 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Localized Machine Unlearning Through the Lens of Memorization
Dec 03, 2024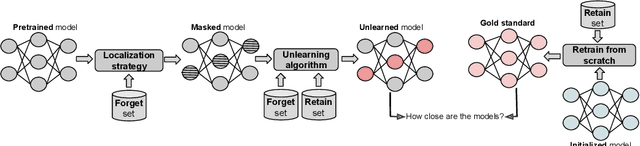
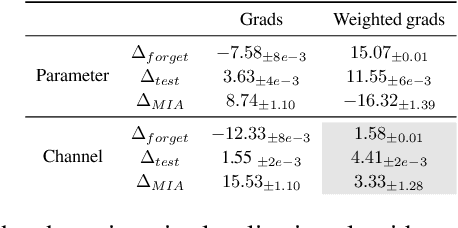
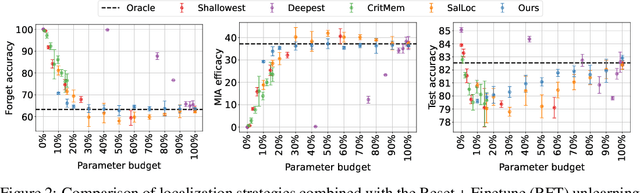
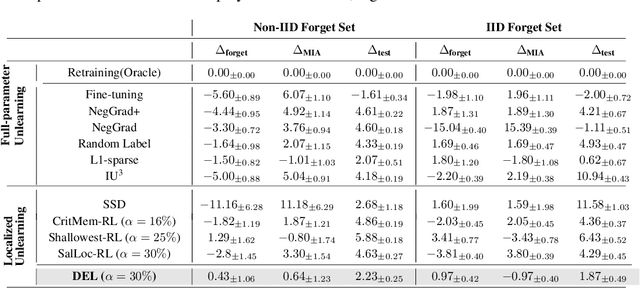
Machine unlearning refers to removing the influence of a specified subset of training data from a machine learning model, efficiently, after it has already been trained. This is important for key applications, including making the model more accurate by removing outdated, mislabeled, or poisoned data. In this work, we study localized unlearning, where the unlearning algorithm operates on a (small) identified subset of parameters. Drawing inspiration from the memorization literature, we propose an improved localization strategy that yields strong results when paired with existing unlearning algorithms. We also propose a new unlearning algorithm, Deletion by Example Localization (DEL), that resets the parameters deemed-to-be most critical according to our localization strategy, and then finetunes them. Our extensive experiments on different datasets, forget sets and metrics reveal that DEL sets a new state-of-the-art for unlearning metrics, against both localized and full-parameter methods, while modifying a small subset of parameters, and outperforms the state-of-the-art localized unlearning in terms of test accuracy too.
A Practical Guide to Fine-tuning Language Models with Limited Data
Nov 14, 2024Employing pre-trained Large Language Models (LLMs) has become the de facto standard in Natural Language Processing (NLP) despite their extensive data requirements. Motivated by the recent surge in research focused on training LLMs with limited data, particularly in low-resource domains and languages, this paper surveys recent transfer learning approaches to optimize model performance in downstream tasks where data is scarce. We first address initial and continued pre-training strategies to better leverage prior knowledge in unseen domains and languages. We then examine how to maximize the utility of limited data during fine-tuning and few-shot learning. The final section takes a task-specific perspective, reviewing models and methods suited for different levels of data scarcity. Our goal is to provide practitioners with practical guidelines for overcoming the challenges posed by constrained data while also highlighting promising directions for future research.
Topograph: An efficient Graph-Based Framework for Strictly Topology Preserving Image Segmentation
Nov 05, 2024



Topological correctness plays a critical role in many image segmentation tasks, yet most networks are trained using pixel-wise loss functions, such as Dice, neglecting topological accuracy. Existing topology-aware methods often lack robust topological guarantees, are limited to specific use cases, or impose high computational costs. In this work, we propose a novel, graph-based framework for topologically accurate image segmentation that is both computationally efficient and generally applicable. Our method constructs a component graph that fully encodes the topological information of both the prediction and ground truth, allowing us to efficiently identify topologically critical regions and aggregate a loss based on local neighborhood information. Furthermore, we introduce a strict topological metric capturing the homotopy equivalence between the union and intersection of prediction-label pairs. We formally prove the topological guarantees of our approach and empirically validate its effectiveness on binary and multi-class datasets. Our loss demonstrates state-of-the-art performance with up to fivefold faster loss computation compared to persistent homology methods.
Highly efficient non-rigid registration in k-space with application to cardiac Magnetic Resonance Imaging
Oct 24, 2024



In Magnetic Resonance Imaging (MRI), high temporal-resolved motion can be useful for image acquisition and reconstruction, MR-guided radiotherapy, dynamic contrast-enhancement, flow and perfusion imaging, and functional assessment of motion patterns in cardiovascular, abdominal, peristaltic, fetal, or musculoskeletal imaging. Conventionally, these motion estimates are derived through image-based registration, a particularly challenging task for complex motion patterns and high dynamic resolution. The accelerated scans in such applications result in imaging artifacts that compromise the motion estimation. In this work, we propose a novel self-supervised deep learning-based framework, dubbed the Local-All Pass Attention Network (LAPANet), for non-rigid motion estimation directly from the acquired accelerated Fourier space, i.e. k-space. The proposed approach models non-rigid motion as the cumulative sum of local translational displacements, following the Local All-Pass (LAP) registration technique. LAPANet was evaluated on cardiac motion estimation across various sampling trajectories and acceleration rates. Our results demonstrate superior accuracy compared to prior conventional and deep learning-based registration methods, accommodating as few as 2 lines/frame in a Cartesian trajectory and 3 spokes/frame in a non-Cartesian trajectory. The achieved high temporal resolution (less than 5 ms) for non-rigid motion opens new avenues for motion detection, tracking and correction in dynamic and real-time MRI applications.
Detecting Unforeseen Data Properties with Diffusion Autoencoder Embeddings using Spine MRI data
Oct 14, 2024



Deep learning has made significant strides in medical imaging, leveraging the use of large datasets to improve diagnostics and prognostics. However, large datasets often come with inherent errors through subject selection and acquisition. In this paper, we investigate the use of Diffusion Autoencoder (DAE) embeddings for uncovering and understanding data characteristics and biases, including biases for protected variables like sex and data abnormalities indicative of unwanted protocol variations. We use sagittal T2-weighted magnetic resonance (MR) images of the neck, chest, and lumbar region from 11186 German National Cohort (NAKO) participants. We compare DAE embeddings with existing generative models like StyleGAN and Variational Autoencoder. Evaluations on a large-scale dataset consisting of sagittal T2-weighted MR images of three spine regions show that DAE embeddings effectively separate protected variables such as sex and age. Furthermore, we used t-SNE visualization to identify unwanted variations in imaging protocols, revealing differences in head positioning. Our embedding can identify samples where a sex predictor will have issues learning the correct sex. Our findings highlight the potential of using advanced embedding techniques like DAEs to detect data quality issues and biases in medical imaging datasets. Identifying such hidden relations can enhance the reliability and fairness of deep learning models in healthcare applications, ultimately improving patient care and outcomes.
Towards Generalisable Time Series Understanding Across Domains
Oct 09, 2024



In natural language processing and computer vision, self-supervised pre-training on large datasets unlocks foundational model capabilities across domains and tasks. However, this potential has not yet been realised in time series analysis, where existing methods disregard the heterogeneous nature of time series characteristics. Time series are prevalent in many domains, including medicine, engineering, natural sciences, and finance, but their characteristics vary significantly in terms of variate count, inter-variate relationships, temporal dynamics, and sampling frequency. This inherent heterogeneity across domains prevents effective pre-training on large time series corpora. To address this issue, we introduce OTiS, an open model for general time series analysis, that has been specifically designed to handle multi-domain heterogeneity. We propose a novel pre-training paradigm including a tokeniser with learnable domain-specific signatures, a dual masking strategy to capture temporal causality, and a normalised cross-correlation loss to model long-range dependencies. Our model is pre-trained on a large corpus of 640,187 samples and 11 billion time points spanning 8 distinct domains, enabling it to analyse time series from any (unseen) domain. In comprehensive experiments across 15 diverse applications - including classification, regression, and forecasting - OTiS showcases its ability to accurately capture domain-specific data characteristics and demonstrates its competitiveness against state-of-the-art baselines. Our code and pre-trained weights are publicly available at https://github.com/oetu/otis.
Towards a vision foundation model for comprehensive assessment of Cardiac MRI
Oct 02, 2024



Cardiac magnetic resonance imaging (CMR), considered the gold standard for noninvasive cardiac assessment, is a diverse and complex modality requiring a wide variety of image processing tasks for comprehensive assessment of cardiac morphology and function. Advances in deep learning have enabled the development of state-of-the-art (SoTA) models for these tasks. However, model training is challenging due to data and label scarcity, especially in the less common imaging sequences. Moreover, each model is often trained for a specific task, with no connection between related tasks. In this work, we introduce a vision foundation model trained for CMR assessment, that is trained in a self-supervised fashion on 36 million CMR images. We then finetune the model in supervised way for 9 clinical tasks typical to a CMR workflow, across classification, segmentation, landmark localization, and pathology detection. We demonstrate improved accuracy and robustness across all tasks, over a range of available labeled dataset sizes. We also demonstrate improved few-shot learning with fewer labeled samples, a common challenge in medical image analyses. We achieve an out-of-box performance comparable to SoTA for most clinical tasks. The proposed method thus presents a resource-efficient, unified framework for CMR assessment, with the potential to accelerate the development of deep learning-based solutions for image analysis tasks, even with few annotated data available.
Differentially Private Active Learning: Balancing Effective Data Selection and Privacy
Oct 01, 2024



Active learning (AL) is a widely used technique for optimizing data labeling in machine learning by iteratively selecting, labeling, and training on the most informative data. However, its integration with formal privacy-preserving methods, particularly differential privacy (DP), remains largely underexplored. While some works have explored differentially private AL for specialized scenarios like online learning, the fundamental challenge of combining AL with DP in standard learning settings has remained unaddressed, severely limiting AL's applicability in privacy-sensitive domains. This work addresses this gap by introducing differentially private active learning (DP-AL) for standard learning settings. We demonstrate that naively integrating DP-SGD training into AL presents substantial challenges in privacy budget allocation and data utilization. To overcome these challenges, we propose step amplification, which leverages individual sampling probabilities in batch creation to maximize data point participation in training steps, thus optimizing data utilization. Additionally, we investigate the effectiveness of various acquisition functions for data selection under privacy constraints, revealing that many commonly used functions become impractical. Our experiments on vision and natural language processing tasks show that DP-AL can improve performance for specific datasets and model architectures. However, our findings also highlight the limitations of AL in privacy-constrained environments, emphasizing the trade-offs between privacy, model accuracy, and data selection accuracy.
Forecasting Disease Progression with Parallel Hyperplanes in Longitudinal Retinal OCT
Sep 30, 2024



Predicting future disease progression risk from medical images is challenging due to patient heterogeneity, and subtle or unknown imaging biomarkers. Moreover, deep learning (DL) methods for survival analysis are susceptible to image domain shifts across scanners. We tackle these issues in the task of predicting late dry Age-related Macular Degeneration (dAMD) onset from retinal OCT scans. We propose a novel DL method for survival prediction to jointly predict from the current scan a risk score, inversely related to time-to-conversion, and the probability of conversion within a time interval $t$. It uses a family of parallel hyperplanes generated by parameterizing the bias term as a function of $t$. In addition, we develop unsupervised losses based on intra-subject image pairs to ensure that risk scores increase over time and that future conversion predictions are consistent with AMD stage prediction using actual scans of future visits. Such losses enable data-efficient fine-tuning of the trained model on new unlabeled datasets acquired with a different scanner. Extensive evaluation on two large datasets acquired with different scanners resulted in a mean AUROCs of 0.82 for Dataset-1 and 0.83 for Dataset-2, across prediction intervals of 6,12 and 24 months.
Universal Topology Refinement for Medical Image Segmentation with Polynomial Feature Synthesis
Sep 15, 2024Although existing medical image segmentation methods provide impressive pixel-wise accuracy, they often neglect topological correctness, making their segmentations unusable for many downstream tasks. One option is to retrain such models whilst including a topology-driven loss component. However, this is computationally expensive and often impractical. A better solution would be to have a versatile plug-and-play topology refinement method that is compatible with any domain-specific segmentation pipeline. Directly training a post-processing model to mitigate topological errors often fails as such models tend to be biased towards the topological errors of a target segmentation network. The diversity of these errors is confined to the information provided by a labelled training set, which is especially problematic for small datasets. Our method solves this problem by training a model-agnostic topology refinement network with synthetic segmentations that cover a wide variety of topological errors. Inspired by the Stone-Weierstrass theorem, we synthesize topology-perturbation masks with randomly sampled coefficients of orthogonal polynomial bases, which ensures a complete and unbiased representation. Practically, we verified the efficiency and effectiveness of our methods as being compatible with multiple families of polynomial bases, and show evidence that our universal plug-and-play topology refinement network outperforms both existing topology-driven learning-based and post-processing methods. We also show that combining our method with learning-based models provides an effortless add-on, which can further improve the performance of existing approaches.