 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAKES: Scalable Vector Database for Embedding Search Service
May 18, 2025Modern deep learning models capture the semantics of complex data by transforming them into high-dimensional embedding vectors. Emerging applications, such as retrieval-augmented generation, use approximate nearest neighbor (ANN) search in the embedding vector space to find similar data. Existing vector databases provide indexes for efficient ANN searches, with graph-based indexes being the most popular due to their low latency and high recall in real-world high-dimensional datasets. However, these indexes are costly to build, suffer from significant contention under concurrent read-write workloads, and scale poorly to multiple servers. Our goal is to build a vector database that achieves high throughput and high recall under concurrent read-write workloads. To this end, we first propose an ANN index with an explicit two-stage design combining a fast filter stage with highly compressed vectors and a refine stage to ensure recall, and we devise a novel lightweight machine learning technique to fine-tune the index parameters. We introduce an early termination check to dynamically adapt the search process for each query. Next, we add support for writes while maintaining search performance by decoupling the management of the learned parameters. Finally, we design HAKES, a distributed vector database that serves the new index in a disaggregated architecture. We evaluate our index and system against 12 state-of-the-art indexes and three distributed vector databases, using high-dimensional embedding datasets generated by deep learning models. The experimental results show that our index outperforms index baselines in the high recall region and under concurrent read-write workloads. Furthermore, \namesys{} is scalable and achieves up to $16\times$ higher throughputs than the baselines. The HAKES project is open-sourced at https://www.comp.nus.edu.sg/~dbsystem/hakes/.
NeurDB: An AI-powered Autonomous Data System
May 07, 2024In the wake of rapid advancements in artificial intelligence (AI), we stand on the brink of a transformative leap in data systems. The imminent fusion of AI and DB (AIxDB) promises a new generation of data systems, which will relieve the burden on end-users across all industry sectors by featuring AI-enhanced functionalities, such as personalized and automated in-database AI-powered analytics, self-driving capabilities for improved system performance, etc. In this paper, we explore the evolution of data systems with a focus on deepening the fusion of AI and DB. We present NeurDB, our next-generation data system designed to fully embrace AI design in each major system component and provide in-database AI-powered analytics. We outline the conceptual and architectural overview of NeurDB, discuss its design choices and key components, and report its current development and future plan.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020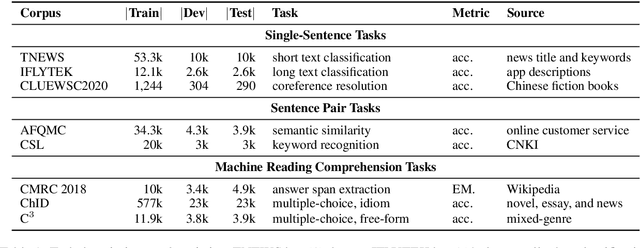
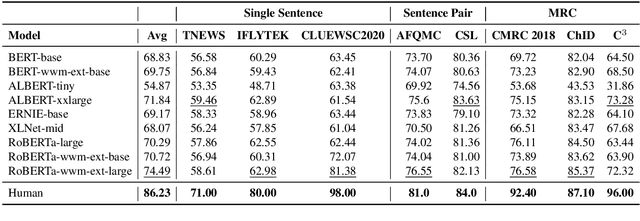
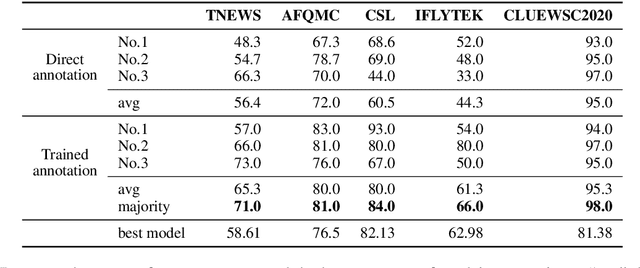
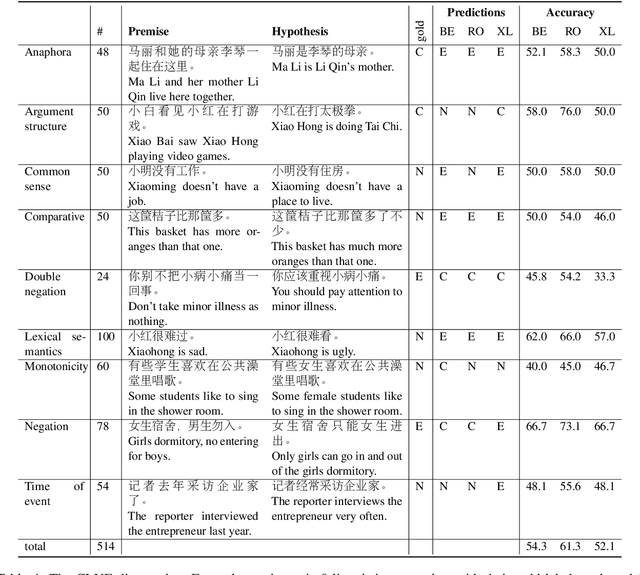
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.