 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
MetricNet: Recovering Metric Scale in Generative Navigation Policies
Sep 17, 2025Generative navigation policies have made rapid progress in improving end-to-end learned navigation. Despite their promising results, this paradigm has two structural problems. First, the sampled trajectories exist in an abstract, unscaled space without metric grounding. Second, the control strategy discards the full path, instead moving directly towards a single waypoint. This leads to short-sighted and unsafe actions, moving the robot towards obstacles that a complete and correctly scaled path would circumvent. To address these issues, we propose MetricNet, an effective add-on for generative navigation that predicts the metric distance between waypoints, grounding policy outputs in real-world coordinates. We evaluate our method in simulation with a new benchmarking framework and show that executing MetricNet-scaled waypoints significantly improves both navigation and exploration performance. Beyond simulation, we further validate our approach in real-world experiments. Finally, we propose MetricNav, which integrates MetricNet into a navigation policy to guide the robot away from obstacles while still moving towards the goal.
CAViAR: Critic-Augmented Video Agentic Reasoning
Sep 09, 2025Video understanding has seen significant progress in recent years, with models' performance on perception from short clips continuing to rise. Yet, multiple recent benchmarks, such as LVBench, Neptune, and ActivityNet-RTL, show performance wanes for tasks requiring complex reasoning on videos as queries grow more complex and videos grow longer. In this work, we ask: can existing perception capabilities be leveraged to successfully perform more complex video reasoning? In particular, we develop a large language model agent given access to video modules as subagents or tools. Rather than following a fixed procedure to solve queries as in previous work such as Visual Programming, ViperGPT, and MoReVQA, the agent uses the results of each call to a module to determine subsequent steps. Inspired by work in the textual reasoning domain, we introduce a critic to distinguish between instances of successful and unsuccessful sequences from the agent. We show that the combination of our agent and critic achieve strong performance on the previously-mentioned datasets.
VoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation
Jun 12, 2025Robotic manipulation faces a significant challenge in generalizing across unseen objects, environments and tasks specified by diverse language instructions. To improve generalization capabilities, recent research has incorporated large language models (LLMs) for planning and action execution. While promising, these methods often fall short in generating grounded plans in visual environments. Although efforts have been made to perform visual instructional tuning on LLMs for robotic manipulation, existing methods are typically constrained by single-view image input and struggle with precise object grounding. In this work, we introduce Gondola, a novel grounded vision-language planning model based on LLMs for generalizable robotic manipulation. Gondola takes multi-view images and history plans to produce the next action plan with interleaved texts and segmentation masks of target objects and locations. To support the training of Gondola, we construct three types of datasets using the RLBench simulator, namely robot grounded planning, multi-view referring expression and pseudo long-horizon task datasets. Gondola outperforms the state-of-the-art LLM-based method across all four generalization levels of the GemBench dataset, including novel placements, rigid objects, articulated objects and long-horizon tasks.
ComposeAnything: Composite Object Priors for Text-to-Image Generation
May 30, 2025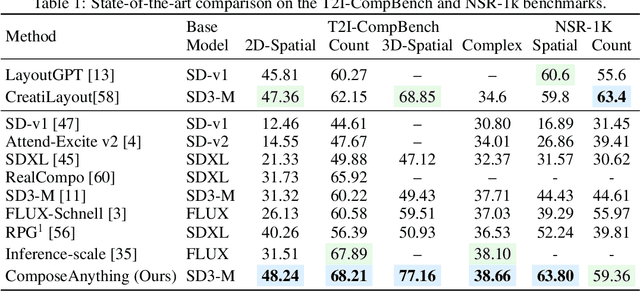
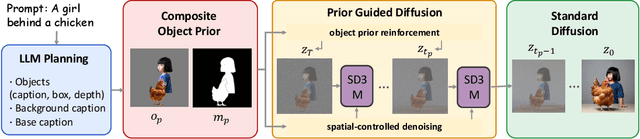
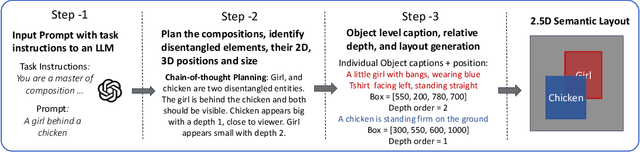
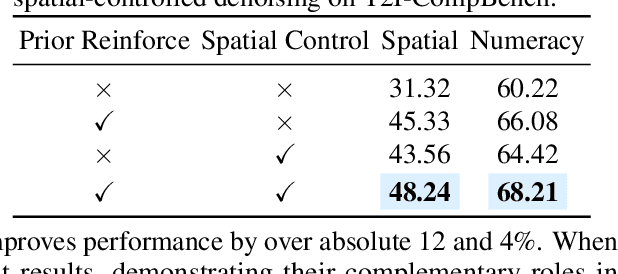
Generating images from text involving complex and novel object arrangements remains a significant challenge for current text-to-image (T2I) models. Although prior layout-based methods improve object arrangements using spatial constraints with 2D layouts, they often struggle to capture 3D positioning and sacrifice quality and coherence. In this work, we introduce ComposeAnything, a novel framework for improving compositional image generation without retraining existing T2I models. Our approach first leverages the chain-of-thought reasoning abilities of LLMs to produce 2.5D semantic layouts from text, consisting of 2D object bounding boxes enriched with depth information and detailed captions. Based on this layout, we generate a spatial and depth aware coarse composite of objects that captures the intended composition, serving as a strong and interpretable prior that replaces stochastic noise initialization in diffusion-based T2I models. This prior guides the denoising process through object prior reinforcement and spatial-controlled denoising, enabling seamless generation of compositional objects and coherent backgrounds, while allowing refinement of inaccurate priors. ComposeAnything outperforms state-of-the-art methods on the T2I-CompBench and NSR-1K benchmarks for prompts with 2D/3D spatial arrangements, high object counts, and surreal compositions. Human evaluations further demonstrate that our model generates high-quality images with compositions that faithfully reflect the text.
Feasibility with Language Models for Open-World Compositional Zero-Shot Learning
May 16, 2025Humans can easily tell if an attribute (also called state) is realistic, i.e., feasible, for an object, e.g. fire can be hot, but it cannot be wet. In Open-World Compositional Zero-Shot Learning, when all possible state-object combinations are considered as unseen classes, zero-shot predictors tend to perform poorly. Our work focuses on using external auxiliary knowledge to determine the feasibility of state-object combinations. Our Feasibility with Language Model (FLM) is a simple and effective approach that leverages Large Language Models (LLMs) to better comprehend the semantic relationships between states and objects. FLM involves querying an LLM about the feasibility of a given pair and retrieving the output logit for the positive answer. To mitigate potential misguidance of the LLM given that many of the state-object compositions are rare or completely infeasible, we observe that the in-context learning ability of LLMs is essential. We present an extensive study identifying Vicuna and ChatGPT as best performing, and we demonstrate that our FLM consistently improves OW-CZSL performance across all three benchmarks.
LoFT: LoRA-fused Training Dataset Generation with Few-shot Guidance
May 16, 2025Despite recent advances in text-to-image generation, using synthetically generated data seldom brings a significant boost in performance for supervised learning. Oftentimes, synthetic datasets do not faithfully recreate the data distribution of real data, i.e., they lack the fidelity or diversity needed for effective downstream model training. While previous work has employed few-shot guidance to address this issue, existing methods still fail to capture and generate features unique to specific real images. In this paper, we introduce a novel dataset generation framework named LoFT, LoRA-Fused Training-data Generation with Few-shot Guidance. Our method fine-tunes LoRA weights on individual real images and fuses them at inference time, producing synthetic images that combine the features of real images for improved diversity and fidelity of generated data. We evaluate the synthetic data produced by LoFT on 10 datasets, using 8 to 64 real images per class as guidance and scaling up to 1000 images per class. Our experiments show that training on LoFT-generated data consistently outperforms other synthetic dataset methods, significantly increasing accuracy as the dataset size increases. Additionally, our analysis demonstrates that LoFT generates datasets with high fidelity and sufficient diversity, which contribute to the performance improvement. The code is available at https://github.com/ExplainableML/LoFT.
MINERVA: Evaluating Complex Video Reasoning
May 01, 2025Multimodal LLMs are turning their focus to video benchmarks, however most video benchmarks only provide outcome supervision, with no intermediate or interpretable reasoning steps. This makes it challenging to assess if models are truly able to combine perceptual and temporal information to reason about videos, or simply get the correct answer by chance or by exploiting linguistic biases. To remedy this, we provide a new video reasoning dataset called MINERVA for modern multimodal models. Each question in the dataset comes with 5 answer choices, as well as detailed, hand-crafted reasoning traces. Our dataset is multimodal, diverse in terms of video domain and length, and consists of complex multi-step questions. Extensive benchmarking shows that our dataset provides a challenge for frontier open-source and proprietary models. We perform fine-grained error analysis to identify common failure modes across various models, and create a taxonomy of reasoning errors. We use this to explore both human and LLM-as-a-judge methods for scoring video reasoning traces, and find that failure modes are primarily related to temporal localization, followed by visual perception errors, as opposed to logical or completeness errors. The dataset, along with questions, answer candidates and reasoning traces will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva.
Memory-Modular Classification: Learning to Generalize with Memory Replacement
Apr 08, 2025We propose a novel memory-modular learner for image classification that separates knowledge memorization from reasoning. Our model enables effective generalization to new classes by simply replacing the memory contents, without the need for model retraining. Unlike traditional models that encode both world knowledge and task-specific skills into their weights during training, our model stores knowledge in the external memory of web-crawled image and text data. At inference time, the model dynamically selects relevant content from the memory based on the input image, allowing it to adapt to arbitrary classes by simply replacing the memory contents. The key differentiator that our learner meta-learns to perform classification tasks with noisy web data from unseen classes, resulting in robust performance across various classification scenarios. Experimental results demonstrate the promising performance and versatility of our approach in handling diverse classification tasks, including zero-shot/few-shot classification of unseen classes, fine-grained classification, and class-incremental classification.