 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANDEM: Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo
Nov 14, 2021

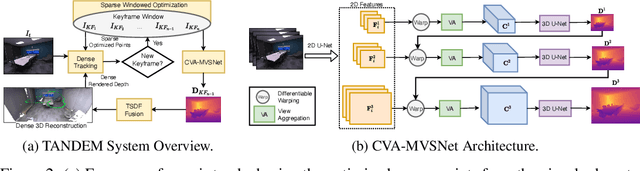
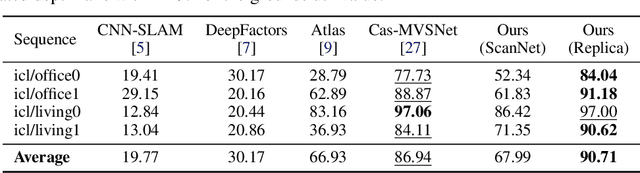
In this paper, we present TANDEM a real-time monocular tracking and dense mapping framework. For pose estimation, TANDEM performs photometric bundle adjustment based on a sliding window of keyframes. To increase the robustness, we propose a novel tracking front-end that performs dense direct image alignment using depth maps rendered from a global model that is built incrementally from dense depth predictions. To predict the dense depth maps, we propose Cascade View-Aggregation MVSNet (CVA-MVSNet) that utilizes the entire active keyframe window by hierarchically constructing 3D cost volumes with adaptive view aggregation to balance the different stereo baselines between the keyframes. Finally, the predicted depth maps are fused into a consistent global map represented as a truncated signed distance function (TSDF) voxel grid. Our experimental results show that TANDEM outperforms other state-of-the-art traditional and learning-based monocular visual odometry (VO) methods in terms of camera tracking. Moreover, TANDEM shows state-of-the-art real-time 3D reconstruction performance.
Multidirectional Conjugate Gradients for Scalable Bundle Adjustment
Oct 08, 2021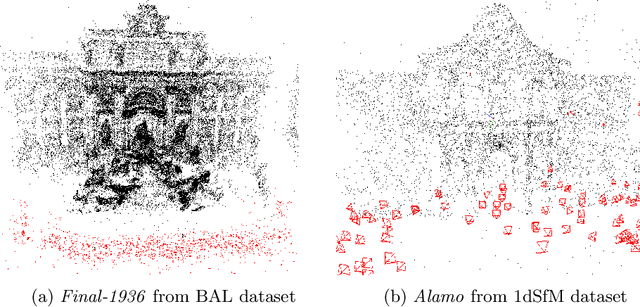
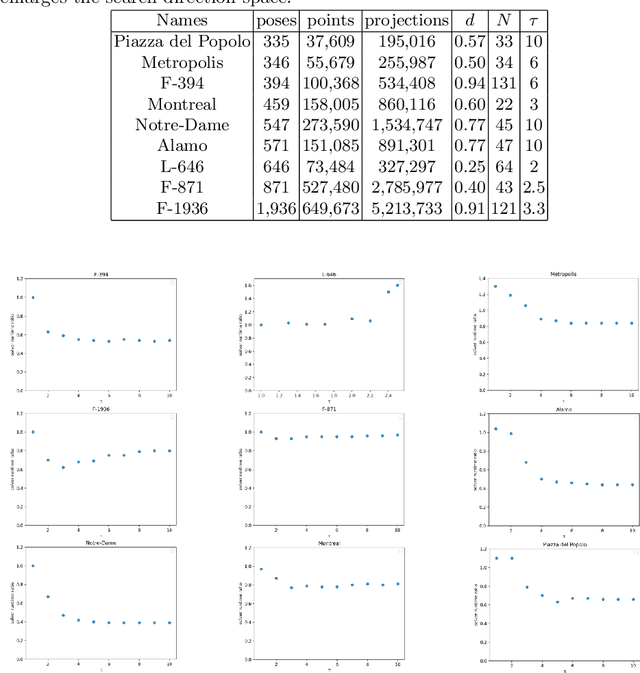
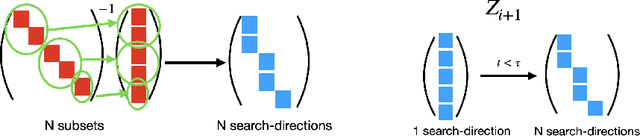
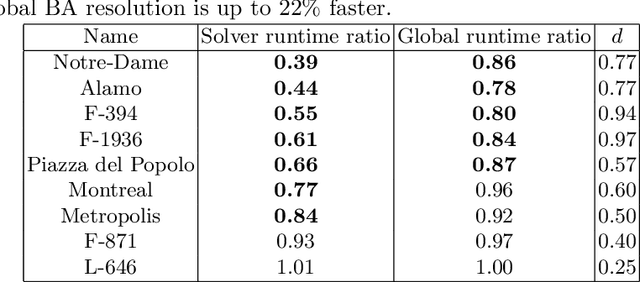
We revisit the problem of large-scale bundle adjustment and propose a technique called Multidirectional Conjugate Gradients that accelerates the solution of the normal equation by up to 61%. The key idea is that we enlarge the search space of classical preconditioned conjugate gradients to include multiple search directions. As a consequence, the resulting algorithm requires fewer iterations, leading to a significant speedup of large-scale reconstruction, in particular for denser problems where traditional approaches notoriously struggle. We provide a number of experimental ablation studies revealing the robustness to variations in the hyper-parameters and the speedup as a function of problem density.
Sparse Quadratic Optimisation over the Stiefel Manifold with Application to Permutation Synchronisation
Sep 30, 2021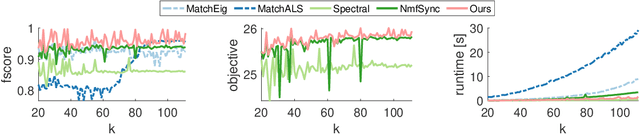
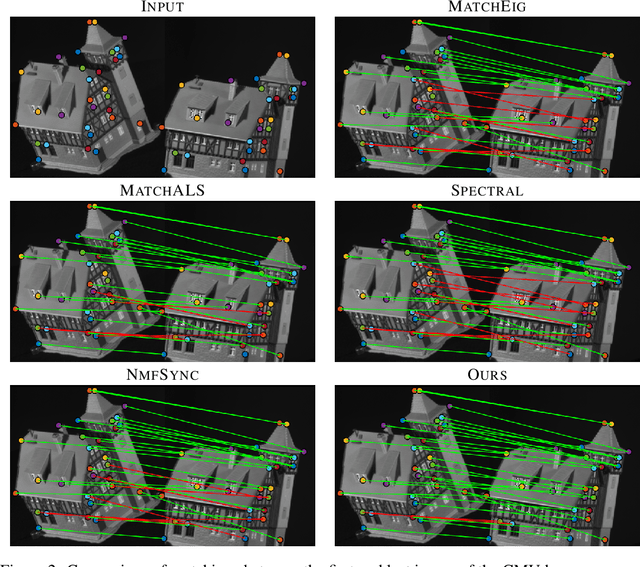
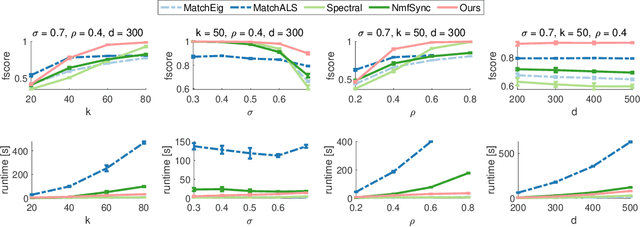
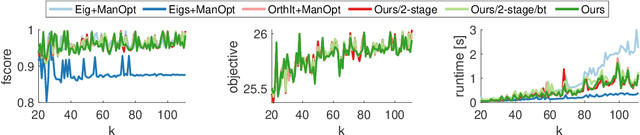
We address the non-convex optimisation problem of finding a sparse matrix on the Stiefel manifold (matrices with mutually orthogonal columns of unit length) that maximises (or minimises) a quadratic objective function. Optimisation problems on the Stiefel manifold occur for example in spectral relaxations of various combinatorial problems, such as graph matching, clustering, or permutation synchronisation. Although sparsity is a desirable property in such settings, it is mostly neglected in spectral formulations since existing solvers, e.g. based on eigenvalue decomposition, are unable to account for sparsity while at the same time maintaining global optimality guarantees. We fill this gap and propose a simple yet effective sparsity-promoting modification of the Orthogonal Iteration algorithm for finding the dominant eigenspace of a matrix. By doing so, we can guarantee that our method finds a Stiefel matrix that is globally optimal with respect to the quadratic objective function, while in addition being sparse. As a motivating application we consider the task of permutation synchronisation, which can be understood as a constrained clustering problem that has particular relevance for matching multiple images or 3D shapes in computer vision, computer graphics, and beyond. We demonstrate that the proposed approach outperforms previous methods in this domain.
Scene Graph Generation for Better Image Captioning?
Sep 23, 2021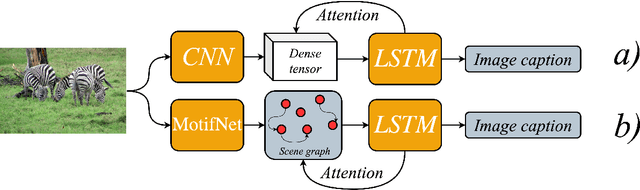
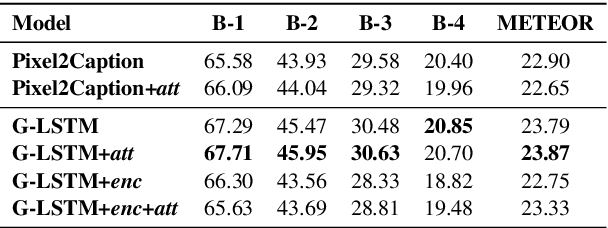
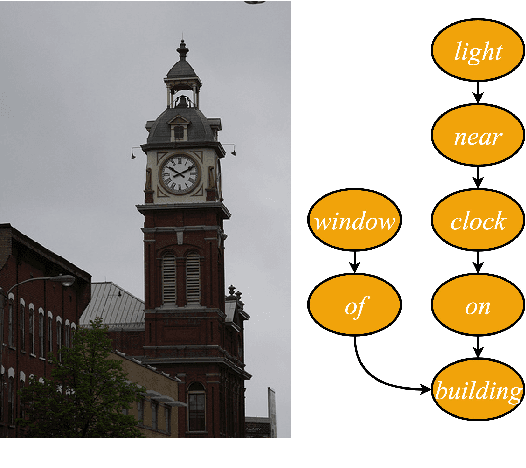
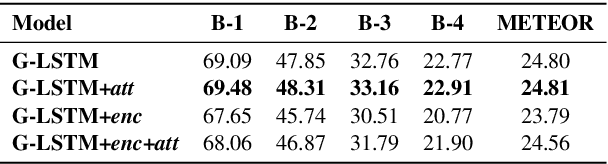
We investigate the incorporation of visual relationships into the task of supervised image caption generation by proposing a model that leverages detected objects and auto-generated visual relationships to describe images in natural language. To do so, we first generate a scene graph from raw image pixels by identifying individual objects and visual relationships between them. This scene graph then serves as input to our graph-to-text model, which generates the final caption. In contrast to previous approaches, our model thus explicitly models the detection of objects and visual relationships in the image. For our experiments we construct a new dataset from the intersection of Visual Genome and MS COCO, consisting of images with both a corresponding gold scene graph and human-authored caption. Our results show that our methods outperform existing state-of-the-art end-to-end models that generate image descriptions directly from raw input pixels when compared in terms of the BLEU and METEOR evaluation metrics.
Towards Robust Monocular Visual Odometry for Flying Robots on Planetary Missions
Sep 12, 2021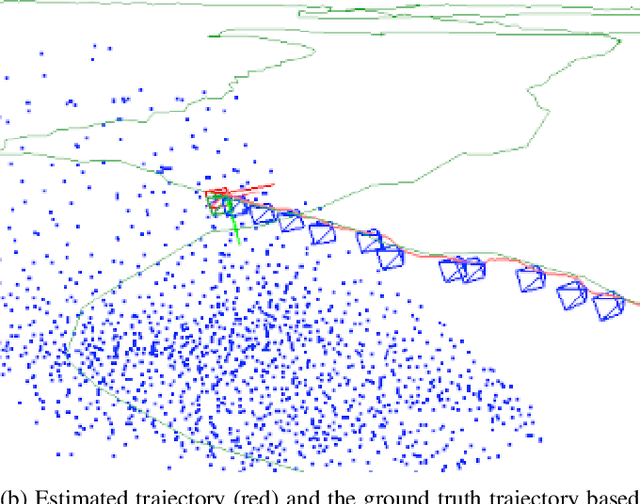
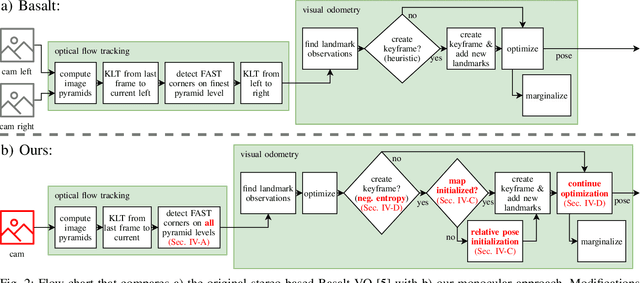
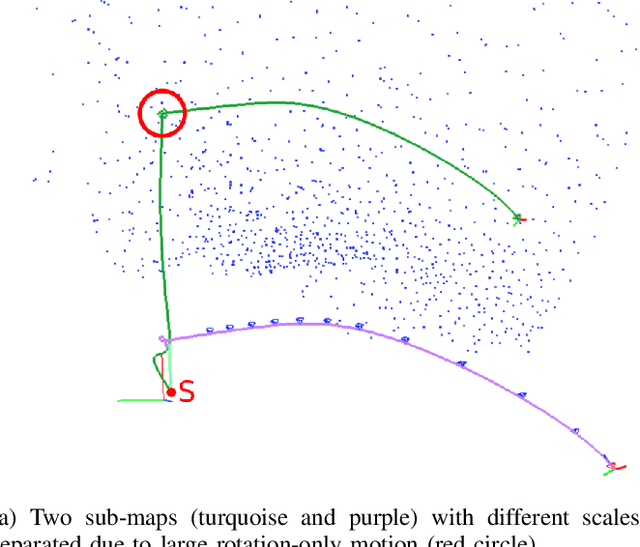
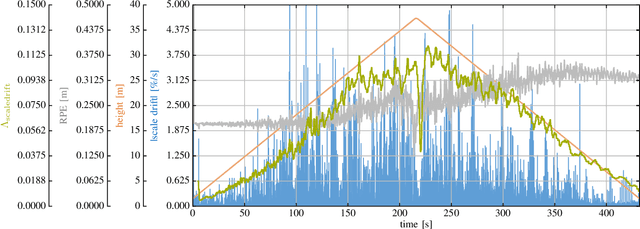
In the future, extraterrestrial expeditions will not only be conducted by rovers but also by flying robots. The technical demonstration drone Ingenuity, that just landed on Mars, will mark the beginning of a new era of exploration unhindered by terrain traversability. Robust self-localization is crucial for that. Cameras that are lightweight, cheap and information-rich sensors are already used to estimate the ego-motion of vehicles. However, methods proven to work in man-made environments cannot simply be deployed on other planets. The highly repetitive textures present in the wastelands of Mars pose a huge challenge to descriptor matching based approaches. In this paper, we present an advanced robust monocular odometry algorithm that uses efficient optical flow tracking to obtain feature correspondences between images and a refined keyframe selection criterion. In contrast to most other approaches, our framework can also handle rotation-only motions that are particularly challenging for monocular odometry systems. Furthermore, we present a novel approach to estimate the current risk of scale drift based on a principal component analysis of the relative translation information matrix. This way we obtain an implicit measure of uncertainty. We evaluate the validity of our approach on all sequences of a challenging real-world dataset captured in a Mars-like environment and show that it outperforms state-of-the-art approaches.
Square Root Marginalization for Sliding-Window Bundle Adjustment
Sep 05, 2021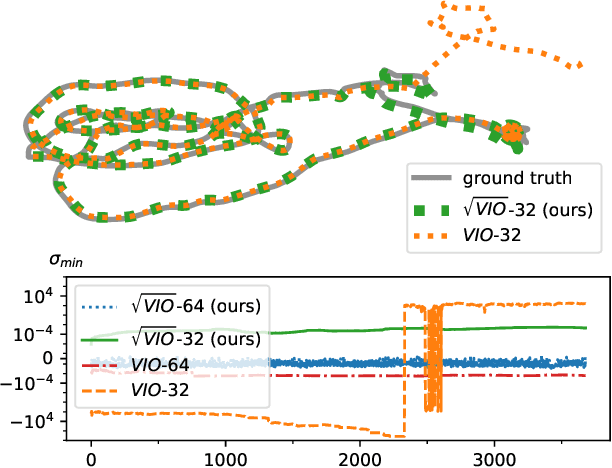
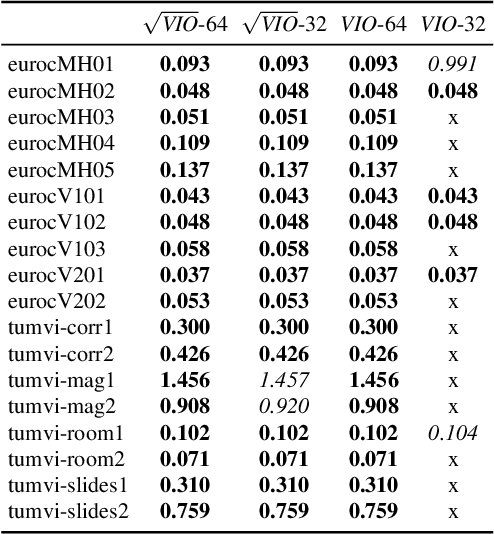
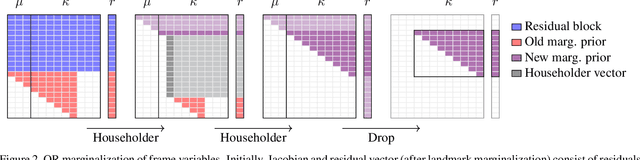
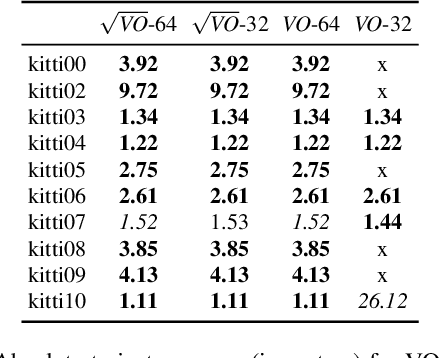
In this paper we propose a novel square root sliding-window bundle adjustment suitable for real-time odometry applications. The square root formulation pervades three major aspects of our optimization-based sliding-window estimator: for bundle adjustment we eliminate landmark variables with nullspace projection; to store the marginalization prior we employ a matrix square root of the Hessian; and when marginalizing old poses we avoid forming normal equations and update the square root prior directly with a specialized QR decomposition. We show that the proposed square root marginalization is algebraically equivalent to the conventional use of Schur complement (SC) on the Hessian. Moreover, it elegantly deals with rank-deficient Jacobians producing a prior equivalent to SC with Moore-Penrose inverse. Our evaluation of visual and visual-inertial odometry on real-world datasets demonstrates that the proposed estimator is 36% faster than the baseline. It furthermore shows that in single precision, conventional Hessian-based marginalization leads to numeric failures and reduced accuracy. We analyse numeric properties of the marginalization prior to explain why our square root form does not suffer from the same effect and therefore entails superior performance.
Dive into Layers: Neural Network Capacity Bounding using Algebraic Geometry
Sep 03, 2021
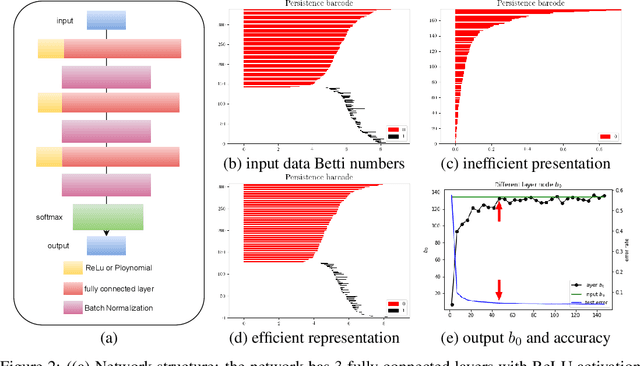
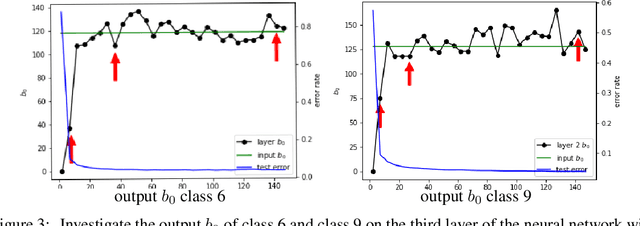
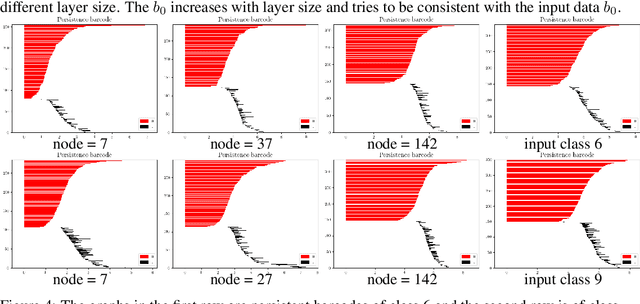
The empirical results suggest that the learnability of a neural network is directly related to its size. To mathematically prove this, we borrow a tool in topological algebra: Betti numbers to measure the topological geometric complexity of input data and the neural network. By characterizing the expressive capacity of a neural network with its topological complexity, we conduct a thorough analysis and show that the network's expressive capacity is limited by the scale of its layers. Further, we derive the upper bounds of the Betti numbers on each layer within the network. As a result, the problem of architecture selection of a neural network is transformed to determining the scale of the network that can represent the input data complexity. With the presented results, the architecture selection of a fully connected network boils down to choosing a suitable size of the network such that it equips the Betti numbers that are not smaller than the Betti numbers of the input data. We perform the experiments on a real-world dataset MNIST and the results verify our analysis and conclusion. The code will be publicly available.
TUM-VIE: The TUM Stereo Visual-Inertial Event Dataset
Aug 16, 2021
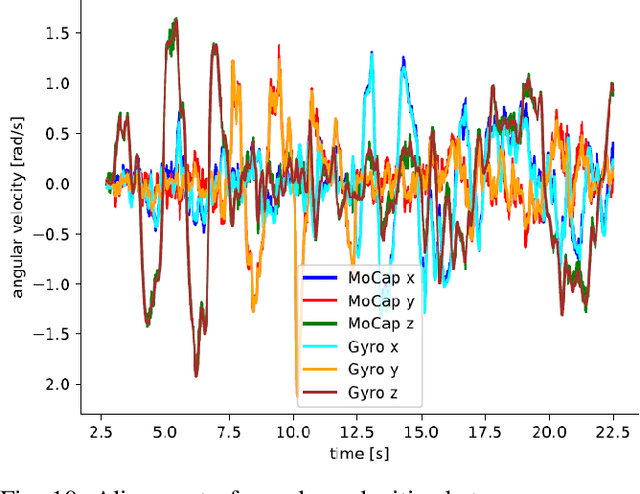

Event cameras are bio-inspired vision sensors which measure per pixel brightness changes. They offer numerous benefits over traditional, frame-based cameras, including low latency, high dynamic range, high temporal resolution and low power consumption. Thus, these sensors are suited for robotics and virtual reality applications. To foster the development of 3D perception and navigation algorithms with event cameras, we present the TUM-VIE dataset. It consists of a large variety of handheld and head-mounted sequences in indoor and outdoor environments, including rapid motion during sports and high dynamic range scenarios. The dataset contains stereo event data, stereo grayscale frames at 20Hz as well as IMU data at 200Hz. Timestamps between all sensors are synchronized in hardware. The event cameras contain a large sensor of 1280x720 pixels, which is significantly larger than the sensors used in existing stereo event datasets (at least by a factor of ten). We provide ground truth poses from a motion capture system at 120Hz during the beginning and end of each sequence, which can be used for trajectory evaluation. TUM-VIE includes challenging sequences where state-of-the art visual SLAM algorithms either fail or result in large drift. Hence, our dataset can help to push the boundary of future research on event-based visual-inertial perception algorithms.
Explicit Pairwise Factorized Graph Neural Network for Semi-Supervised Node Classification
Jul 27, 2021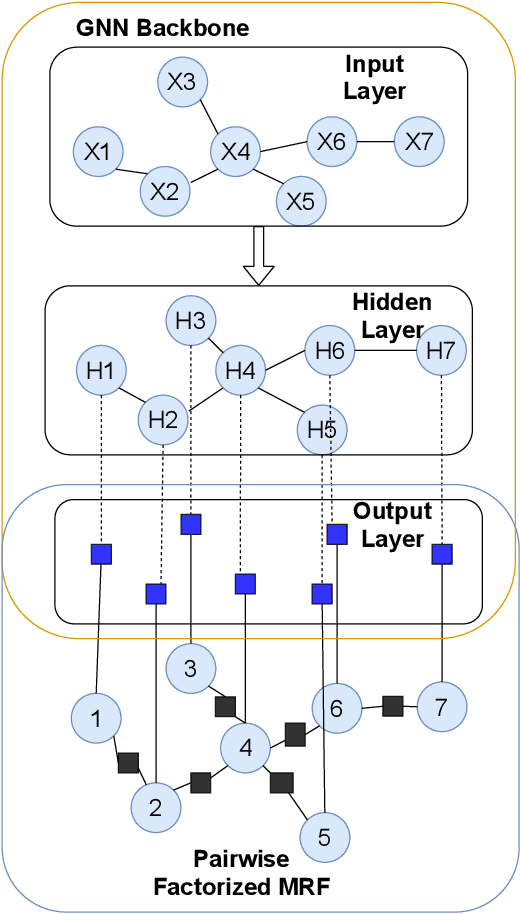
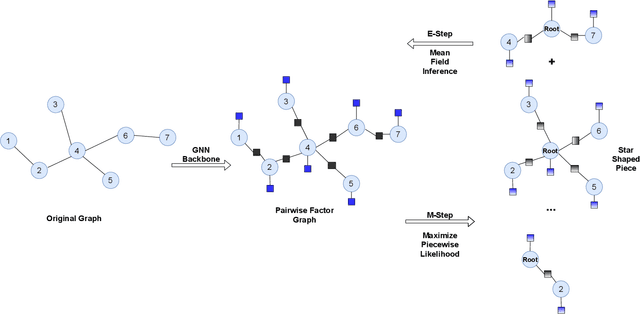
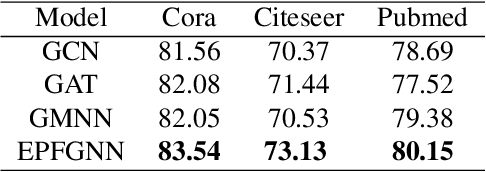
Node features and structural information of a graph are both crucial for semi-supervised node classification problems. A variety of graph neural network (GNN) based approaches have been proposed to tackle these problems, which typically determine output labels through feature aggregation. This can be problematic, as it implies conditional independence of output nodes given hidden representations, despite their direct connections in the graph. To learn the direct influence among output nodes in a graph, we propose the Explicit Pairwise Factorized Graph Neural Network (EPFGNN), which models the whole graph as a partially observed Markov Random Field. It contains explicit pairwise factors to model output-output relations and uses a GNN backbone to model input-output relations. To balance model complexity and expressivity, the pairwise factors have a shared component and a separate scaling coefficient for each edge. We apply the EM algorithm to train our model, and utilize a star-shaped piecewise likelihood for the tractable surrogate objective. We conduct experiments on various datasets, which shows that our model can effectively improve the performance for semi-supervised node classification on graphs.
Lifting the Convex Conjugate in Lagrangian Relaxations: A Tractable Approach for Continuous Markov Random Fields
Jul 13, 2021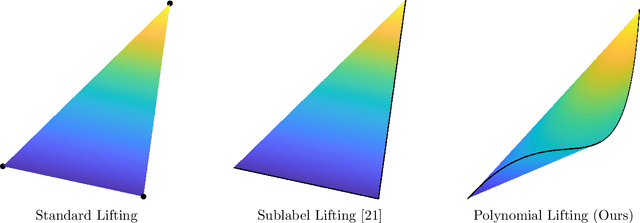
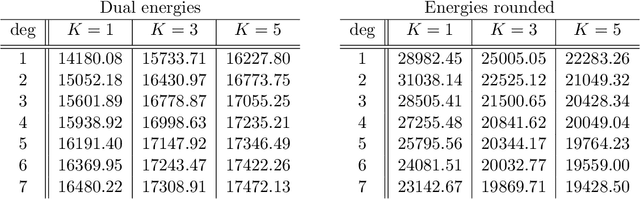
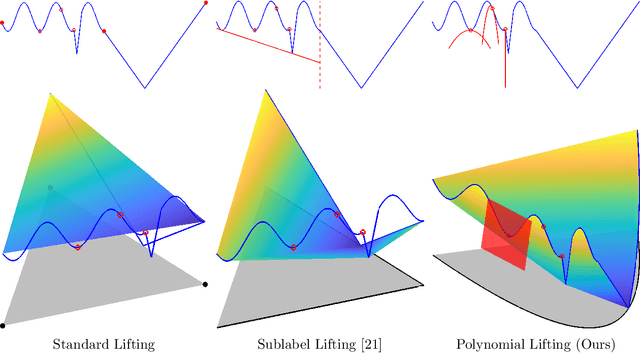
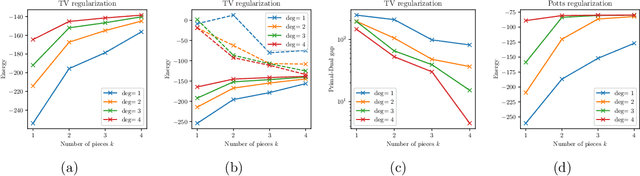
Dual decomposition approaches in nonconvex optimization may suffer from a duality gap. This poses a challenge when applying them directly to nonconvex problems such as MAP-inference in a Markov random field (MRF) with continuous state spaces. To eliminate such gaps, this paper considers a reformulation of the original nonconvex task in the space of measures. This infinite-dimensional reformulation is then approximated by a semi-infinite one, which is obtained via a piecewise polynomial discretization in the dual. We provide a geometric intuition behind the primal problem induced by the dual discretization and draw connections to optimization over moment spaces. In contrast to existing discretizations which suffer from a grid bias, we show that a piecewise polynomial discretization better preserves the continuous nature of our problem. Invoking results from optimal transport theory and convex algebraic geometry we reduce the semi-infinite program to a finite one and provide a practical implementation based on semidefinite programming. We show, experimentally and in theory, that the approach successfully reduces the duality gap. To showcase the scalability of our approach, we apply it to the stereo matching problem between two images.