 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Online Graph Exploration
Dec 06, 2020
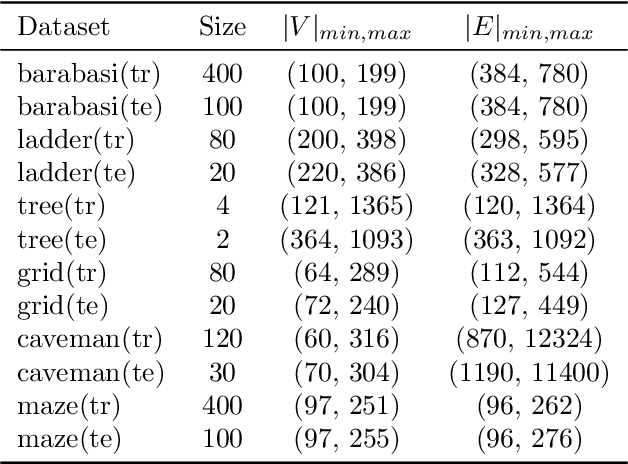

Can we learn how to explore unknown spaces efficiently? To answer this question, we study the problem of Online Graph Exploration, the online version of the Traveling Salesperson Problem. We reformulate graph exploration as a reinforcement learning problem and apply Direct Future Prediction (Dosovitskiy and Koltun, 2016) to solve it. As the graph is discovered online, the corresponding Markov Decision Process entails a dynamic state space, namely the observable graph and a dynamic action space, namely the nodes forming the graph's frontier. To the best of our knowledge, this is the first attempt to solve online graph exploration in a data-driven way. We conduct experiments on six data sets of procedurally generated graphs and three real city road networks. We demonstrate that our agent can learn strategies superior to many well known graph traversal algorithms, confirming that exploration can be learned.
Effective Version Space Reduction for Convolutional Neural Networks
Jun 22, 2020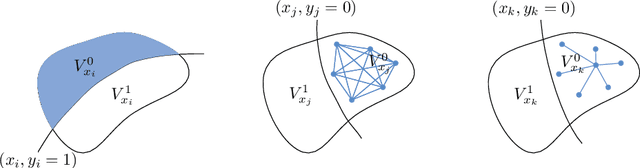

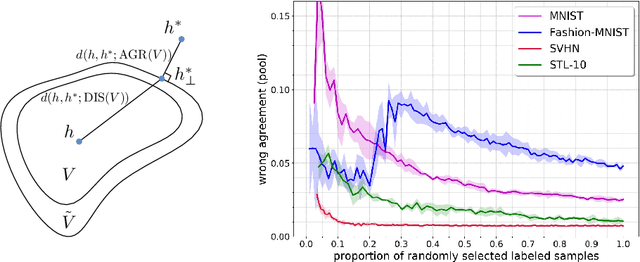
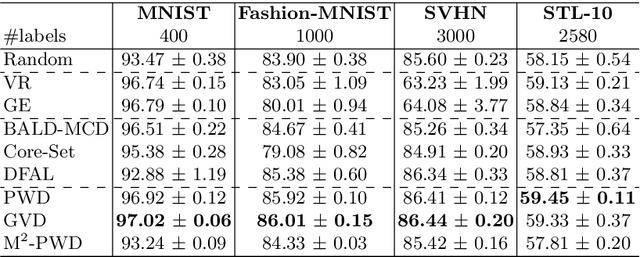
In active learning, sampling bias could pose a serious inconsistency problem and hinder the algorithm from finding the optimal hypothesis. However, many methods for neural networks are hypothesis space agnostic and do not address this problem. We examine active learning with convolutional neural networks through the principled lens of version space reduction. We identify the connection between two approaches---prior mass reduction and diameter reduction---and propose a new diameter-based querying method---the minimum Gibbs-vote disagreement. By estimating version space diameter and bias, we illustrate how version space of neural networks evolves and examine the realizability assumption. With experiments on MNIST, Fashion-MNIST, SVHN and STL-10 datasets, we demonstrate that diameter reduction methods reduce the version space more effectively and perform better than prior mass reduction and other baselines, and that the Gibbs vote disagreement is on par with the best query method.
Learning to Drive using Inverse Reinforcement Learning and Deep Q-Networks
Sep 21, 2017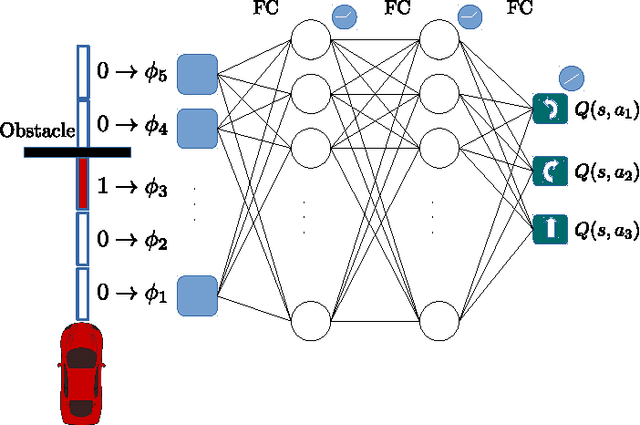
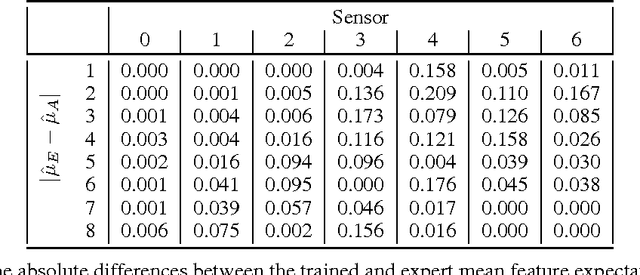
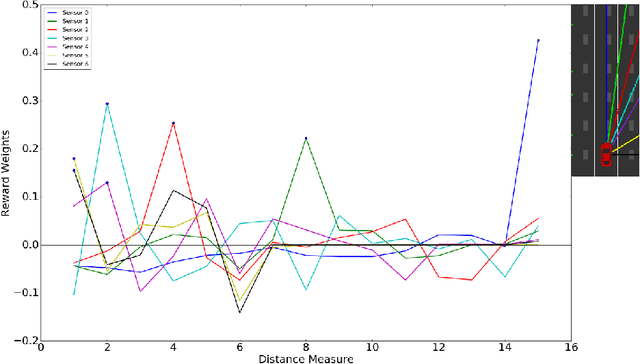
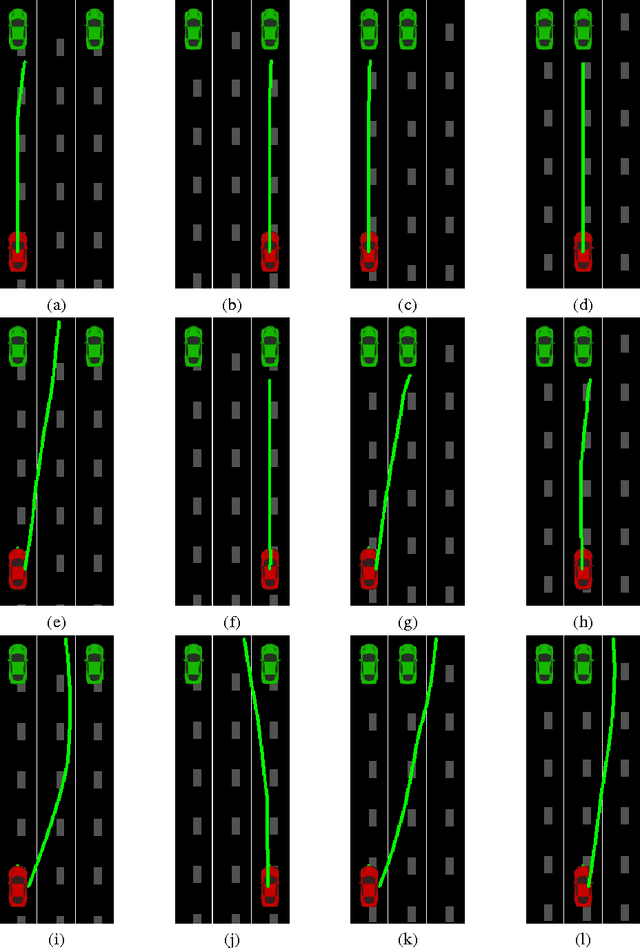
We propose an inverse reinforcement learning (IRL) approach using Deep Q-Networks to extract the rewards in problems with large state spaces. We evaluate the performance of this approach in a simulation-based autonomous driving scenario. Our results resemble the intuitive relation between the reward function and readings of distance sensors mounted at different poses on the car. We also show that, after a few learning rounds, our simulated agent generates collision-free motions and performs human-like lane change behaviour.