 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Compass: Predicting Transfer Learning Success in Offensive Language Detection with Cultural Features
Oct 10, 2023



The increasing ubiquity of language technology necessitates a shift towards considering cultural diversity in the machine learning realm, particularly for subjective tasks that rely heavily on cultural nuances, such as Offensive Language Detection (OLD). Current understanding underscores that these tasks are substantially influenced by cultural values, however, a notable gap exists in determining if cultural features can accurately predict the success of cross-cultural transfer learning for such subjective tasks. Addressing this, our study delves into the intersection of cultural features and transfer learning effectiveness. The findings reveal that cultural value surveys indeed possess a predictive power for cross-cultural transfer learning success in OLD tasks and that it can be further improved using offensive word distance. Based on these results, we advocate for the integration of cultural information into datasets. Additionally, we recommend leveraging data sources rich in cultural information, such as surveys, to enhance cultural adaptability. Our research signifies a step forward in the quest for more inclusive, culturally sensitive language technologies.
Geo-Encoder: A Chunk-Argument Bi-Encoder Framework for Chinese Geographic Re-Ranking
Sep 04, 2023



Chinese geographic re-ranking task aims to find the most relevant addresses among retrieved candidates, which is crucial for location-related services such as navigation maps. Unlike the general sentences, geographic contexts are closely intertwined with geographical concepts, from general spans (e.g., province) to specific spans (e.g., road). Given this feature, we propose an innovative framework, namely Geo-Encoder, to more effectively integrate Chinese geographical semantics into re-ranking pipelines. Our methodology begins by employing off-the-shelf tools to associate text with geographical spans, treating them as chunking units. Then, we present a multi-task learning module to simultaneously acquire an effective attention matrix that determines chunk contributions to extra semantic representations. Furthermore, we put forth an asynchronous update mechanism for the proposed addition task, aiming to guide the model capable of effectively focusing on specific chunks. Experiments on two distinct Chinese geographic re-ranking datasets, show that the Geo-Encoder achieves significant improvements when compared to state-of-the-art baselines. Notably, it leads to a substantial improvement in the Hit@1 score of MGEO-BERT, increasing it by 6.22% from 62.76 to 68.98 on the GeoTES dataset.
On Evaluating Multilingual Compositional Generalization with Translated Datasets
Jun 20, 2023Compositional generalization allows efficient learning and human-like inductive biases. Since most research investigating compositional generalization in NLP is done on English, important questions remain underexplored. Do the necessary compositional generalization abilities differ across languages? Can models compositionally generalize cross-lingually? As a first step to answering these questions, recent work used neural machine translation to translate datasets for evaluating compositional generalization in semantic parsing. However, we show that this entails critical semantic distortion. To address this limitation, we craft a faithful rule-based translation of the MCWQ dataset from English to Chinese and Japanese. Even with the resulting robust benchmark, which we call MCWQ-R, we show that the distribution of compositions still suffers due to linguistic divergences, and that multilingual models still struggle with cross-lingual compositional generalization. Our dataset and methodology will be useful resources for the study of cross-lingual compositional generalization in other tasks.
What does the Failure to Reason with "Respectively" in Zero/Few-Shot Settings Tell Us about Language Models?
May 31, 2023



Humans can effortlessly understand the coordinate structure of sentences such as "Niels Bohr and Kurt Cobain were born in Copenhagen and Seattle, respectively". In the context of natural language inference (NLI), we examine how language models (LMs) reason with respective readings (Gawron and Kehler, 2004) from two perspectives: syntactic-semantic and commonsense-world knowledge. We propose a controlled synthetic dataset WikiResNLI and a naturally occurring dataset NatResNLI to encompass various explicit and implicit realizations of "respectively". We show that fine-tuned NLI models struggle with understanding such readings without explicit supervision. While few-shot learning is easy in the presence of explicit cues, longer training is required when the reading is evoked implicitly, leaving models to rely on common sense inferences. Furthermore, our fine-grained analysis indicates models fail to generalize across different constructions. To conclude, we demonstrate that LMs still lag behind humans in generalizing to the long tail of linguistic constructions.
What's the Meaning of Superhuman Performance in Today's NLU?
May 15, 2023



In the last five years, there has been a significant focus in Natural Language Processing (NLP) on developing larger Pretrained Language Models (PLMs) and introducing benchmarks such as SuperGLUE and SQuAD to measure their abilities in language understanding, reasoning, and reading comprehension. These PLMs have achieved impressive results on these benchmarks, even surpassing human performance in some cases. This has led to claims of superhuman capabilities and the provocative idea that certain tasks have been solved. In this position paper, we take a critical look at these claims and ask whether PLMs truly have superhuman abilities and what the current benchmarks are really evaluating. We show that these benchmarks have serious limitations affecting the comparison between humans and PLMs and provide recommendations for fairer and more transparent benchmarks.
Pay More Attention to Relation Exploration for Knowledge Base Question Answering
May 03, 2023



Knowledge base question answering (KBQA) is a challenging task that aims to retrieve correct answers from large-scale knowledge bases. Existing attempts primarily focus on entity representation and final answer reasoning, which results in limited supervision for this task. Moreover, the relations, which empirically determine the reasoning path selection, are not fully considered in recent advancements. In this study, we propose a novel framework, RE-KBQA, that utilizes relations in the knowledge base to enhance entity representation and introduce additional supervision. We explore guidance from relations in three aspects, including (1) distinguishing similar entities by employing a variational graph auto-encoder to learn relation importance; (2) exploring extra supervision by predicting relation distributions as soft labels with a multi-task scheme; (3) designing a relation-guided re-ranking algorithm for post-processing. Experimental results on two benchmark datasets demonstrate the effectiveness and superiority of our framework, improving the F1 score by 5.7% from 40.5 to 46.3 on CWQ and 5.8% from 62.8 to 68.5 on WebQSP, better or on par with state-of-the-art methods.
Cross-Cultural Transfer Learning for Chinese Offensive Language Detection
Mar 31, 2023Detecting offensive language is a challenging task. Generalizing across different cultures and languages becomes even more challenging: besides lexical, syntactic and semantic differences, pragmatic aspects such as cultural norms and sensitivities, which are particularly relevant in this context, vary greatly. In this paper, we target Chinese offensive language detection and aim to investigate the impact of transfer learning using offensive language detection data from different cultural backgrounds, specifically Korean and English. We find that culture-specific biases in what is considered offensive negatively impact the transferability of language models (LMs) and that LMs trained on diverse cultural data are sensitive to different features in Chinese offensive language detection. In a few-shot learning scenario, however, our study shows promising prospects for non-English offensive language detection with limited resources. Our findings highlight the importance of cross-cultural transfer learning in improving offensive language detection and promoting inclusive digital spaces.
Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study
Mar 31, 2023



The recent release of ChatGPT has garnered widespread recognition for its exceptional ability to generate human-like responses in dialogue. Given its usage by users from various nations and its training on a vast multilingual corpus that incorporates diverse cultural and societal norms, it is crucial to evaluate its effectiveness in cultural adaptation. In this paper, we investigate the underlying cultural background of ChatGPT by analyzing its responses to questions designed to quantify human cultural differences. Our findings suggest that, when prompted with American context, ChatGPT exhibits a strong alignment with American culture, but it adapts less effectively to other cultural contexts. Furthermore, by using different prompts to probe the model, we show that English prompts reduce the variance in model responses, flattening out cultural differences and biasing them towards American culture. This study provides valuable insights into the cultural implications of ChatGPT and highlights the necessity of greater diversity and cultural awareness in language technologies.
A Two-Sided Discussion of Preregistration of NLP Research
Feb 20, 2023Van Miltenburg et al. (2021) suggest NLP research should adopt preregistration to prevent fishing expeditions and to promote publication of negative results. At face value, this is a very reasonable suggestion, seemingly solving many methodological problems with NLP research. We discuss pros and cons -- some old, some new: a) Preregistration is challenged by the practice of retrieving hypotheses after the results are known; b) preregistration may bias NLP toward confirmatory research; c) preregistration must allow for reclassification of research as exploratory; d) preregistration may increase publication bias; e) preregistration may increase flag-planting; f) preregistration may increase p-hacking; and finally, g) preregistration may make us less risk tolerant. We cast our discussion as a dialogue, presenting both sides of the debate.
Towards Climate Awareness in NLP Research
May 16, 2022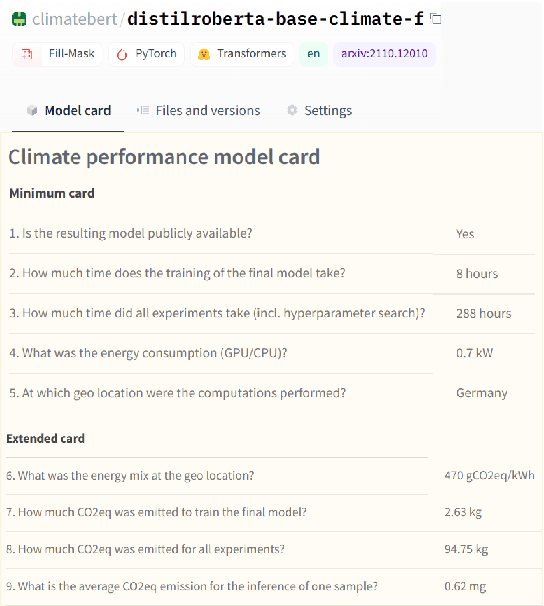

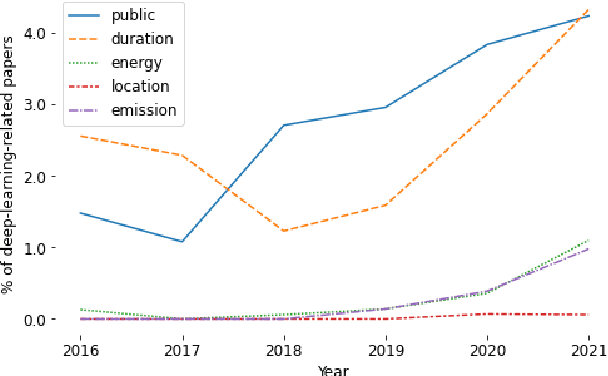

The climate impact of AI, and NLP research in particular, has become a serious issue given the enormous amount of energy that is increasingly being used for training and running computational models. Consequently, increasing focus is placed on efficient NLP. However, this important initiative lacks simple guidelines that would allow for systematic climate reporting of NLP research. We argue that this deficiency is one of the reasons why very few publications in NLP report key figures that would allow a more thorough examination of environmental impact. As a remedy, we propose a climate performance model card with the primary purpose of being practically usable with only limited information about experiments and the underlying computer hardware. We describe why this step is essential to increase awareness about the environmental impact of NLP research and, thereby, paving the way for more thorough discussions.