 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDance Style Transfer with Cross-modal Transformer
Aug 22, 2022
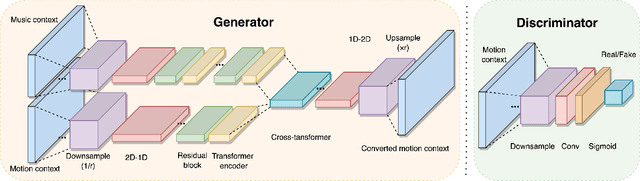
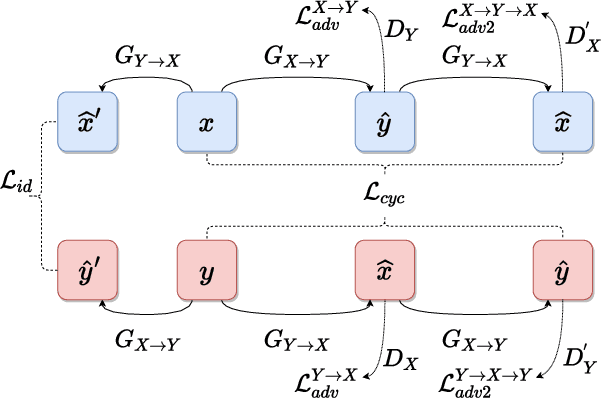

We present CycleDance, a dance style transfer system to transform an existing motion clip in one dance style to a motion clip in another dance style while attempting to preserve motion context of the dance. Our method extends an existing CycleGAN architecture for modeling audio sequences and integrates multimodal transformer encoders to account for music context. We adopt sequence length-based curriculum learning to stabilize training. Our approach captures rich and long-term intra-relations between motion frames, which is a common challenge in motion transfer and synthesis work. We further introduce new metrics for gauging transfer strength and content preservation in the context of dance movements. We perform an extensive ablation study as well as a human study including 30 participants with 5 or more years of dance experience. The results demonstrate that CycleDance generates realistic movements with the target style, significantly outperforming the baseline CycleGAN on naturalness, transfer strength, and content preservation.
Digraphwave: Scalable Extraction of Structural Node Embeddings via Diffusion on Directed Graphs
Jul 20, 2022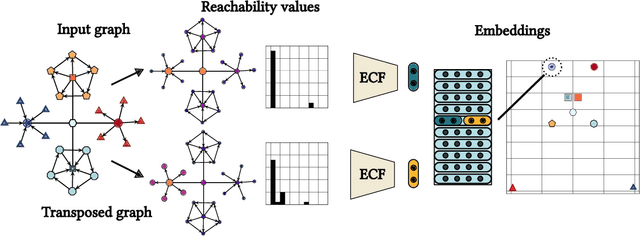

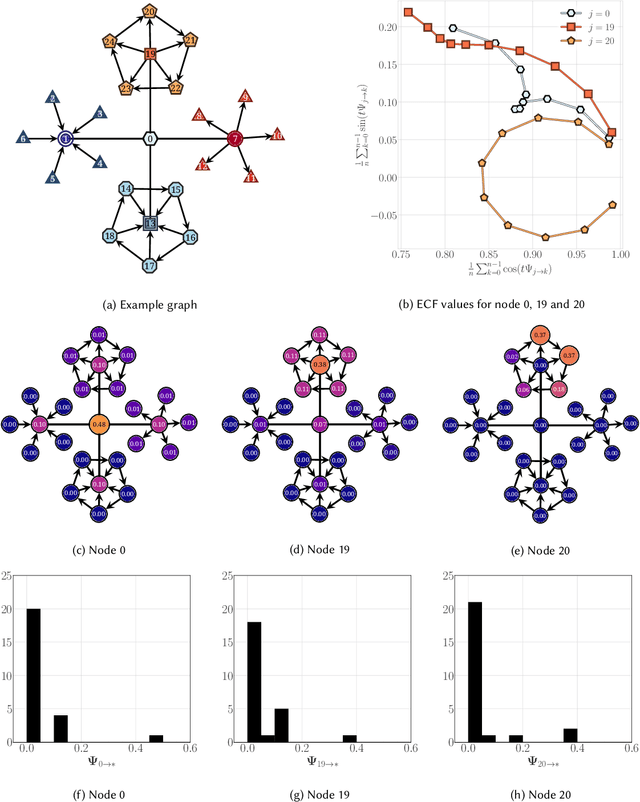
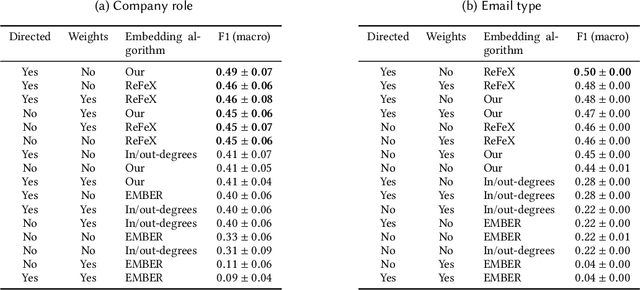
Structural node embeddings, vectors capturing local connectivity information for each node in a graph, have many applications in data mining and machine learning, e.g., network alignment and node classification, clustering and anomaly detection. For the analysis of directed graphs, e.g., transactions graphs, communication networks and social networks, the capability to capture directional information in the structural node embeddings is highly desirable, as is scalability of the embedding extraction method. Most existing methods are nevertheless only designed for undirected graph. Therefore, we present Digraphwave -- a scalable algorithm for extracting structural node embeddings on directed graphs. The Digraphwave embeddings consist of compressed diffusion pattern signatures, which are twice enhanced to increase their discriminate capacity. By proving a lower bound on the heat contained in the local vicinity of a diffusion initialization node, theoretically justified diffusion timescale values are established, and Digraphwave is left with only two easy-to-interpret hyperparameters: the embedding dimension and a neighbourhood resolution specifier. In our experiments, the two embedding enhancements, named transposition and aggregation, are shown to lead to a significant increase in macro F1 score for classifying automorphic identities, with Digraphwave outperforming all other structural embedding baselines. Moreover, Digraphwave either outperforms or matches the performance of all baselines on real graph datasets, displaying a particularly large performance gain in a network alignment task, while also being scalable to graphs with millions of nodes and edges, running up to 30x faster than a previous diffusion pattern based method and with a fraction of the memory consumption.
Back to the Manifold: Recovering from Out-of-Distribution States
Jul 18, 2022
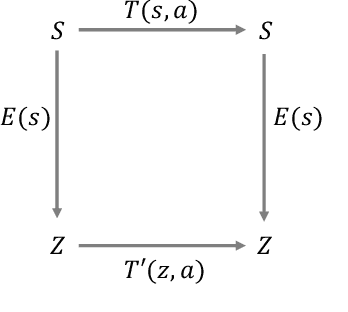
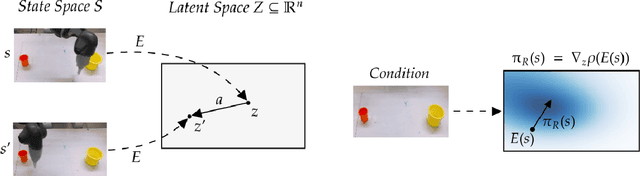

Learning from previously collected datasets of expert data offers the promise of acquiring robotic policies without unsafe and costly online explorations. However, a major challenge is a distributional shift between the states in the training dataset and the ones visited by the learned policy at the test time. While prior works mainly studied the distribution shift caused by the policy during the offline training, the problem of recovering from out-of-distribution states at the deployment time is not very well studied yet. We alleviate the distributional shift at the deployment time by introducing a recovery policy that brings the agent back to the training manifold whenever it steps out of the in-distribution states, e.g., due to an external perturbation. The recovery policy relies on an approximation of the training data density and a learned equivariant mapping that maps visual observations into a latent space in which translations correspond to the robot actions. We demonstrate the effectiveness of the proposed method through several manipulation experiments on a real robotic platform. Our results show that the recovery policy enables the agent to complete tasks while the behavioral cloning alone fails because of the distributional shift problem.
Equivariant Representation Learning via Class-Pose Decomposition
Jul 11, 2022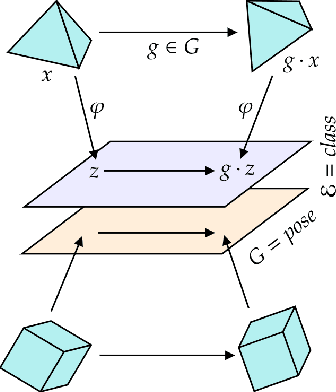
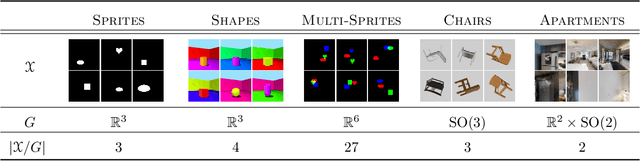
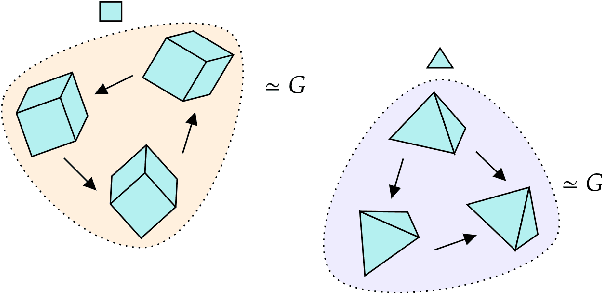
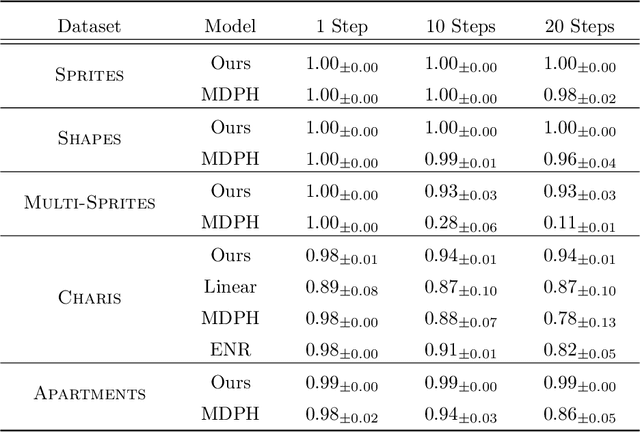
We introduce a general method for learning representations that are equivariant to symmetries of data. Our central idea is to decompose the latent space in an invariant factor and the symmetry group itself. The components semantically correspond to intrinsic data classes and poses respectively. The learner is self-supervised and infers these semantics based on relative symmetry information. The approach is motivated by theoretical results from group theory and guarantees representations that are lossless, interpretable and disentangled. We provide an empirical investigation via experiments involving datasets with a variety of symmetries. Results show that our representations capture the geometry of data and outperform other equivariant representation learning frameworks.
On the Subspace Structure of Gradient-Based Meta-Learning
Jul 08, 2022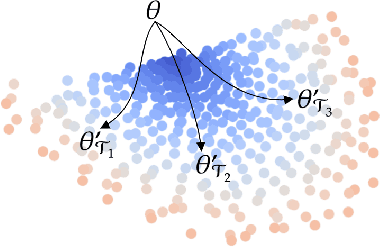

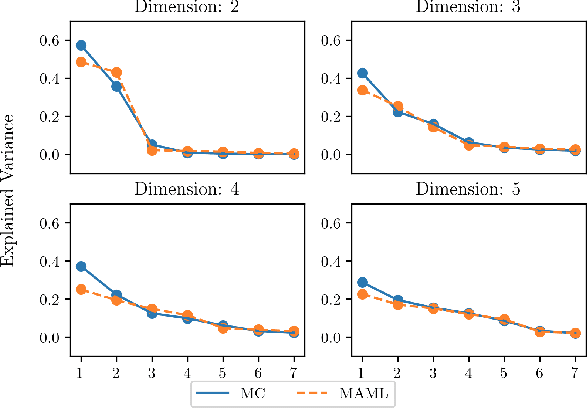
In this work we provide an analysis of the distribution of the post-adaptation parameters of Gradient-Based Meta-Learning (GBML) methods. Previous work has noticed how, for the case of image-classification, this adaption only takes place on the last layers of the network. We propose the more general notion that parameters are updated over a low-dimensional \emph{subspace} of the same dimensionality as the task-space and show that this holds for regression as well. Furthermore, the induced subspace structure provides a method to estimate the intrinsic dimension of the space of tasks of common few-shot learning datasets.
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


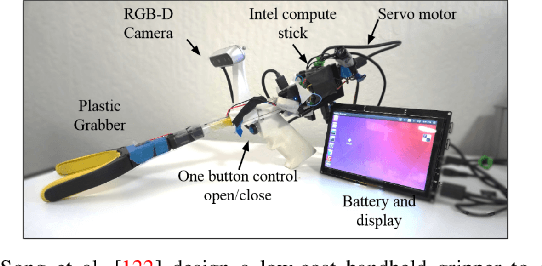
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Active Nearest Neighbor Regression Through Delaunay Refinement
Jun 16, 2022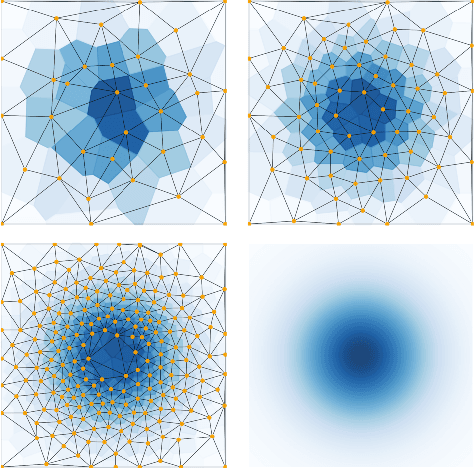
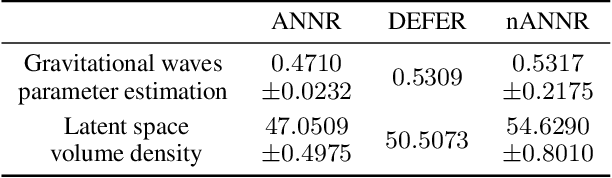
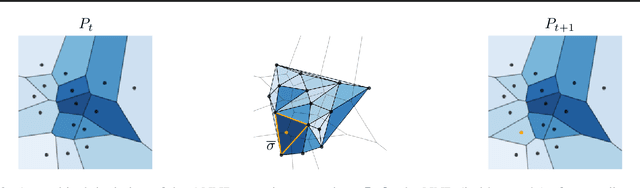

We introduce an algorithm for active function approximation based on nearest neighbor regression. Our Active Nearest Neighbor Regressor (ANNR) relies on the Voronoi-Delaunay framework from computational geometry to subdivide the space into cells with constant estimated function value and select novel query points in a way that takes the geometry of the function graph into account. We consider the recent state-of-the-art active function approximator called DEFER, which is based on incremental rectangular partitioning of the space, as the main baseline. The ANNR addresses a number of limitations that arise from the space subdivision strategy used in DEFER. We provide a computationally efficient implementation of our method, as well as theoretical halting guarantees. Empirical results show that ANNR outperforms the baseline for both closed-form functions and real-world examples, such as gravitational wave parameter inference and exploration of the latent space of a generative model.
Training and Evaluation of Deep Policies using Reinforcement Learning and Generative Models
Apr 18, 2022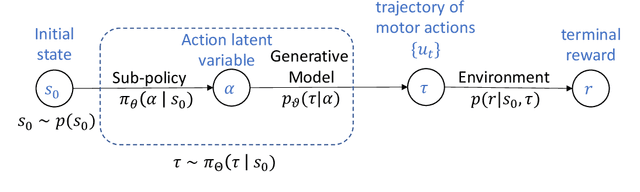
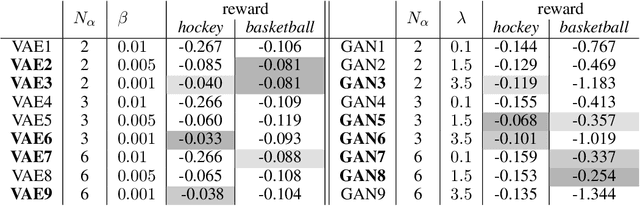
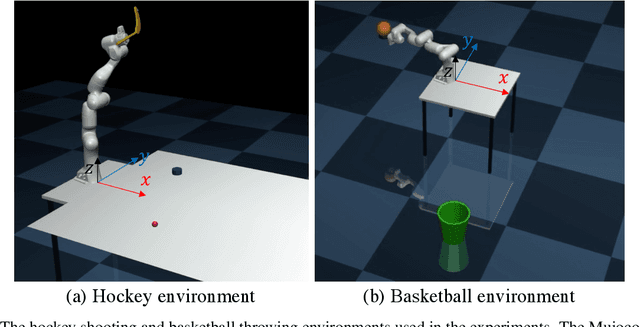
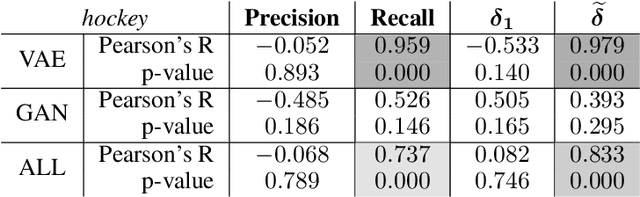
We present a data-efficient framework for solving sequential decision-making problems which exploits the combination of reinforcement learning (RL) and latent variable generative models. The framework, called GenRL, trains deep policies by introducing an action latent variable such that the feed-forward policy search can be divided into two parts: (i) training a sub-policy that outputs a distribution over the action latent variable given a state of the system, and (ii) unsupervised training of a generative model that outputs a sequence of motor actions conditioned on the latent action variable. GenRL enables safe exploration and alleviates the data-inefficiency problem as it exploits prior knowledge about valid sequences of motor actions. Moreover, we provide a set of measures for evaluation of generative models such that we are able to predict the performance of the RL policy training prior to the actual training on a physical robot. We experimentally determine the characteristics of generative models that have most influence on the performance of the final policy training on two robotics tasks: shooting a hockey puck and throwing a basketball. Furthermore, we empirically demonstrate that GenRL is the only method which can safely and efficiently solve the robotics tasks compared to two state-of-the-art RL methods.
Augment-Connect-Explore: a Paradigm for Visual Action Planning with Data Scarcity
Mar 24, 2022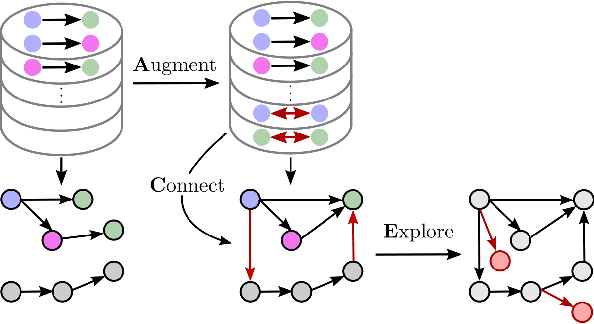
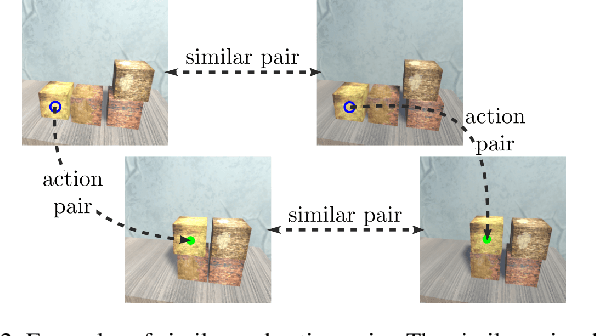
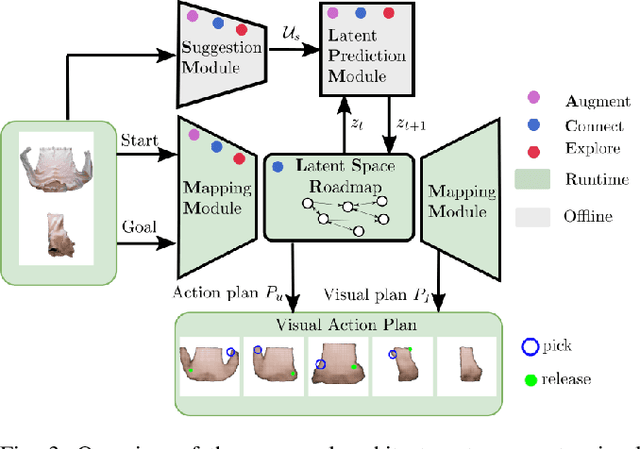
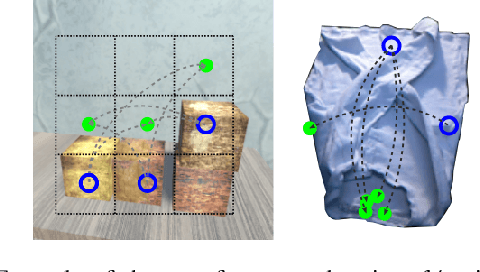
Visual action planning particularly excels in applications where the state of the system cannot be computed explicitly, such as manipulation of deformable objects, as it enables planning directly from raw images. Even though the field has been significantly accelerated by deep learning techniques, a crucial requirement for their success is the availability of a large amount of data. In this work, we propose the Augment-Connect-Explore (ACE) paradigm to enable visual action planning in cases of data scarcity. We build upon the Latent Space Roadmap (LSR) framework which performs planning with a graph built in a low dimensional latent space. In particular, ACE is used to i) Augment the available training dataset by autonomously creating new pairs of datapoints, ii) create new unobserved Connections among representations of states in the latent graph, and iii) Explore new regions of the latent space in a targeted manner. We validate the proposed approach on both simulated box stacking and real-world folding task showing the applicability for rigid and deformable object manipulation tasks, respectively.
Delaunay Component Analysis for Evaluation of Data Representations
Feb 14, 2022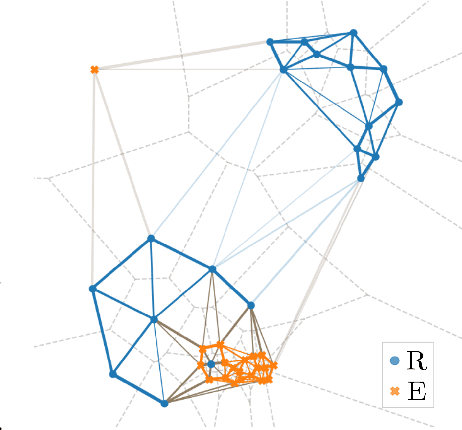

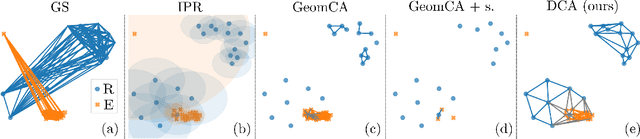

Advanced representation learning techniques require reliable and general evaluation methods. Recently, several algorithms based on the common idea of geometric and topological analysis of a manifold approximated from the learned data representations have been proposed. In this work, we introduce Delaunay Component Analysis (DCA) - an evaluation algorithm which approximates the data manifold using a more suitable neighbourhood graph called Delaunay graph. This provides a reliable manifold estimation even for challenging geometric arrangements of representations such as clusters with varying shape and density as well as outliers, which is where existing methods often fail. Furthermore, we exploit the nature of Delaunay graphs and introduce a framework for assessing the quality of individual novel data representations. We experimentally validate the proposed DCA method on representations obtained from neural networks trained with contrastive objective, supervised and generative models, and demonstrate various use cases of our extended single point evaluation framework.