 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientGS: Streamlining Gaussian Splatting for Large-Scale High-Resolution Scene Representation
Apr 19, 2024



In the domain of 3D scene representation, 3D Gaussian Splatting (3DGS) has emerged as a pivotal technology. However, its application to large-scale, high-resolution scenes (exceeding 4k$\times$4k pixels) is hindered by the excessive computational requirements for managing a large number of Gaussians. Addressing this, we introduce 'EfficientGS', an advanced approach that optimizes 3DGS for high-resolution, large-scale scenes. We analyze the densification process in 3DGS and identify areas of Gaussian over-proliferation. We propose a selective strategy, limiting Gaussian increase to key primitives, thereby enhancing the representational efficiency. Additionally, we develop a pruning mechanism to remove redundant Gaussians, those that are merely auxiliary to adjacent ones. For further enhancement, we integrate a sparse order increment for Spherical Harmonics (SH), designed to alleviate storage constraints and reduce training overhead. Our empirical evaluations, conducted on a range of datasets including extensive 4K+ aerial images, demonstrate that 'EfficientGS' not only expedites training and rendering times but also achieves this with a model size approximately tenfold smaller than conventional 3DGS while maintaining high rendering fidelity.
Face It Yourselves: An LLM-Based Two-Stage Strategy to Localize Configuration Errors via Logs
Apr 02, 2024Configurable software systems are prone to configuration errors, resulting in significant losses to companies. However, diagnosing these errors is challenging due to the vast and complex configuration space. These errors pose significant challenges for both experienced maintainers and new end-users, particularly those without access to the source code of the software systems. Given that logs are easily accessible to most end-users, we conduct a preliminary study to outline the challenges and opportunities of utilizing logs in localizing configuration errors. Based on the insights gained from the preliminary study, we propose an LLM-based two-stage strategy for end-users to localize the root-cause configuration properties based on logs. We further implement a tool, LogConfigLocalizer, aligned with the design of the aforementioned strategy, hoping to assist end-users in coping with configuration errors through log analysis. To the best of our knowledge, this is the first work to localize the root-cause configuration properties for end-users based on Large Language Models~(LLMs) and logs. We evaluate the proposed strategy on Hadoop by LogConfigLocalizer and prove its efficiency with an average accuracy as high as 99.91%. Additionally, we also demonstrate the effectiveness and necessity of different phases of the methodology by comparing it with two other variants and a baseline tool. Moreover, we validate the proposed methodology through a practical case study to demonstrate its effectiveness and feasibility.
A Variational Autoencoder Framework for Robust, Physics-Informed Cyberattack Recognition in Industrial Cyber-Physical Systems
Oct 10, 2023Cybersecurity of Industrial Cyber-Physical Systems is drawing significant concerns as data communication increasingly leverages wireless networks. A lot of data-driven methods were develope for detecting cyberattacks, but few are focused on distinguishing them from equipment faults. In this paper, we develop a data-driven framework that can be used to detect, diagnose, and localize a type of cyberattack called covert attacks on networked industrial control systems. The framework has a hybrid design that combines a variational autoencoder (VAE), a recurrent neural network (RNN), and a Deep Neural Network (DNN). This data-driven framework considers the temporal behavior of a generic physical system that extracts features from the time series of the sensor measurements that can be used for detecting covert attacks, distinguishing them from equipment faults, as well as localize the attack/fault. We evaluate the performance of the proposed method through a realistic simulation study on a networked power transmission system as a typical example of ICS. We compare the performance of the proposed method with the traditional model-based method to show its applicability and efficacy.
Adversarial Client Detection via Non-parametric Subspace Monitoring in the Internet of Federated Things
Oct 02, 2023



The Internet of Federated Things (IoFT) represents a network of interconnected systems with federated learning as the backbone, facilitating collaborative knowledge acquisition while ensuring data privacy for individual systems. The wide adoption of IoFT, however, is hindered by security concerns, particularly the susceptibility of federated learning networks to adversarial attacks. In this paper, we propose an effective non-parametric approach FedRR, which leverages the low-rank features of the transmitted parameter updates generated by federated learning to address the adversarial attack problem. Besides, our proposed method is capable of accurately detecting adversarial clients and controlling the false alarm rate under the scenario with no attack occurring. Experiments based on digit recognition using the MNIST datasets validated the advantages of our approach.
An Empirical Study of NetOps Capability of Pre-Trained Large Language Models
Sep 19, 2023



Nowadays, the versatile capabilities of Pre-trained Large Language Models (LLMs) have attracted much attention from the industry. However, some vertical domains are more interested in the in-domain capabilities of LLMs. For the Networks domain, we present NetEval, an evaluation set for measuring the comprehensive capabilities of LLMs in Network Operations (NetOps). NetEval is designed for evaluating the commonsense knowledge and inference ability in NetOps in a multi-lingual context. NetEval consists of 5,732 questions about NetOps, covering five different sub-domains of NetOps. With NetEval, we systematically evaluate the NetOps capability of 26 publicly available LLMs. The results show that only GPT-4 can achieve a performance competitive to humans. However, some open models like LLaMA 2 demonstrate significant potential.
Corporate Credit Rating: A Survey
Sep 19, 2023



Corporate credit rating (CCR) plays a very important role in the process of contemporary economic and social development. How to use credit rating methods for enterprises has always been a problem worthy of discussion. Through reading and studying the relevant literature at home and abroad, this paper makes a systematic survey of CCR. This paper combs the context of the development of CCR methods from the three levels: statistical models, machine learning models and neural network models, summarizes the common databases of CCR, and deeply compares the advantages and disadvantages of the models. Finally, this paper summarizes the problems existing in the current research and prospects the future of CCR. Compared with the existing review of CCR, this paper expounds and analyzes the progress of neural network model in this field in recent years.
Eco-driving for Electric Connected Vehicles at Signalized Intersections: A Parameterized Reinforcement Learning approach
Jun 24, 2022
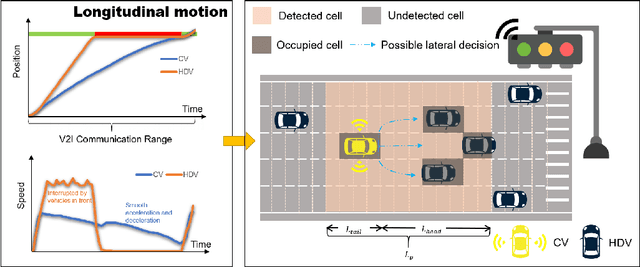
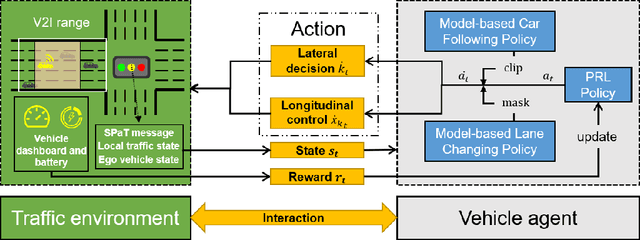
This paper proposes an eco-driving framework for electric connected vehicles (CVs) based on reinforcement learning (RL) to improve vehicle energy efficiency at signalized intersections. The vehicle agent is specified by integrating the model-based car-following policy, lane-changing policy, and the RL policy, to ensure safe operation of a CV. Subsequently, a Markov Decision Process (MDP) is formulated, which enables the vehicle to perform longitudinal control and lateral decisions, jointly optimizing the car-following and lane-changing behaviors of the CVs in the vicinity of intersections. Then, the hybrid action space is parameterized as a hierarchical structure and thereby trains the agents with two-dimensional motion patterns in a dynamic traffic environment. Finally, our proposed methods are evaluated in SUMO software from both a single-vehicle-based perspective and a flow-based perspective. The results show that our strategy can significantly reduce energy consumption by learning proper action schemes without any interruption of other human-driven vehicles (HDVs).
Decentral and Incentivized Federated Learning Frameworks: A Systematic Literature Review
May 18, 2022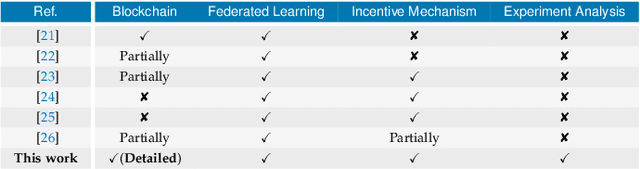
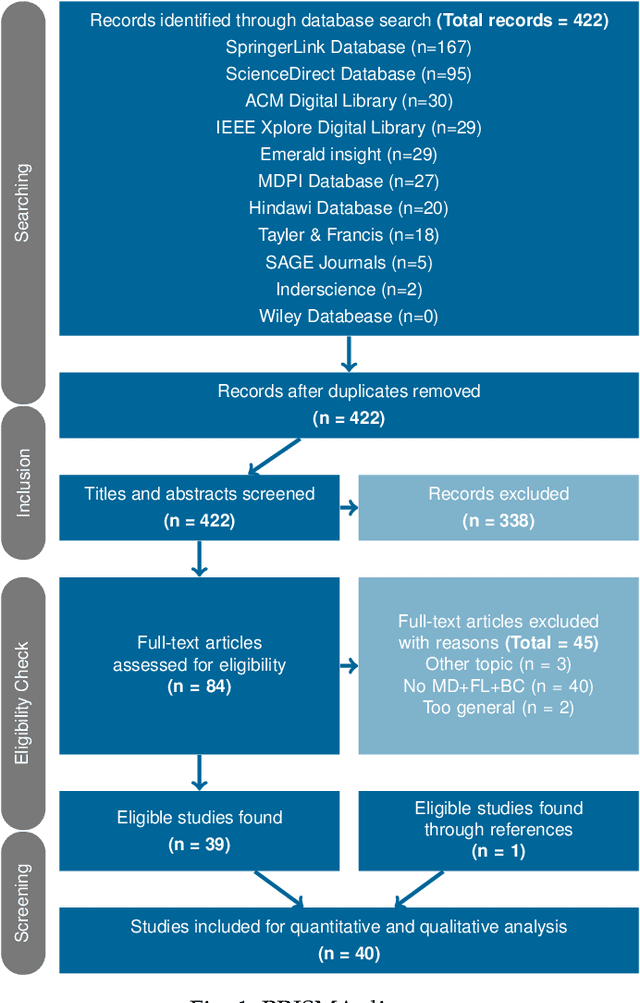
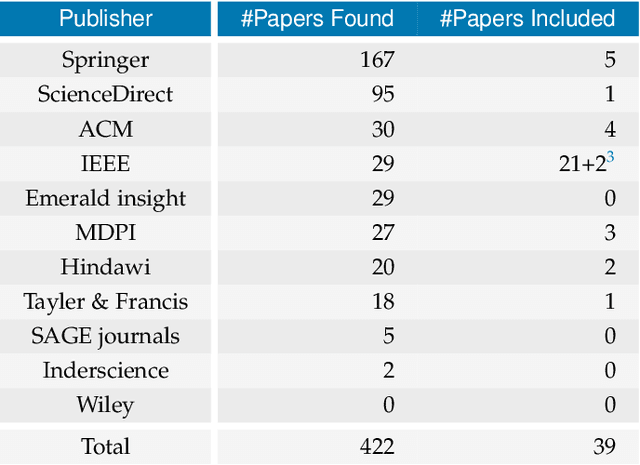
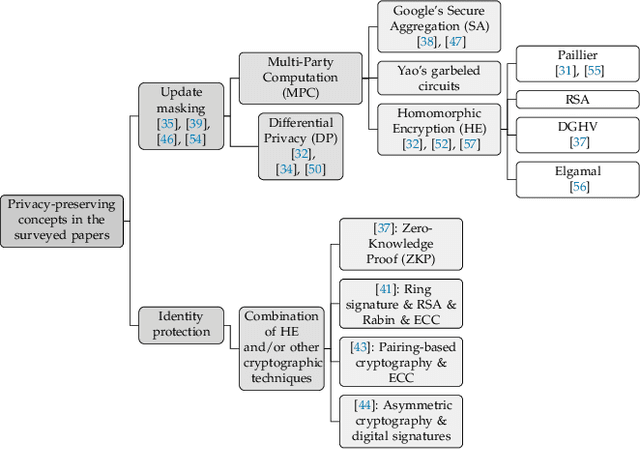
The advent of Federated Learning (FL) has ignited a new paradigm for parallel and confidential decentralized Machine Learning (ML) with the potential of utilizing the computational power of a vast number of IoT, mobile and edge devices without data leaving the respective device, ensuring privacy by design. Yet, in order to scale this new paradigm beyond small groups of already entrusted entities towards mass adoption, the Federated Learning Framework (FLF) has to become (i) truly decentralized and (ii) participants have to be incentivized. This is the first systematic literature review analyzing holistic FLFs in the domain of both, decentralized and incentivized federated learning. 422 publications were retrieved, by querying 12 major scientific databases. Finally, 40 articles remained after a systematic review and filtering process for in-depth examination. Although having massive potential to direct the future of a more distributed and secure AI, none of the analyzed FLF is production-ready. The approaches vary heavily in terms of use-cases, system design, solved issues and thoroughness. We are the first to provide a systematic approach to classify and quantify differences between FLF, exposing limitations of current works and derive future directions for research in this novel domain.
A Novel Splitting Criterion Inspired by Geometric Mean Metric Learning for Decision Tree
Apr 23, 2022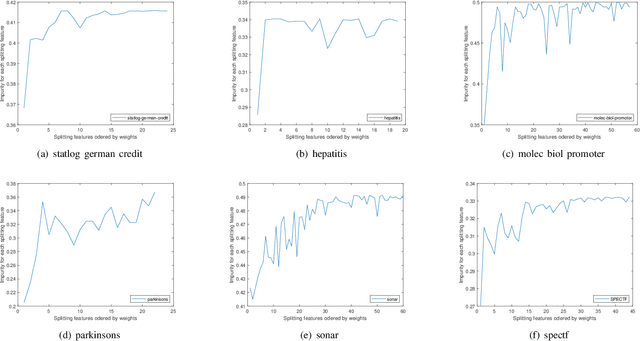
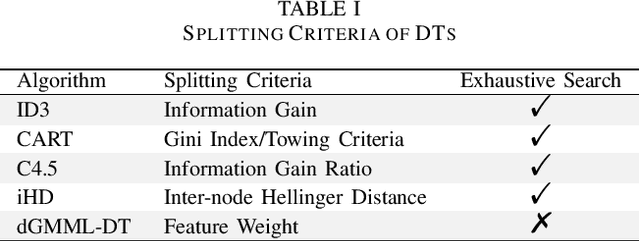
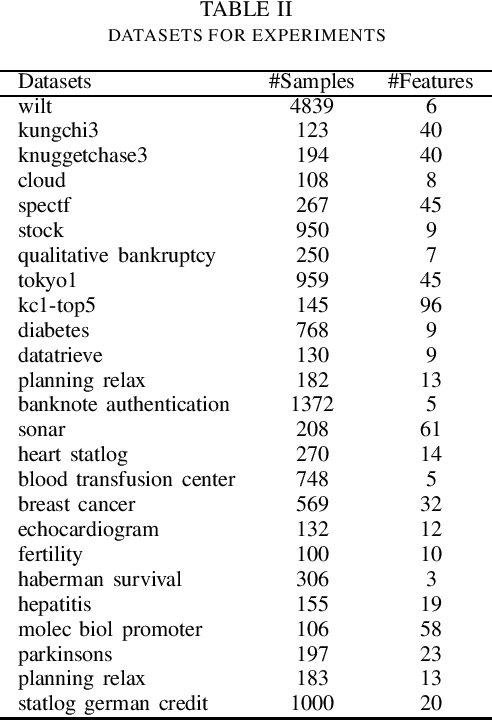
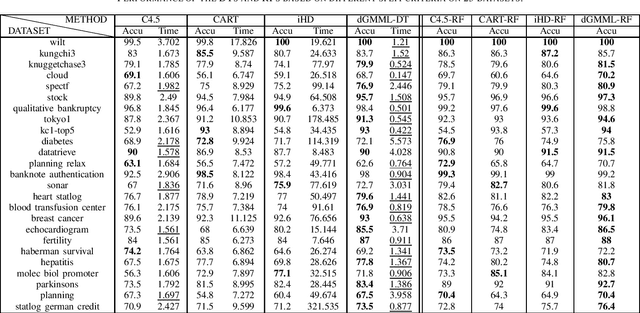
Decision tree (DT) attracts persistent research attention due to its impressive empirical performance and interpretability in numerous applications. However, the growth of traditional yet widely-used univariate decision trees (UDTs) is quite time-consuming as they need to traverse all the features to find the splitting value with the maximal reduction of the impurity at each internal node. In this paper, we newly design a splitting criterion to speed up the growth. The criterion is induced from Geometric Mean Metric Learning (GMML) and then optimized under its diagonalized metric matrix constraint, consequently, a closed-form rank of feature discriminant abilities can at once be obtained and the top 1 feature at each node used to grow an intent DT (called as dGMML-DT, where d is an abbreviation for diagonalization). We evaluated the performance of the proposed methods and their corresponding ensembles on benchmark datasets. The experiment shows that dGMML-DT achieves comparable or better classification results more efficiently than the UDTs with 10x average speedup. Furthermore, dGMML-DT can straightforwardly be extended to its multivariable counterpart (dGMML-MDT) without needing laborious operations.
Improve Deep Image Inpainting by Emphasizing the Complexity of Missing Regions
Feb 13, 2022Deep image inpainting research mainly focuses on constructing various neural network architectures or imposing novel optimization objectives. However, on the one hand, building a state-of-the-art deep inpainting model is an extremely complex task, and on the other hand, the resulting performance gains are sometimes very limited. We believe that besides the frameworks of inpainting models, lightweight traditional image processing techniques, which are often overlooked, can actually be helpful to these deep models. In this paper, we enhance the deep image inpainting models with the help of classical image complexity metrics. A knowledge-assisted index composed of missingness complexity and forward loss is presented to guide the batch selection in the training procedure. This index helps find samples that are more conducive to optimization in each iteration and ultimately boost the overall inpainting performance. The proposed approach is simple and can be plugged into many deep inpainting models by changing only a few lines of code. We experimentally demonstrate the improvements for several recently developed image inpainting models on various datasets.