardiac microstructure, deep learning-based Artificial Intelligence is becoming a crucial tool in mitigating some of its drawbacks, such as the long scan times. As it often happens in fast-paced research environments, a lot of emphasis has been put on showing the capability of deep learning while often not enough time has been spent investigating what input and architectural properties would benefit cardiac DTI acceleration the most. In this work, we compare the effect of several input types (magnitude images vs complex images), multiple dimensionalities (2D vs 3D operations), and multiple input types (single slice vs multi-slice) on the performance of a model trained to remove artefacts caused by a simultaneous multi-slice (SMS) acquisition. Despite our initial intuition, our experiments show that, for a fixed number of parameters, simpler 2D real-valued models outperform their more advanced 3D or complex counterparts. The best performance is although obtained by a real-valued model trained using both the magnitude and phase components of the acquired data. We believe this behaviour to be due to real-valued models making better use of the lower number of parameters, and to 3D models not being able to exploit the spatial information because of the low SMS acceleration factor used in our experiments.