 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize with Stochastic Dominance Constraints
Nov 21, 2022



In real-world decision-making, uncertainty is important yet difficult to handle. Stochastic dominance provides a theoretically sound approach for comparing uncertain quantities, but optimization with stochastic dominance constraints is often computationally expensive, which limits practical applicability. In this paper, we develop a simple yet efficient approach for the problem, the Light Stochastic Dominance Solver (light-SD), that leverages useful properties of the Lagrangian. We recast the inner optimization in the Lagrangian as a learning problem for surrogate approximation, which bypasses apparent intractability and leads to tractable updates or even closed-form solutions for gradient calculations. We prove convergence of the algorithm and test it empirically. The proposed light-SD demonstrates superior performance on several representative problems ranging from finance to supply chain management.
Dichotomy of Control: Separating What You Can Control from What You Cannot
Oct 24, 2022



Future- or return-conditioned supervised learning is an emerging paradigm for offline reinforcement learning (RL), where the future outcome (i.e., return) associated with an observed action sequence is used as input to a policy trained to imitate those same actions. While return-conditioning is at the heart of popular algorithms such as decision transformer (DT), these methods tend to perform poorly in highly stochastic environments, where an occasional high return can arise from randomness in the environment rather than the actions themselves. Such situations can lead to a learned policy that is inconsistent with its conditioning inputs; i.e., using the policy to act in the environment, when conditioning on a specific desired return, leads to a distribution of real returns that is wildly different than desired. In this work, we propose the dichotomy of control (DoC), a future-conditioned supervised learning framework that separates mechanisms within a policy's control (actions) from those beyond a policy's control (environment stochasticity). We achieve this separation by conditioning the policy on a latent variable representation of the future, and designing a mutual information constraint that removes any information from the latent variable associated with randomness in the environment. Theoretically, we show that DoC yields policies that are consistent with their conditioning inputs, ensuring that conditioning a learned policy on a desired high-return future outcome will correctly induce high-return behavior. Empirically, we show that DoC is able to achieve significantly better performance than DT on environments that have highly stochastic rewards and transition
Optimal Scaling for Locally Balanced Proposals in Discrete Spaces
Sep 16, 2022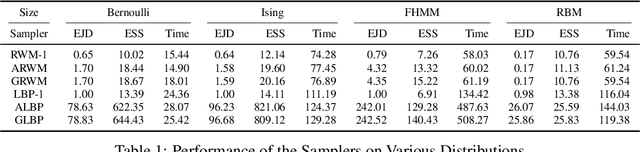
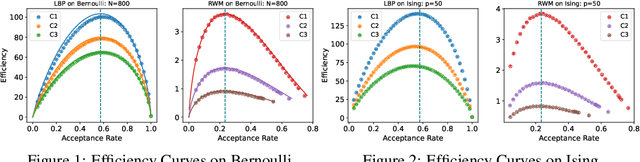
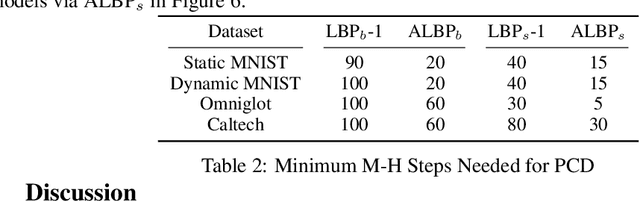
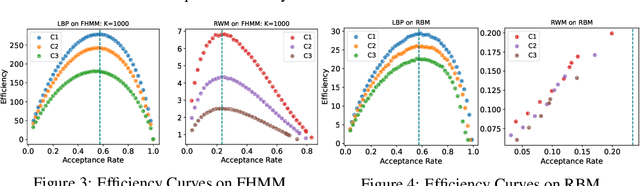
Optimal scaling has been well studied for Metropolis-Hastings (M-H) algorithms in continuous spaces, but a similar understanding has been lacking in discrete spaces. Recently, a family of locally balanced proposals (LBP) for discrete spaces has been proved to be asymptotically optimal, but the question of optimal scaling has remained open. In this paper, we establish, for the first time, that the efficiency of M-H in discrete spaces can also be characterized by an asymptotic acceptance rate that is independent of the target distribution. Moreover, we verify, both theoretically and empirically, that the optimal acceptance rates for LBP and random walk Metropolis (RWM) are $0.574$ and $0.234$ respectively. These results also help establish that LBP is asymptotically $O(N^\frac{2}{3})$ more efficient than RWM with respect to model dimension $N$. Knowledge of the optimal acceptance rate allows one to automatically tune the neighborhood size of a proposal distribution in a discrete space, directly analogous to step-size control in continuous spaces. We demonstrate empirically that such adaptive M-H sampling can robustly improve sampling in a variety of target distributions in discrete spaces, including training deep energy based models.
Spectral Decomposition Representation for Reinforcement Learning
Aug 19, 2022
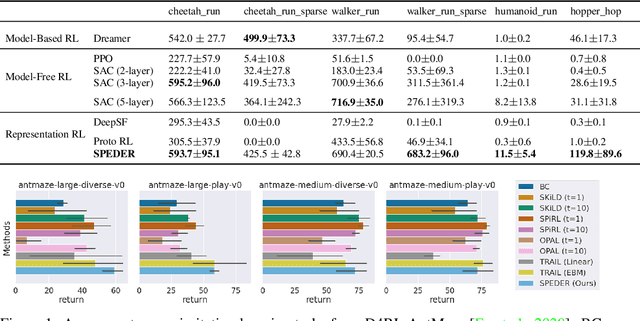
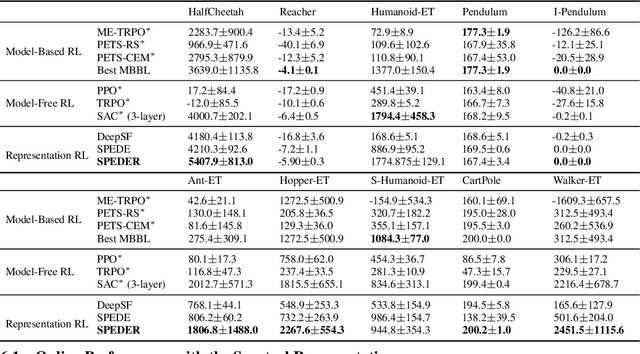

Representation learning often plays a critical role in reinforcement learning by managing the curse of dimensionality. A representative class of algorithms exploits a spectral decomposition of the stochastic transition dynamics to construct representations that enjoy strong theoretical properties in an idealized setting. However, current spectral methods suffer from limited applicability because they are constructed for state-only aggregation and derived from a policy-dependent transition kernel, without considering the issue of exploration. To address these issues, we propose an alternative spectral method, Spectral Decomposition Representation (SPEDER), that extracts a state-action abstraction from the dynamics without inducing spurious dependence on the data collection policy, while also balancing the exploration-versus-exploitation trade-off during learning. A theoretical analysis establishes the sample efficiency of the proposed algorithm in both the online and offline settings. In addition, an experimental investigation demonstrates superior performance over current state-of-the-art algorithms across several benchmarks.
Making Linear MDPs Practical via Contrastive Representation Learning
Jul 14, 2022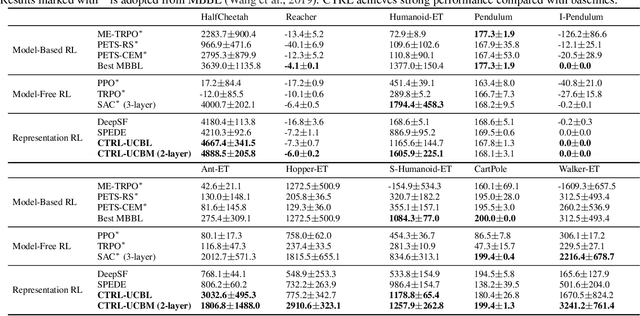
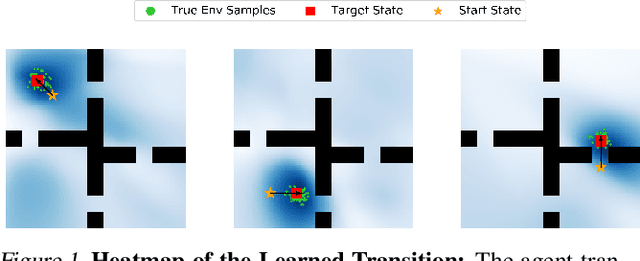


It is common to address the curse of dimensionality in Markov decision processes (MDPs) by exploiting low-rank representations. This motivates much of the recent theoretical study on linear MDPs. However, most approaches require a given representation under unrealistic assumptions about the normalization of the decomposition or introduce unresolved computational challenges in practice. Instead, we consider an alternative definition of linear MDPs that automatically ensures normalization while allowing efficient representation learning via contrastive estimation. The framework also admits confidence-adjusted index algorithms, enabling an efficient and principled approach to incorporating optimism or pessimism in the face of uncertainty. To the best of our knowledge, this provides the first practical representation learning method for linear MDPs that achieves both strong theoretical guarantees and empirical performance. Theoretically, we prove that the proposed algorithm is sample efficient in both the online and offline settings. Empirically, we demonstrate superior performance over existing state-of-the-art model-based and model-free algorithms on several benchmarks.
Rationale-Augmented Ensembles in Language Models
Jul 02, 2022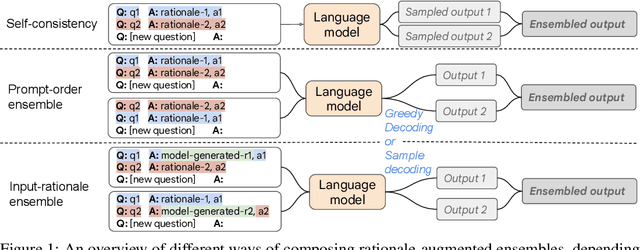

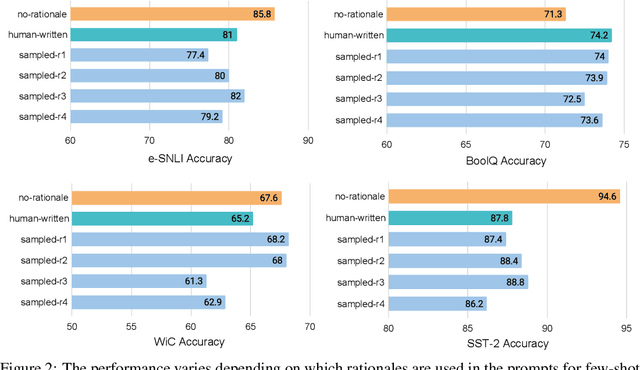

Recent research has shown that rationales, or step-by-step chains of thought, can be used to improve performance in multi-step reasoning tasks. We reconsider rationale-augmented prompting for few-shot in-context learning, where (input -> output) prompts are expanded to (input, rationale -> output) prompts. For rationale-augmented prompting we demonstrate how existing approaches, which rely on manual prompt engineering, are subject to sub-optimal rationales that may harm performance. To mitigate this brittleness, we propose a unified framework of rationale-augmented ensembles, where we identify rationale sampling in the output space as the key component to robustly improve performance. This framework is general and can easily be extended to common natural language processing tasks, even those that do not traditionally leverage intermediate steps, such as question answering, word sense disambiguation, and sentiment analysis. We demonstrate that rationale-augmented ensembles achieve more accurate and interpretable results than existing prompting approaches--including standard prompting without rationales and rationale-based chain-of-thought prompting--while simultaneously improving interpretability of model predictions through the associated rationales.
Discrete Langevin Sampler via Wasserstein Gradient Flow
Jun 29, 2022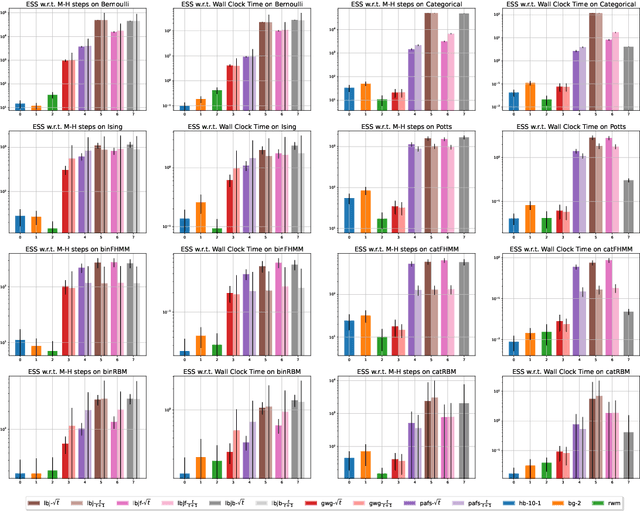


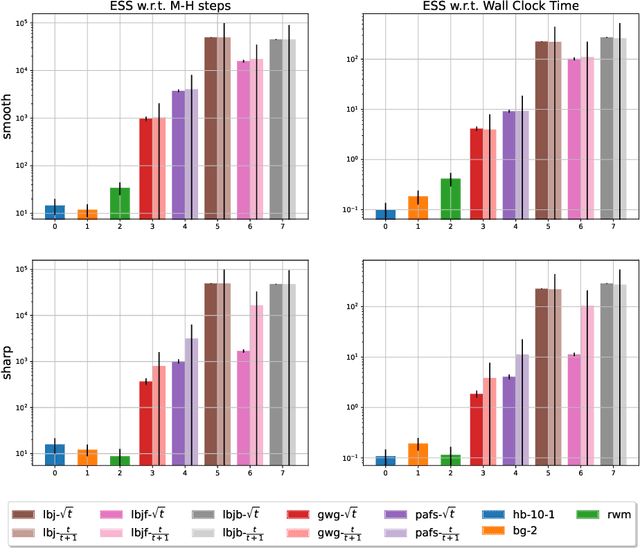
Recently, a family of locally balanced (LB) samplers has demonstrated excellent performance at sampling and learning energy-based models (EBMs) in discrete spaces. However, the theoretical understanding of this success is limited. In this work, we show how LB functions give rise to LB dynamics corresponding to Wasserstein gradient flow in a discrete space. From first principles, previous LB samplers can then be seen as discretizations of the LB dynamics with respect to Hamming distance. Based on this observation, we propose a new algorithm, the Locally Balanced Jump (LBJ), by discretizing the LB dynamics with respect to simulation time. As a result, LBJ has a location-dependent "velocity" that allows it to make proposals with larger distances. Additionally, LBJ decouples each dimension into independent sub-processes, enabling convenient parallel implementation. We demonstrate the advantages of LBJ for sampling and learning in various binary and categorical distributions.
A Parametric Class of Approximate Gradient Updates for Policy Optimization
Jun 17, 2022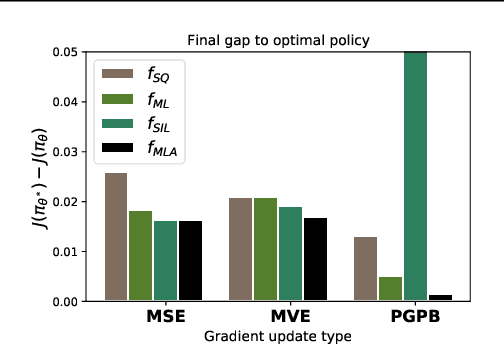

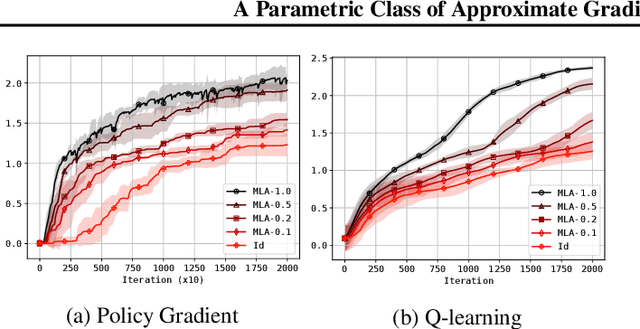
Approaches to policy optimization have been motivated from diverse principles, based on how the parametric model is interpreted (e.g. value versus policy representation) or how the learning objective is formulated, yet they share a common goal of maximizing expected return. To better capture the commonalities and identify key differences between policy optimization methods, we develop a unified perspective that re-expresses the underlying updates in terms of a limited choice of gradient form and scaling function. In particular, we identify a parameterized space of approximate gradient updates for policy optimization that is highly structured, yet covers both classical and recent examples, including PPO. As a result, we obtain novel yet well motivated updates that generalize existing algorithms in a way that can deliver benefits both in terms of convergence speed and final result quality. An experimental investigation demonstrates that the additional degrees of freedom provided in the parameterized family of updates can be leveraged to obtain non-trivial improvements both in synthetic domains and on popular deep RL benchmarks.
Multimodal Masked Autoencoders Learn Transferable Representations
May 31, 2022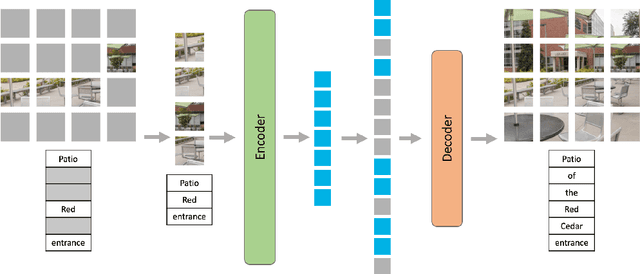
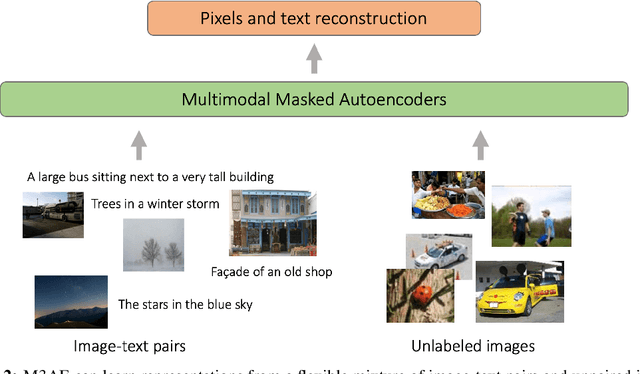
Building scalable models to learn from diverse, multimodal data remains an open challenge. For vision-language data, the dominant approaches are based on contrastive learning objectives that train a separate encoder for each modality. While effective, contrastive learning approaches introduce sampling bias depending on the data augmentations used, which can degrade performance on downstream tasks. Moreover, these methods are limited to paired image-text data, and cannot leverage widely-available unpaired data. In this paper, we investigate whether a large multimodal model trained purely via masked token prediction, without using modality-specific encoders or contrastive learning, can learn transferable representations for downstream tasks. We propose a simple and scalable network architecture, the Multimodal Masked Autoencoder (M3AE), which learns a unified encoder for both vision and language data via masked token prediction. We provide an empirical study of M3AE trained on a large-scale image-text dataset, and find that M3AE is able to learn generalizable representations that transfer well to downstream tasks. Surprisingly, we find that M3AE benefits from a higher text mask ratio (50-90%), in contrast to BERT whose standard masking ratio is 15%, due to the joint training of two data modalities. We also provide qualitative analysis showing that the learned representation incorporates meaningful information from both image and language. Lastly, we demonstrate the scalability of M3AE with larger model size and training time, and its flexibility to train on both paired image-text data as well as unpaired data.
Chain of Thought Imitation with Procedure Cloning
May 22, 2022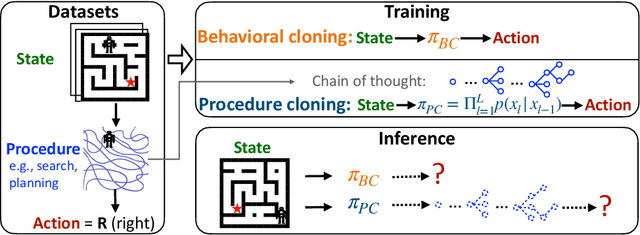

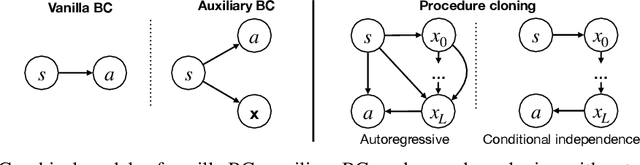
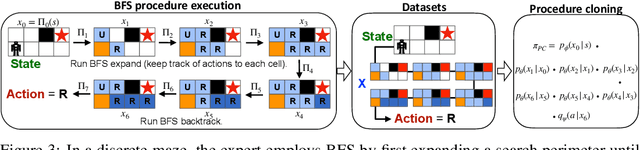
Imitation learning aims to extract high-performance policies from logged demonstrations of expert behavior. It is common to frame imitation learning as a supervised learning problem in which one fits a function approximator to the input-output mapping exhibited by the logged demonstrations (input observations to output actions). While the framing of imitation learning as a supervised input-output learning problem allows for applicability in a wide variety of settings, it is also an overly simplistic view of the problem in situations where the expert demonstrations provide much richer insight into expert behavior. For example, applications such as path navigation, robot manipulation, and strategy games acquire expert demonstrations via planning, search, or some other multi-step algorithm, revealing not just the output action to be imitated but also the procedure for how to determine this action. While these intermediate computations may use tools not available to the agent during inference (e.g., environment simulators), they are nevertheless informative as a way to explain an expert's mapping of state to actions. To properly leverage expert procedure information without relying on the privileged tools the expert may have used to perform the procedure, we propose procedure cloning, which applies supervised sequence prediction to imitate the series of expert computations. This way, procedure cloning learns not only what to do (i.e., the output action), but how and why to do it (i.e., the procedure). Through empirical analysis on navigation, simulated robotic manipulation, and game-playing environments, we show that imitating the intermediate computations of an expert's behavior enables procedure cloning to learn policies exhibiting significant generalization to unseen environment configurations, including those configurations for which running the expert's procedure directly is infeasible.