 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Robustness of Unsupervised Speech Recognition
Oct 12, 2021
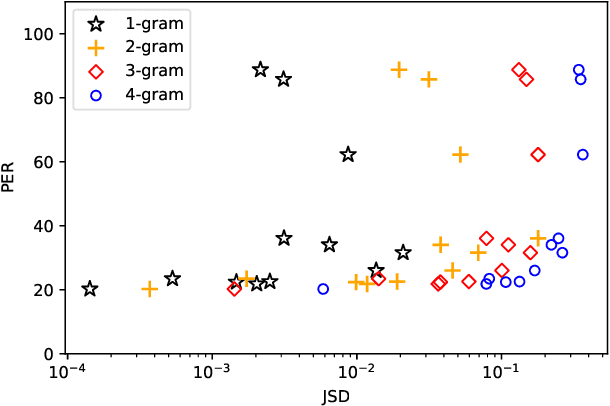
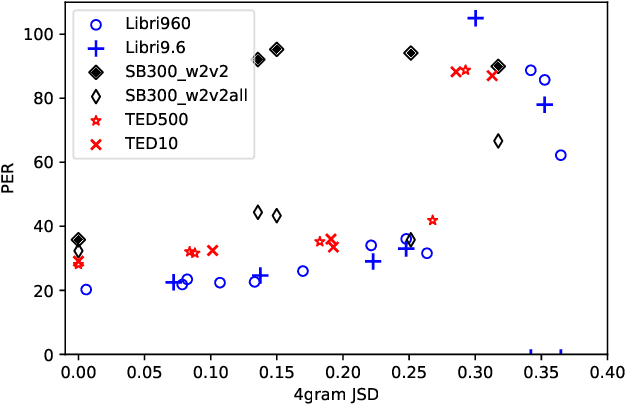
Unsupervised speech recognition (unsupervised ASR) aims to learn the ASR system with non-parallel speech and text corpus only. Wav2vec-U has shown promising results in unsupervised ASR by self-supervised speech representations coupled with Generative Adversarial Network (GAN) training, but the robustness of the unsupervised ASR framework is unknown. In this work, we further analyze the training robustness of unsupervised ASR on the domain mismatch scenarios in which the domains of unpaired speech and text are different. Three domain mismatch scenarios include: (1) using speech and text from different datasets, (2) utilizing noisy/spontaneous speech, and (3) adjusting the amount of speech and text data. We also quantify the degree of the domain mismatch by calculating the JS-divergence of phoneme n-gram between the transcription of speech and text. This metric correlates with the performance highly. Experimental results show that domain mismatch leads to inferior performance, but a self-supervised model pre-trained on the targeted speech domain can extract better representation to alleviate the performance drop.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021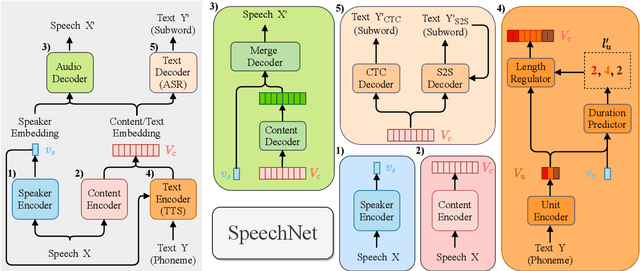
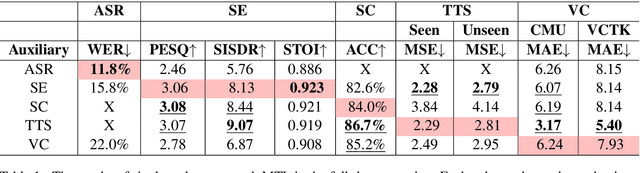
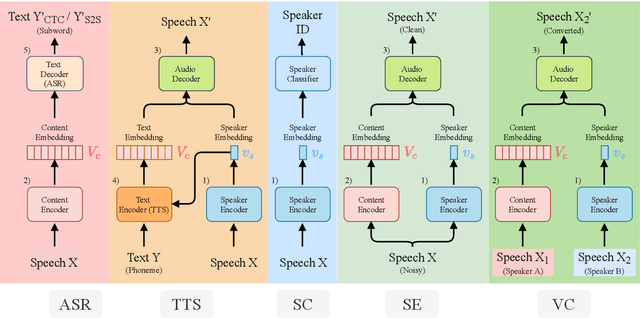
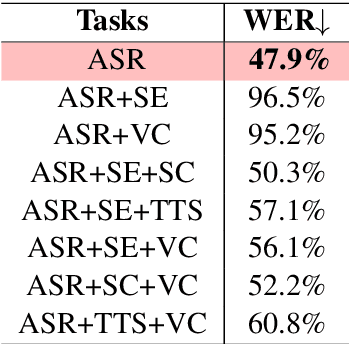
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021
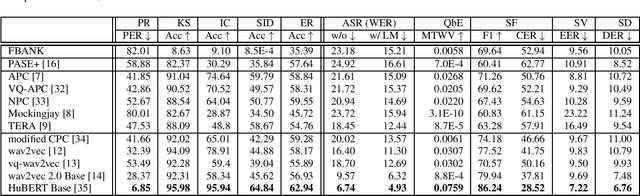
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
Self-supervised Pre-training Reduces Label Permutation Instability of Speech Separation
Oct 29, 2020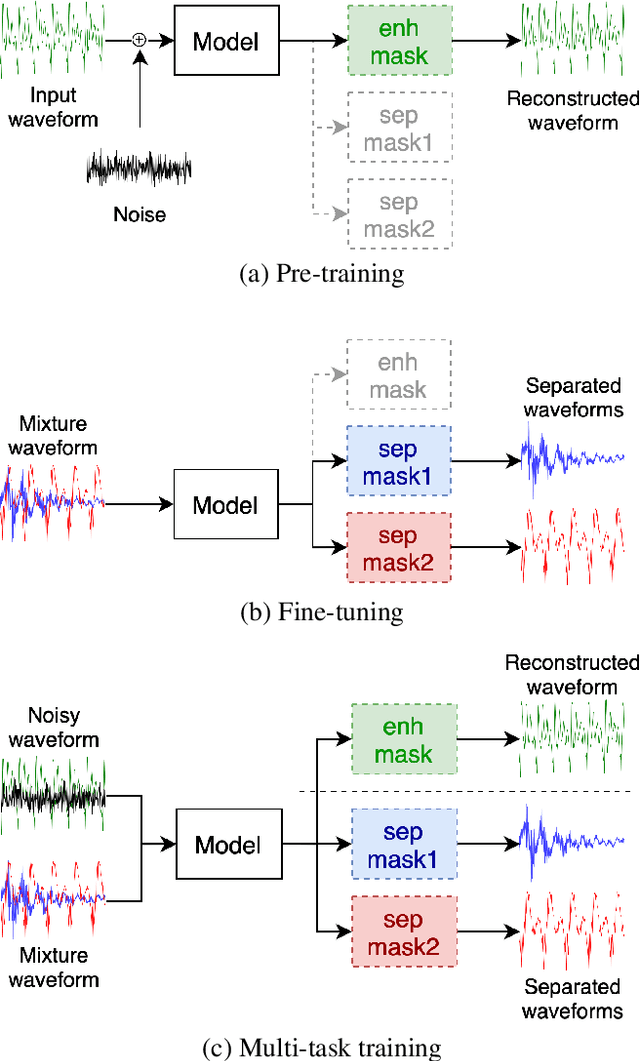
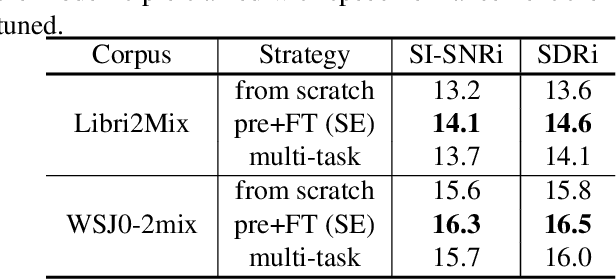
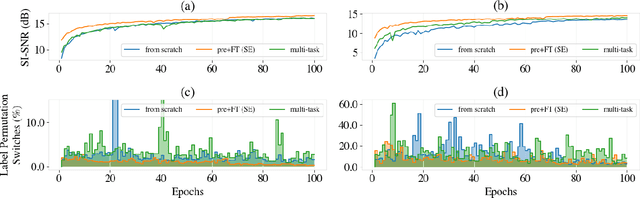
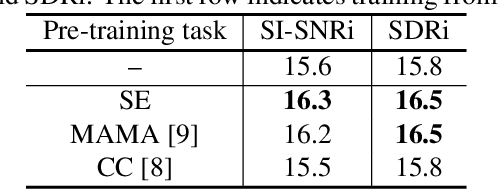
Speech separation has been well-developed while there are still problems waiting to be solved. The main problem we focus on in this paper is the frequent label permutation switching of permutation invariant training (PIT). For N-speaker separation, there would be N! possible label permutations. How to stably select correct label permutations is a long-standing problem. In this paper, we utilize self-supervised pre-training to stabilize the label permutations. Among several types of self-supervised tasks, speech enhancement based pre-training tasks show significant effectiveness in our experiments. When using off-the-shelf pre-trained models, training duration could be shortened to one-third to two-thirds. Furthermore, even taking pre-training time into account, the entire training process could still be shorter without a performance drop when using a larger batch size.
Contextualizing ASR Lattice Rescoring with Hybrid Pointer Network Language Model
May 15, 2020
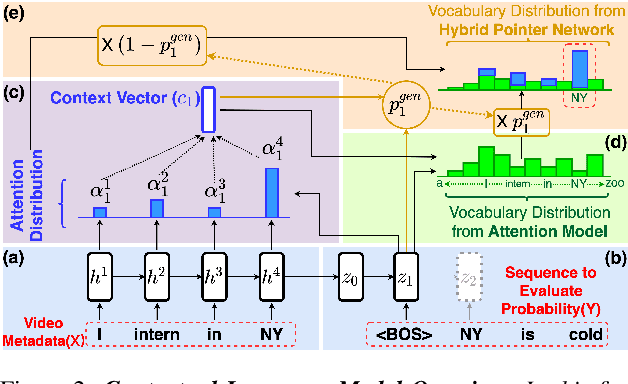
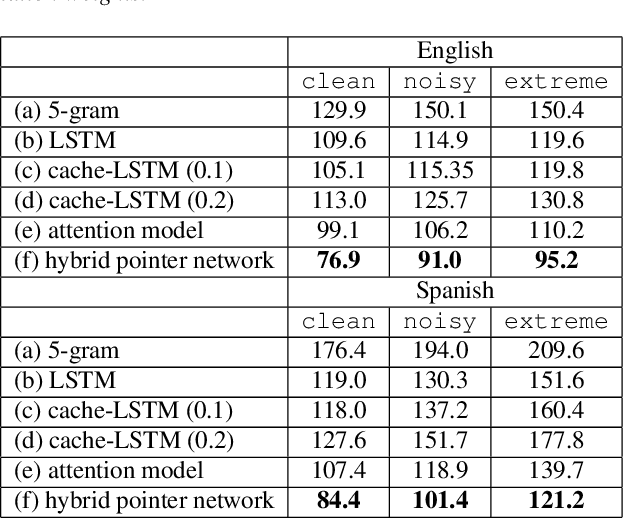
Videos uploaded on social media are often accompanied with textual descriptions. In building automatic speech recognition (ASR) systems for videos, we can exploit the contextual information provided by such video metadata. In this paper, we explore ASR lattice rescoring by selectively attending to the video descriptions. We first use an attention based method to extract contextual vector representations of video metadata, and use these representations as part of the inputs to a neural language model during lattice rescoring. Secondly, we propose a hybrid pointer network approach to explicitly interpolate the word probabilities of the word occurrences in metadata. We perform experimental evaluations on both language modeling and ASR tasks, and demonstrate that both proposed methods provide performance improvements by selectively leveraging the video metadata.
Completely Unsupervised Phoneme Recognition By A Generative Adversarial Network Harmonized With Iteratively Refined Hidden Markov Models
Apr 08, 2019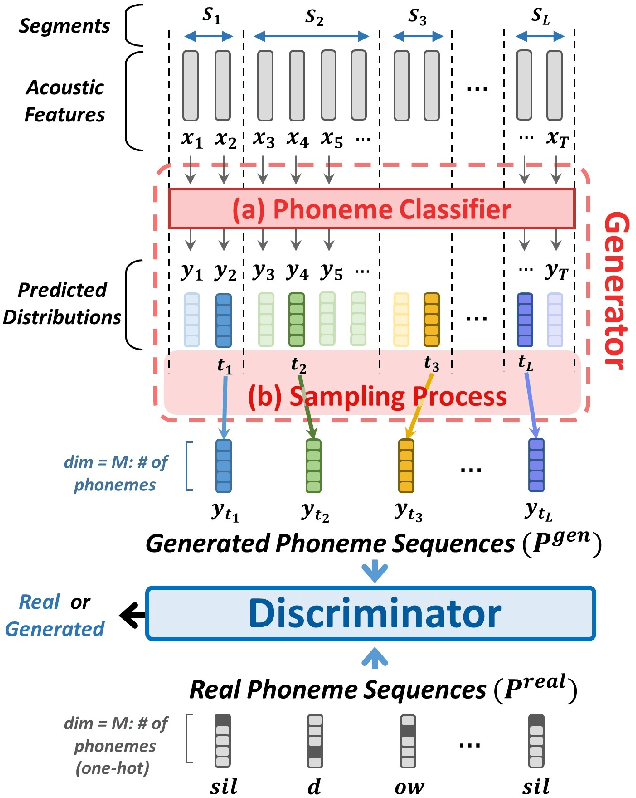
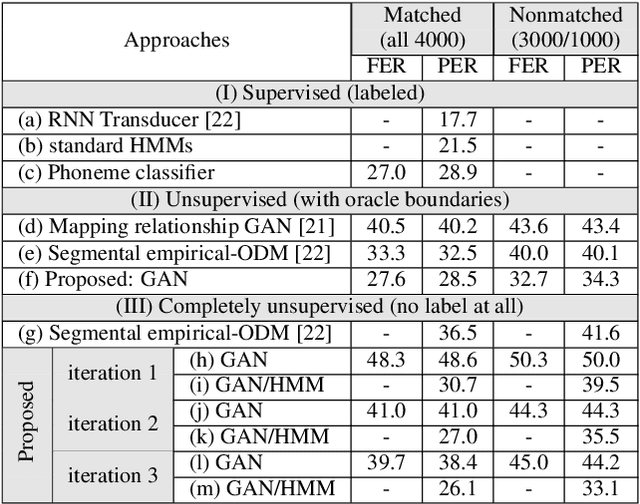
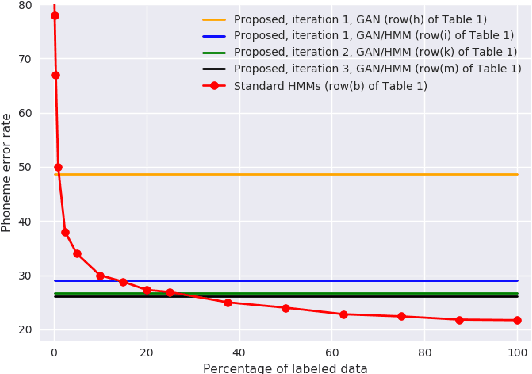
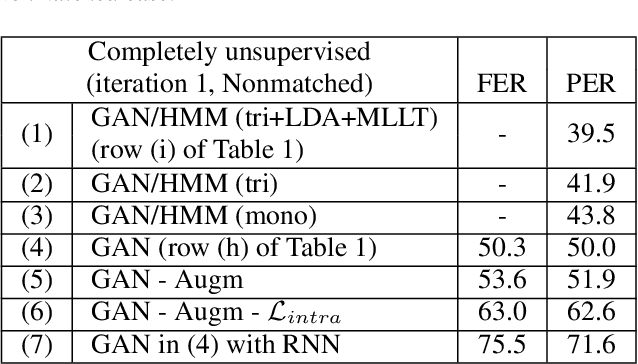
Producing a large annotated speech corpus for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced, but collecting a relatively big unlabeled data set for such languages is more achievable. This is why some initial effort have been reported on completely unsupervised speech recognition learned from unlabeled data only, although with relatively high error rates. In this paper, we develop a Generative Adversarial Network (GAN) to achieve this purpose, in which a Generator and a Discriminator learn from each other iteratively to improve the performance. We further use a set of Hidden Markov Models (HMMs) iteratively refined from the machine generated labels to work in harmony with the GAN. The initial experiments on TIMIT data set achieve an phone error rate of 33.1%, which is 8.5% lower than the previous state-of-the-art.
Completely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings
Apr 01, 2018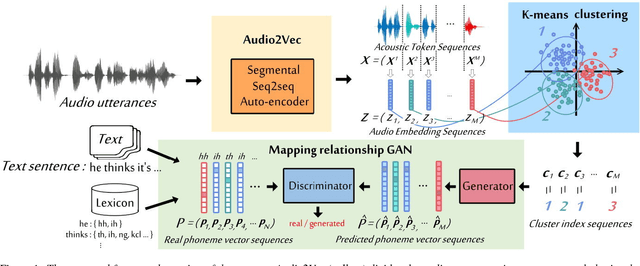

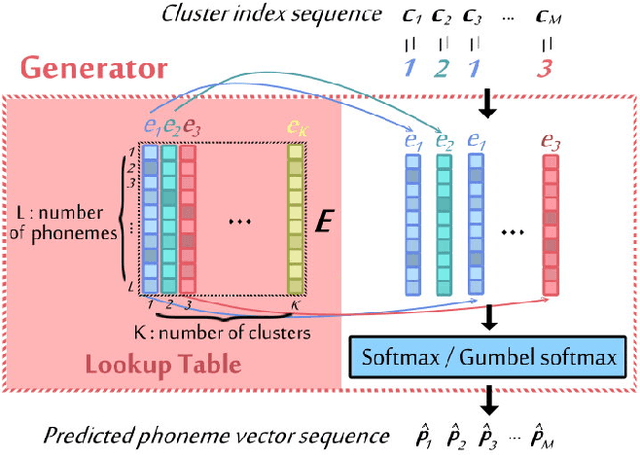
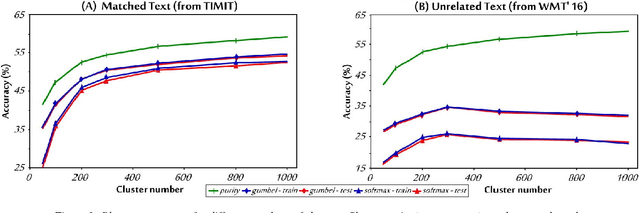
Unsupervised discovery of acoustic tokens from audio corpora without annotation and learning vector representations for these tokens have been widely studied. Although these techniques have been shown successful in some applications such as query-by-example Spoken Term Detection (STD), the lack of mapping relationships between these discovered tokens and real phonemes have limited the down-stream applications. This paper represents probably the first attempt towards the goal of completely unsupervised phoneme recognition, or mapping audio signals to phoneme sequences without phoneme-labeled audio data. The basic idea is to cluster the embedded acoustic tokens and learn the mapping between the cluster sequences and the unknown phoneme sequences with a Generative Adversarial Network (GAN). An unsupervised phoneme recognition accuracy of 36% was achieved in the preliminary experiments.
Attention-based Memory Selection Recurrent Network for Language Modeling
Nov 26, 2016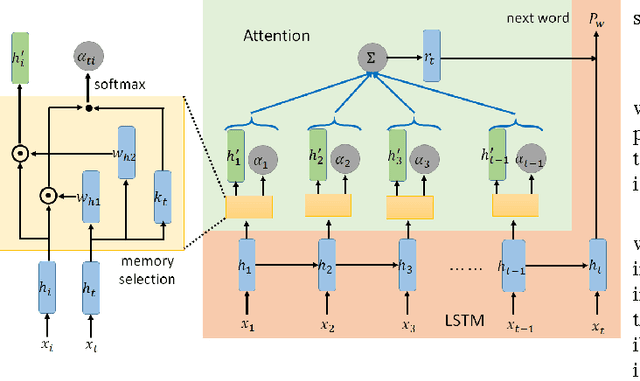
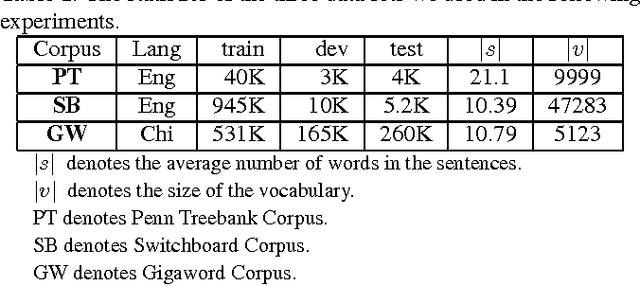


Recurrent neural networks (RNNs) have achieved great success in language modeling. However, since the RNNs have fixed size of memory, their memory cannot store all the information about the words it have seen before in the sentence, and thus the useful long-term information may be ignored when predicting the next words. In this paper, we propose Attention-based Memory Selection Recurrent Network (AMSRN), in which the model can review the information stored in the memory at each previous time step and select the relevant information to help generate the outputs. In AMSRN, the attention mechanism finds the time steps storing the relevant information in the memory, and memory selection determines which dimensions of the memory are involved in computing the attention weights and from which the information is extracted.In the experiments, AMSRN outperformed long short-term memory (LSTM) based language models on both English and Chinese corpora. Moreover, we investigate using entropy as a regularizer for attention weights and visualize how the attention mechanism helps language modeling.