 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Stable Semi-Supervised Remote Sensing Segmentation via Co-Guidance and Co-Fusion
Dec 28, 2025Semi-supervised remote sensing (RS) image semantic segmentation offers a promising solution to alleviate the burden of exhaustive annotation, yet it fundamentally struggles with pseudo-label drift, a phenomenon where confirmation bias leads to the accumulation of errors during training. In this work, we propose Co2S, a stable semi-supervised RS segmentation framework that synergistically fuses priors from vision-language models and self-supervised models. Specifically, we construct a heterogeneous dual-student architecture comprising two distinct ViT-based vision foundation models initialized with pretrained CLIP and DINOv3 to mitigate error accumulation and pseudo-label drift. To effectively incorporate these distinct priors, an explicit-implicit semantic co-guidance mechanism is introduced that utilizes text embeddings and learnable queries to provide explicit and implicit class-level guidance, respectively, thereby jointly enhancing semantic consistency. Furthermore, a global-local feature collaborative fusion strategy is developed to effectively fuse the global contextual information captured by CLIP with the local details produced by DINOv3, enabling the model to generate highly precise segmentation results. Extensive experiments on six popular datasets demonstrate the superiority of the proposed method, which consistently achieves leading performance across various partition protocols and diverse scenarios. Project page is available at https://xavierjiezou.github.io/Co2S/.
Query-aware Hub Prototype Learning for Few-Shot 3D Point Cloud Semantic Segmentation
Dec 09, 2025Few-shot 3D point cloud semantic segmentation (FS-3DSeg) aims to segment novel classes with only a few labeled samples. However, existing metric-based prototype learning methods generate prototypes solely from the support set, without considering their relevance to query data. This often results in prototype bias, where prototypes overfit support-specific characteristics and fail to generalize to the query distribution, especially in the presence of distribution shifts, which leads to degraded segmentation performance. To address this issue, we propose a novel Query-aware Hub Prototype (QHP) learning method that explicitly models semantic correlations between support and query sets. Specifically, we propose a Hub Prototype Generation (HPG) module that constructs a bipartite graph connecting query and support points, identifies frequently linked support hubs, and generates query-relevant prototypes that better capture cross-set semantics. To further mitigate the influence of bad hubs and ambiguous prototypes near class boundaries, we introduce a Prototype Distribution Optimization (PDO) module, which employs a purity-reweighted contrastive loss to refine prototype representations by pulling bad hubs and outlier prototypes closer to their corresponding class centers. Extensive experiments on S3DIS and ScanNet demonstrate that QHP achieves substantial performance gains over state-of-the-art methods, effectively narrowing the semantic gap between prototypes and query sets in FS-3DSeg.
Dynamic Dictionary Learning for Remote Sensing Image Segmentation
Mar 09, 2025Remote sensing image segmentation faces persistent challenges in distinguishing morphologically similar categories and adapting to diverse scene variations. While existing methods rely on implicit representation learning paradigms, they often fail to dynamically adjust semantic embeddings according to contextual cues, leading to suboptimal performance in fine-grained scenarios such as cloud thickness differentiation. This work introduces a dynamic dictionary learning framework that explicitly models class ID embeddings through iterative refinement. The core contribution lies in a novel dictionary construction mechanism, where class-aware semantic embeddings are progressively updated via multi-stage alternating cross-attention querying between image features and dictionary embeddings. This process enables adaptive representation learning tailored to input-specific characteristics, effectively resolving ambiguities in intra-class heterogeneity and inter-class homogeneity. To further enhance discriminability, a contrastive constraint is applied to the dictionary space, ensuring compact intra-class distributions while maximizing inter-class separability. Extensive experiments across both coarse- and fine-grained datasets demonstrate consistent improvements over state-of-the-art methods, particularly in two online test benchmarks (LoveDA and UAVid). Code is available at https://anonymous.4open.science/r/D2LS-8267/.
Knowledge Transfer and Domain Adaptation for Fine-Grained Remote Sensing Image Segmentation
Dec 09, 2024



Fine-grained remote sensing image segmentation is essential for accurately identifying detailed objects in remote sensing images. Recently, vision transformer models (VTM) pretrained on large-scale datasets have shown strong zero-shot generalization, indicating that they have learned the general knowledge of object understanding. We introduce a novel end-to-end learning paradigm combining knowledge guidance with domain refinement to enhance performance. We present two key components: the Feature Alignment Module (FAM) and the Feature Modulation Module (FMM). FAM aligns features from a CNN-based backbone with those from the pretrained VTM's encoder using channel transformation and spatial interpolation, and transfers knowledge via KL divergence and L2 normalization constraint. FMM further adapts the knowledge to the specific domain to address domain shift. We also introduce a fine-grained grass segmentation dataset and demonstrate, through experiments on two datasets, that our method achieves a significant improvement of 2.57 mIoU on the grass dataset and 3.73 mIoU on the cloud dataset. The results highlight the potential of combining knowledge transfer and domain adaptation to overcome domain-related challenges and data limitations. The project page is available at https://xavierjiezou.github.io/KTDA/.
Adapting Vision Foundation Models for Robust Cloud Segmentation in Remote Sensing Images
Nov 20, 2024



Cloud segmentation is a critical challenge in remote sensing image interpretation, as its accuracy directly impacts the effectiveness of subsequent data processing and analysis. Recently, vision foundation models (VFM) have demonstrated powerful generalization capabilities across various visual tasks. In this paper, we present a parameter-efficient adaptive approach, termed Cloud-Adapter, designed to enhance the accuracy and robustness of cloud segmentation. Our method leverages a VFM pretrained on general domain data, which remains frozen, eliminating the need for additional training. Cloud-Adapter incorporates a lightweight spatial perception module that initially utilizes a convolutional neural network (ConvNet) to extract dense spatial representations. These multi-scale features are then aggregated and serve as contextual inputs to an adapting module, which modulates the frozen transformer layers within the VFM. Experimental results demonstrate that the Cloud-Adapter approach, utilizing only 0.6% of the trainable parameters of the frozen backbone, achieves substantial performance gains. Cloud-Adapter consistently attains state-of-the-art (SOTA) performance across a wide variety of cloud segmentation datasets from multiple satellite sources, sensor series, data processing levels, land cover scenarios, and annotation granularities. We have released the source code and pretrained models at https://github.com/XavierJiezou/Cloud-Adapter to support further research.
GrassNet: State Space Model Meets Graph Neural Network
Aug 16, 2024



Designing spectral convolutional networks is a formidable task in graph learning. In traditional spectral graph neural networks (GNNs), polynomial-based methods are commonly used to design filters via the Laplacian matrix. In practical applications, however, these polynomial methods encounter inherent limitations, which primarily arise from the the low-order truncation of polynomial filters and the lack of overall modeling of the graph spectrum. This leads to poor performance of existing spectral approaches on real-world graph data, especially when the spectrum is highly concentrated or contains many numerically identical values, as they tend to apply the exact same modulation to signals with the same frequencies. To overcome these issues, in this paper, we propose Graph State Space Network (GrassNet), a novel graph neural network with theoretical support that provides a simple yet effective scheme for designing and learning arbitrary graph spectral filters. In particular, our GrassNet introduces structured state space models (SSMs) to model the correlations of graph signals at different frequencies and derives a unique rectification for each frequency in the graph spectrum. To the best of our knowledge, our work is the first to employ SSMs for the design of GNN spectral filters, and it theoretically offers greater expressive power compared with polynomial filters. Extensive experiments on nine public benchmarks reveal that GrassNet achieves superior performance in real-world graph modeling tasks.
DFA-GNN: Forward Learning of Graph Neural Networks by Direct Feedback Alignment
Jun 04, 2024



Graph neural networks are recognized for their strong performance across various applications, with the backpropagation algorithm playing a central role in the development of most GNN models. However, despite its effectiveness, BP has limitations that challenge its biological plausibility and affect the efficiency, scalability and parallelism of training neural networks for graph-based tasks. While several non-BP training algorithms, such as the direct feedback alignment, have been successfully applied to fully-connected and convolutional network components for handling Euclidean data, directly adapting these non-BP frameworks to manage non-Euclidean graph data in GNN models presents significant challenges. These challenges primarily arise from the violation of the i.i.d. assumption in graph data and the difficulty in accessing prediction errors for all samples (nodes) within the graph. To overcome these obstacles, in this paper we propose DFA-GNN, a novel forward learning framework tailored for GNNs with a case study of semi-supervised learning. The proposed method breaks the limitations of BP by using a dedicated forward training mechanism. Specifically, DFA-GNN extends the principles of DFA to adapt to graph data and unique architecture of GNNs, which incorporates the information of graph topology into the feedback links to accommodate the non-Euclidean characteristics of graph data. Additionally, for semi-supervised graph learning tasks, we developed a pseudo error generator that spreads residual errors from training data to create a pseudo error for each unlabeled node. These pseudo errors are then utilized to train GNNs using DFA. Extensive experiments on 10 public benchmarks reveal that our learning framework outperforms not only previous non-BP methods but also the standard BP methods, and it exhibits excellent robustness against various types of noise and attacks.
The Cascaded Forward Algorithm for Neural Network Training
Mar 24, 2023



Backpropagation algorithm has been widely used as a mainstream learning procedure for neural networks in the past decade, and has played a significant role in the development of deep learning. However, there exist some limitations associated with this algorithm, such as getting stuck in local minima and experiencing vanishing/exploding gradients, which have led to questions about its biological plausibility. To address these limitations, alternative algorithms to backpropagation have been preliminarily explored, with the Forward-Forward (FF) algorithm being one of the most well-known. In this paper we propose a new learning framework for neural networks, namely Cascaded Forward (CaFo) algorithm, which does not rely on BP optimization as that in FF. Unlike FF, our framework directly outputs label distributions at each cascaded block, which does not require generation of additional negative samples and thus leads to a more efficient process at both training and testing. Moreover, in our framework each block can be trained independently, so it can be easily deployed into parallel acceleration systems. The proposed method is evaluated on four public image classification benchmarks, and the experimental results illustrate significant improvement in prediction accuracy in comparison with the baseline.
Collaborative Perception in Autonomous Driving: Methods, Datasets and Challenges
Jan 16, 2023



Collaborative perception is essential to address occlusion and sensor failure issues in autonomous driving. In recent years, deep learning on collaborative perception has become even thriving, with numerous methods have been proposed. Although some works have reviewed and analyzed the basic architecture and key components in this field, there is still a lack of reviews on systematical collaboration modules in perception networks and large-scale collaborative perception datasets. The primary goal of this work is to address the abovementioned issues and provide a comprehensive review of recent achievements in this field. First, we introduce fundamental technologies and collaboration schemes. Following that, we provide an overview of practical collaborative perception methods and systematically summarize the collaboration modules in networks to improve collaboration efficiency and performance while also ensuring collaboration robustness and safety. Then, we present large-scale public datasets and summarize quantitative results on these benchmarks. Finally, we discuss the remaining challenges and promising future research directions.
Deep Probabilistic Graph Matching
Jan 05, 2022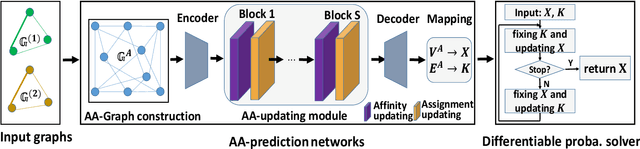
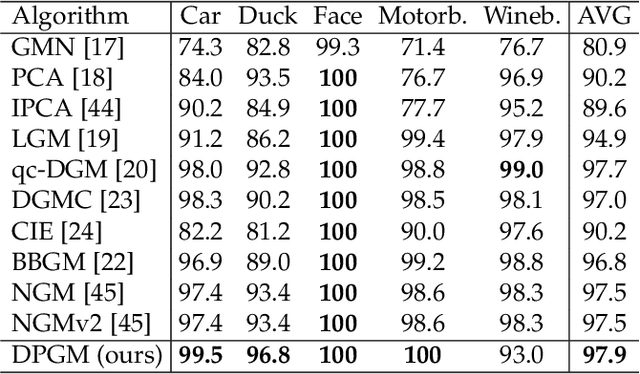
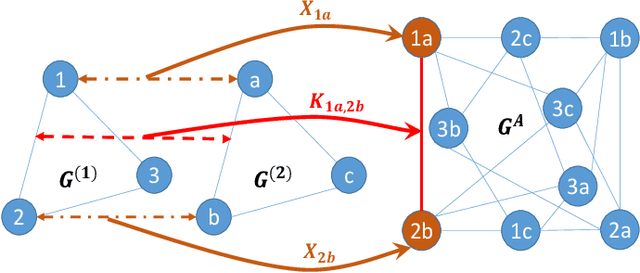
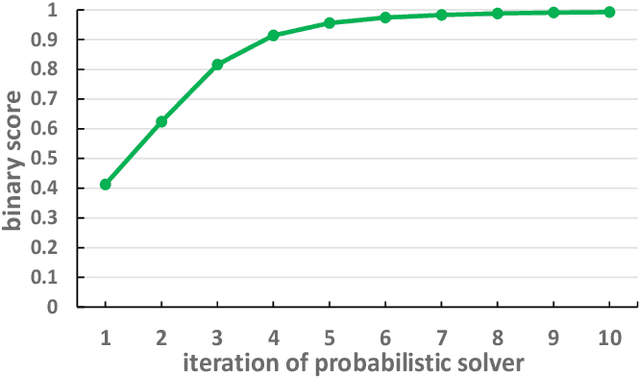
Most previous learning-based graph matching algorithms solve the \textit{quadratic assignment problem} (QAP) by dropping one or more of the matching constraints and adopting a relaxed assignment solver to obtain sub-optimal correspondences. Such relaxation may actually weaken the original graph matching problem, and in turn hurt the matching performance. In this paper we propose a deep learning-based graph matching framework that works for the original QAP without compromising on the matching constraints. In particular, we design an affinity-assignment prediction network to jointly learn the pairwise affinity and estimate the node assignments, and we then develop a differentiable solver inspired by the probabilistic perspective of the pairwise affinities. Aiming to obtain better matching results, the probabilistic solver refines the estimated assignments in an iterative manner to impose both discrete and one-to-one matching constraints. The proposed method is evaluated on three popularly tested benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms all previous state-of-the-arts on all benchmarks.