 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity in Partially Controllable Linear Systems
Oct 12, 2021
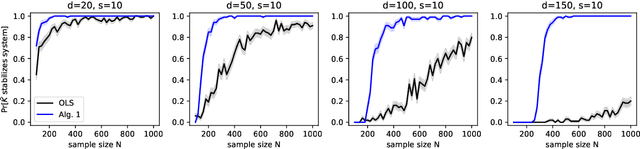
A fundamental concept in control theory is that of controllability, where any system state can be reached through an appropriate choice of control inputs. Indeed, a large body of classical and modern approaches are designed for controllable linear dynamical systems. However, in practice, we often encounter systems in which a large set of state variables evolve exogenously and independently of the control inputs; such systems are only \emph{partially controllable}. The focus of this work is on a large class of partially controllable linear dynamical systems, specified by an underlying sparsity pattern. Our main results establish structural conditions and finite-sample guarantees for learning to control such systems. In particular, our structural results characterize those state variables which are irrelevant for optimal control, an analysis which departs from classical control techniques. Our algorithmic results adapt techniques from high-dimensional statistics -- specifically soft-thresholding and semiparametric least-squares -- to exploit the underlying sparsity pattern in order to obtain finite-sample guarantees that significantly improve over those based on certainty-equivalence. We also corroborate these theoretical improvements over certainty-equivalent control through a simulation study.
Acceleration via Fractal Learning Rate Schedules
Mar 01, 2021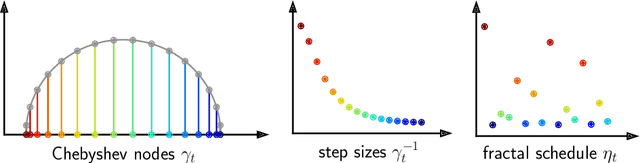
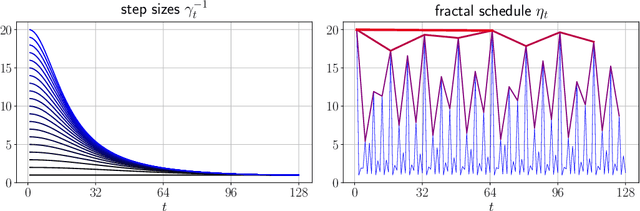
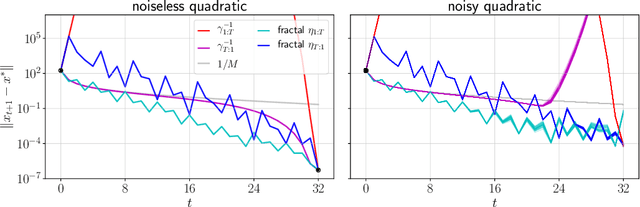
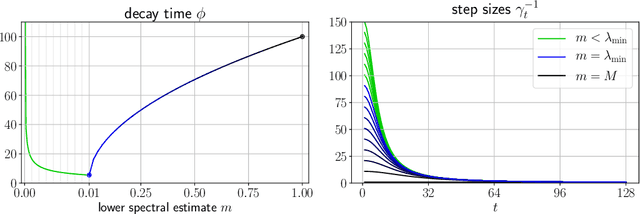
When balancing the practical tradeoffs of iterative methods for large-scale optimization, the learning rate schedule remains notoriously difficult to understand and expensive to tune. We demonstrate the presence of these subtleties even in the innocuous case when the objective is a convex quadratic. We reinterpret an iterative algorithm from the numerical analysis literature as what we call the Chebyshev learning rate schedule for accelerating vanilla gradient descent, and show that the problem of mitigating instability leads to a fractal ordering of step sizes. We provide some experiments and discussion to challenge current understandings of the "edge of stability" in deep learning: even in simple settings, provable acceleration can be obtained by making negative local progress on the objective.
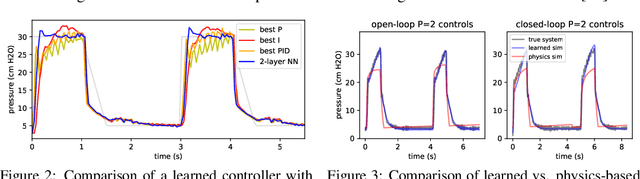
Machine Learning for Mechanical Ventilation Control
Feb 26, 2021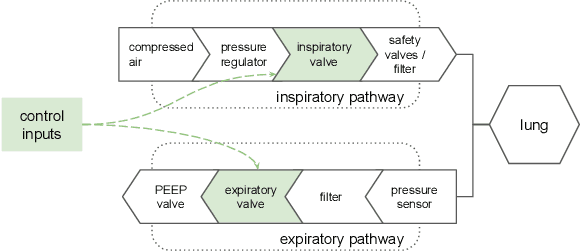
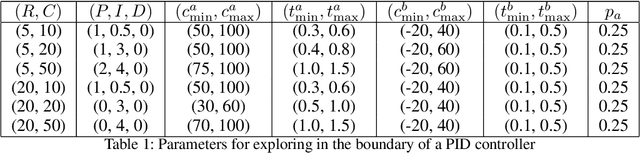
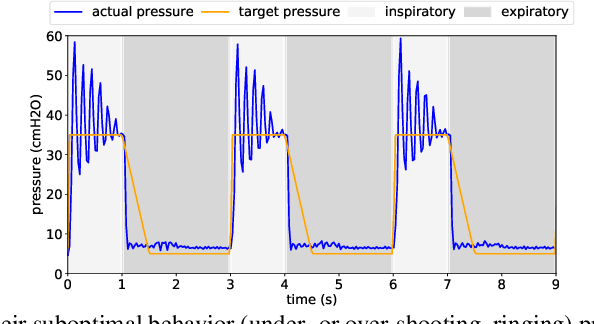
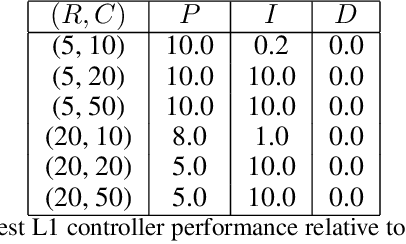
We consider the problem of controlling an invasive mechanical ventilator for pressure-controlled ventilation: a controller must let air in and out of a sedated patient's lungs according to a trajectory of airway pressures specified by a clinician. Hand-tuned PID controllers and similar variants have comprised the industry standard for decades, yet can behave poorly by over- or under-shooting their target or oscillating rapidly. We consider a data-driven machine learning approach: First, we train a simulator based on data we collect from an artificial lung. Then, we train deep neural network controllers on these simulators.We show that our controllers are able to track target pressure waveforms significantly better than PID controllers. We further show that a learned controller generalizes across lungs with varying characteristics much more readily than PID controllers do.
Deluca -- A Differentiable Control Library: Environments, Methods, and Benchmarking
Feb 19, 2021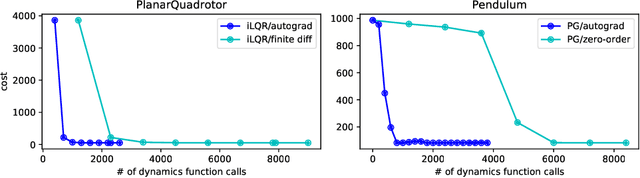
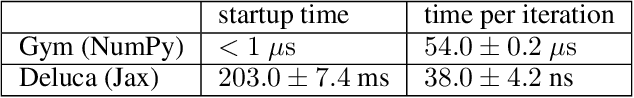
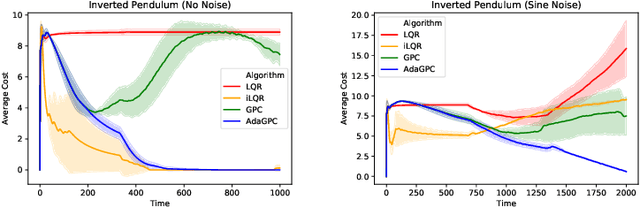
We present an open-source library of natively differentiable physics and robotics environments, accompanied by gradient-based control methods and a benchmark-ing suite. The introduced environments allow auto-differentiation through the simulation dynamics, and thereby permit fast training of controllers. The library features several popular environments, including classical control settings from OpenAI Gym. We also provide a novel differentiable environment, based on deep neural networks, that simulates medical ventilation. We give several use-cases of new scientific results obtained using the library. This includes a medical ventilator simulator and controller, an adaptive control method for time-varying linear dynamical systems, and new gradient-based methods for control of linear dynamical systems with adversarial perturbations.
Stochastic Optimization with Laggard Data Pipelines
Oct 26, 2020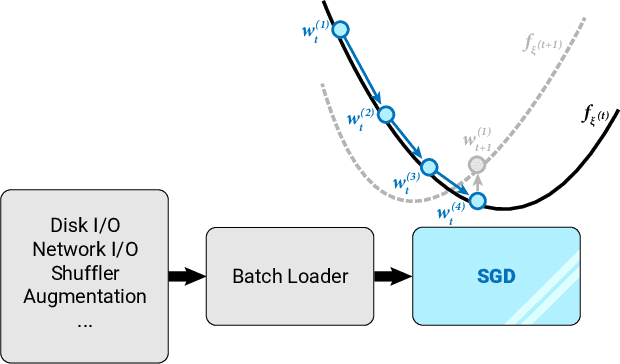
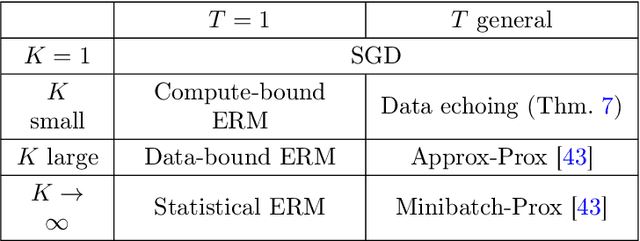
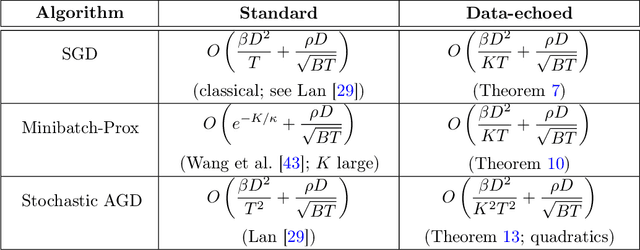
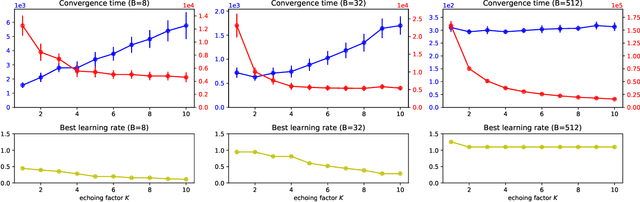
State-of-the-art optimization is steadily shifting towards massively parallel pipelines with extremely large batch sizes. As a consequence, CPU-bound preprocessing and disk/memory/network operations have emerged as new performance bottlenecks, as opposed to hardware-accelerated gradient computations. In this regime, a recently proposed approach is data echoing (Choi et al., 2019), which takes repeated gradient steps on the same batch while waiting for fresh data to arrive from upstream. We provide the first convergence analyses of "data-echoed" extensions of common optimization methods, showing that they exhibit provable improvements over their synchronous counterparts. Specifically, we show that in convex optimization with stochastic minibatches, data echoing affords speedups on the curvature-dominated part of the convergence rate, while maintaining the optimal statistical rate.
Disentangling Adaptive Gradient Methods from Learning Rates
Feb 26, 2020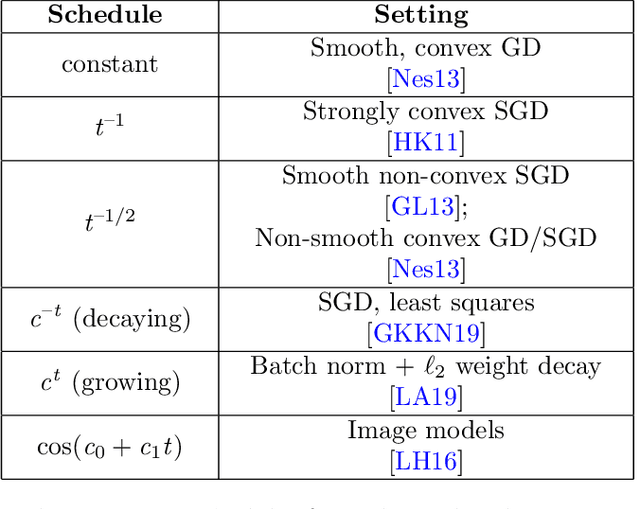
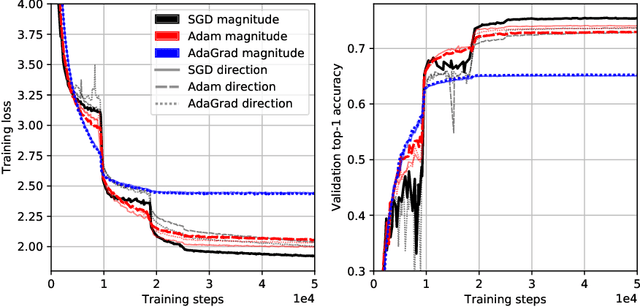

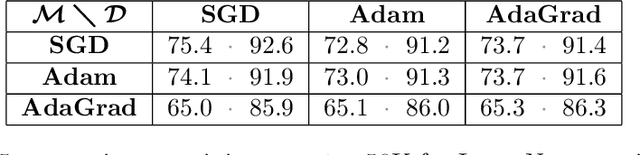
We investigate several confounding factors in the evaluation of optimization algorithms for deep learning. Primarily, we take a deeper look at how adaptive gradient methods interact with the learning rate schedule, a notoriously difficult-to-tune hyperparameter which has dramatic effects on the convergence and generalization of neural network training. We introduce a "grafting" experiment which decouples an update's magnitude from its direction, finding that many existing beliefs in the literature may have arisen from insufficient isolation of the implicit schedule of step sizes. Alongside this contribution, we present some empirical and theoretical retrospectives on the generalization of adaptive gradient methods, aimed at bringing more clarity to this space.
No-Regret Prediction in Marginally Stable Systems
Feb 20, 2020We consider the problem of online prediction in a marginally stable linear dynamical system subject to bounded adversarial or (non-isotropic) stochastic perturbations. This poses two challenges. Firstly, the system is in general unidentifiable, so recent and classical results on parameter recovery do not apply. Secondly, because we allow the system to be marginally stable, the state can grow polynomially with time; this causes standard regret bounds in online convex optimization to be vacuous. In spite of these challenges, we show that the online least-squares algorithm achieves sublinear regret (improvable to polylogarithmic in the stochastic setting), with polynomial dependence on the system's parameters. This requires a refined regret analysis, including a structural lemma showing the current state of the system to be a small linear combination of past states, even if the state grows polynomially. By applying our techniques to learning an autoregressive filter, we also achieve logarithmic regret in the partially observed setting under Gaussian noise, with polynomial dependence on the memory of the associated Kalman filter.
Calibration, Entropy Rates, and Memory in Language Models
Jun 11, 2019

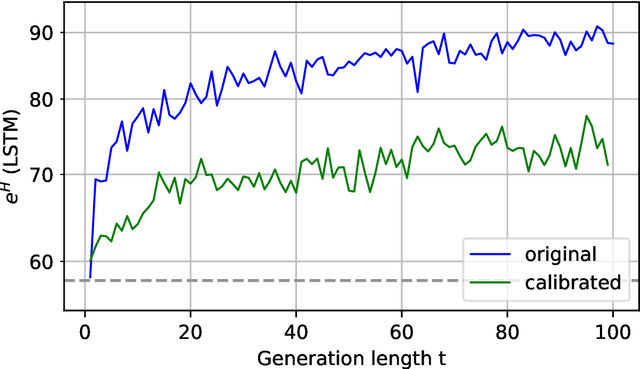
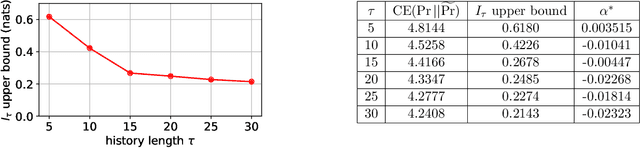
Building accurate language models that capture meaningful long-term dependencies is a core challenge in natural language processing. Towards this end, we present a calibration-based approach to measure long-term discrepancies between a generative sequence model and the true distribution, and use these discrepancies to improve the model. Empirically, we show that state-of-the-art language models, including LSTMs and Transformers, are \emph{miscalibrated}: the entropy rates of their generations drift dramatically upward over time. We then provide provable methods to mitigate this phenomenon. Furthermore, we show how this calibration-based approach can also be used to measure the amount of memory that language models use for prediction.
Robust guarantees for learning an autoregressive filter
May 23, 2019The optimal predictor for a linear dynamical system (with hidden state and Gaussian noise) takes the form of an autoregressive linear filter, namely the Kalman filter. However, a fundamental problem in reinforcement learning and control theory is to make optimal predictions in an unknown dynamical system. To this end, we take the approach of directly learning an autoregressive filter for time-series prediction under unknown dynamics. Our analysis differs from previous statistical analyses in that we regress not only on the inputs to the dynamical system, but also the outputs, which is essential to dealing with process noise. The main challenge is to estimate the filter under worst case input (in $\mathcal H_\infty$ norm), for which we use an $L^\infty$-based objective rather than ordinary least-squares. For learning an autoregressive model, our algorithm has optimal sample complexity in terms of the rollout length, which does not seem to be attained by naive least-squares.
Extreme Tensoring for Low-Memory Preconditioning
Feb 12, 2019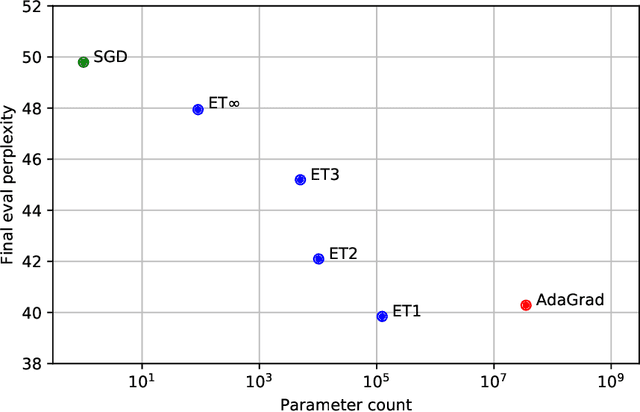
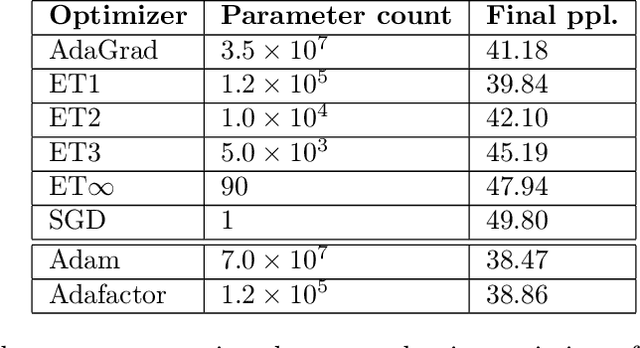

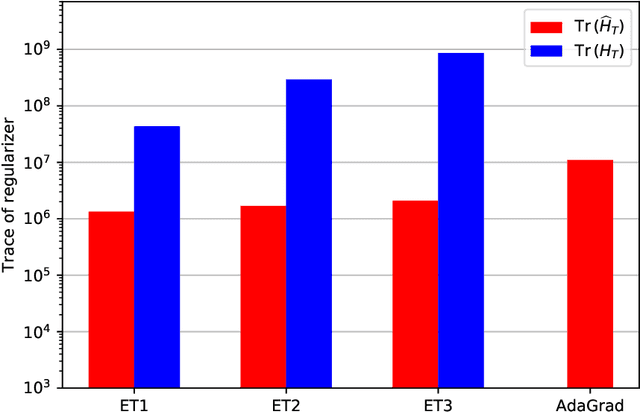
State-of-the-art models are now trained with billions of parameters, reaching hardware limits in terms of memory consumption. This has created a recent demand for memory-efficient optimizers. To this end, we investigate the limits and performance tradeoffs of memory-efficient adaptively preconditioned gradient methods. We propose extreme tensoring for high-dimensional stochastic optimization, showing that an optimizer needs very little memory to benefit from adaptive preconditioning. Our technique applies to arbitrary models (not necessarily with tensor-shaped parameters), and is accompanied by regret and convergence guarantees, which shed light on the tradeoffs between preconditioner quality and expressivity. On a large-scale NLP model, we reduce the optimizer memory overhead by three orders of magnitude, without degrading performance.