 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp high-probability sample complexities for policy evaluation with linear function approximation
May 30, 2023This paper is concerned with the problem of policy evaluation with linear function approximation in discounted infinite horizon Markov decision processes. We investigate the sample complexities required to guarantee a predefined estimation error of the best linear coefficients for two widely-used policy evaluation algorithms: the temporal difference (TD) learning algorithm and the two-timescale linear TD with gradient correction (TDC) algorithm. In both the on-policy setting, where observations are generated from the target policy, and the off-policy setting, where samples are drawn from a behavior policy potentially different from the target policy, we establish the first sample complexity bound with high-probability convergence guarantee that attains the optimal dependence on the tolerance level. We also exhihit an explicit dependence on problem-related quantities, and show in the on-policy setting that our upper bound matches the minimax lower bound on crucial problem parameters, including the choice of the feature maps and the problem dimension.
E2TIMT: Efficient and Effective Modal Adapter for Text Image Machine Translation
May 10, 2023



Text image machine translation (TIMT) aims to translate texts embedded in images from one source language to another target language. Existing methods, both two-stage cascade and one-stage end-to-end architectures, suffer from different issues. The cascade models can benefit from the large-scale optical character recognition (OCR) and MT datasets but the two-stage architecture is redundant. The end-to-end models are efficient but suffer from training data deficiency. To this end, in our paper, we propose an end-to-end TIMT model fully making use of the knowledge from existing OCR and MT datasets to pursue both an effective and efficient framework. More specifically, we build a novel modal adapter effectively bridging the OCR encoder and MT decoder. End-to-end TIMT loss and cross-modal contrastive loss are utilized jointly to align the feature distribution of the OCR and MT tasks. Extensive experiments show that the proposed method outperforms the existing two-stage cascade models and one-stage end-to-end models with a lighter and faster architecture. Furthermore, the ablation studies verify the generalization of our method, where the proposed modal adapter is effective to bridge various OCR and MT models.
Multi-Teacher Knowledge Distillation For Text Image Machine Translation
May 10, 2023



Text image machine translation (TIMT) has been widely used in various real-world applications, which translates source language texts in images into another target language sentence. Existing methods on TIMT are mainly divided into two categories: the recognition-then-translation pipeline model and the end-to-end model. However, how to transfer knowledge from the pipeline model into the end-to-end model remains an unsolved problem. In this paper, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) method to effectively distillate knowledge into the end-to-end TIMT model from the pipeline model. Specifically, three teachers are utilized to improve the performance of the end-to-end TIMT model. The image encoder in the end-to-end TIMT model is optimized with the knowledge distillation guidance from the recognition teacher encoder, while the sequential encoder and decoder are improved by transferring knowledge from the translation sequential and decoder teacher models. Furthermore, both token and sentence-level knowledge distillations are incorporated to better boost the translation performance. Extensive experimental results show that our proposed MTKD effectively improves the text image translation performance and outperforms existing end-to-end and pipeline models with fewer parameters and less decoding time, illustrating that MTKD can take advantage of both pipeline and end-to-end models.
The Power of Preconditioning in Overparameterized Low-Rank Matrix Sensing
Feb 02, 2023



We propose $\textsf{ScaledGD($\lambda$)}$, a preconditioned gradient descent method to tackle the low-rank matrix sensing problem when the true rank is unknown, and when the matrix is possibly ill-conditioned. Using overparametrized factor representations, $\textsf{ScaledGD($\lambda$)}$ starts from a small random initialization, and proceeds by gradient descent with a specific form of damped preconditioning to combat bad curvatures induced by overparameterization and ill-conditioning. At the expense of light computational overhead incurred by preconditioners, $\textsf{ScaledGD($\lambda$)}$ is remarkably robust to ill-conditioning compared to vanilla gradient descent ($\textsf{GD}$) even with overprameterization. Specifically, we show that, under the Gaussian design, $\textsf{ScaledGD($\lambda$)}$ converges to the true low-rank matrix at a constant linear rate after a small number of iterations that scales only logarithmically with respect to the condition number and the problem dimension. This significantly improves over the convergence rate of vanilla $\textsf{GD}$ which suffers from a polynomial dependency on the condition number. Our work provides evidence on the power of preconditioning in accelerating the convergence without hurting generalization in overparameterized learning.
Improving End-to-End Text Image Translation From the Auxiliary Text Translation Task
Oct 08, 2022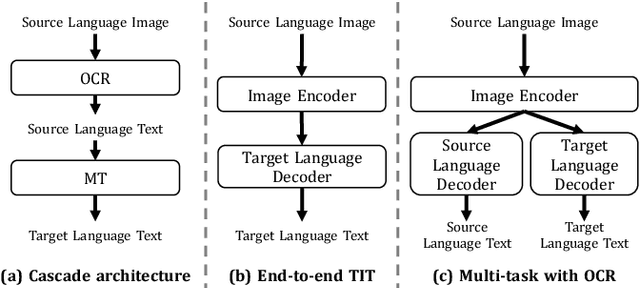
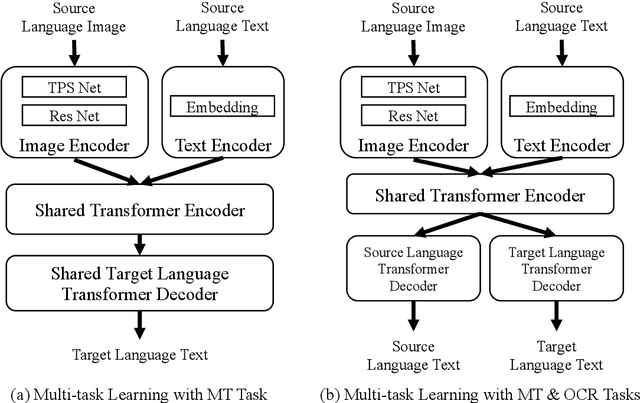
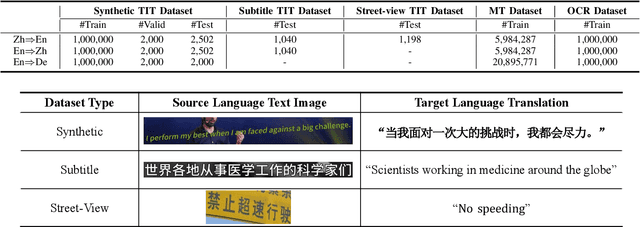
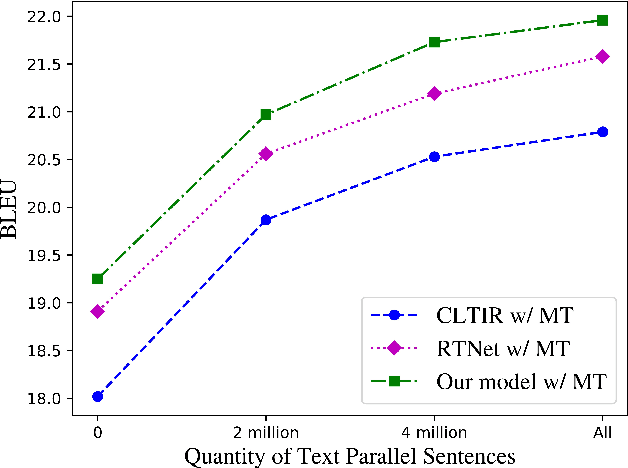
End-to-end text image translation (TIT), which aims at translating the source language embedded in images to the target language, has attracted intensive attention in recent research. However, data sparsity limits the performance of end-to-end text image translation. Multi-task learning is a non-trivial way to alleviate this problem via exploring knowledge from complementary related tasks. In this paper, we propose a novel text translation enhanced text image translation, which trains the end-to-end model with text translation as an auxiliary task. By sharing model parameters and multi-task training, our model is able to take full advantage of easily-available large-scale text parallel corpus. Extensive experimental results show our proposed method outperforms existing end-to-end methods, and the joint multi-task learning with both text translation and recognition tasks achieves better results, proving translation and recognition auxiliary tasks are complementary.
$O(T^{-1})$ Convergence of Optimistic-Follow-the-Regularized-Leader in Two-Player Zero-Sum Markov Games
Sep 26, 2022We prove that optimistic-follow-the-regularized-leader (OFTRL), together with smooth value updates, finds an $O(T^{-1})$-approximate Nash equilibrium in $T$ iterations for two-player zero-sum Markov games with full information. This improves the $\tilde{O}(T^{-5/6})$ convergence rate recently shown in the paper Zhang et al (2022). The refined analysis hinges on two essential ingredients. First, the sum of the regrets of the two players, though not necessarily non-negative as in normal-form games, is approximately non-negative in Markov games. This property allows us to bound the second-order path lengths of the learning dynamics. Second, we prove a tighter algebraic inequality regarding the weights deployed by OFTRL that shaves an extra $\log T$ factor. This crucial improvement enables the inductive analysis that leads to the final $O(T^{-1})$ rate.
Fast and Provable Tensor Robust Principal Component Analysis via Scaled Gradient Descent
Jun 18, 2022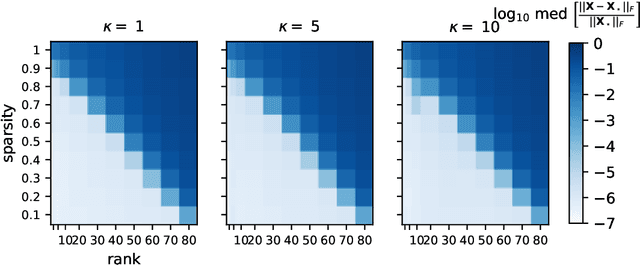
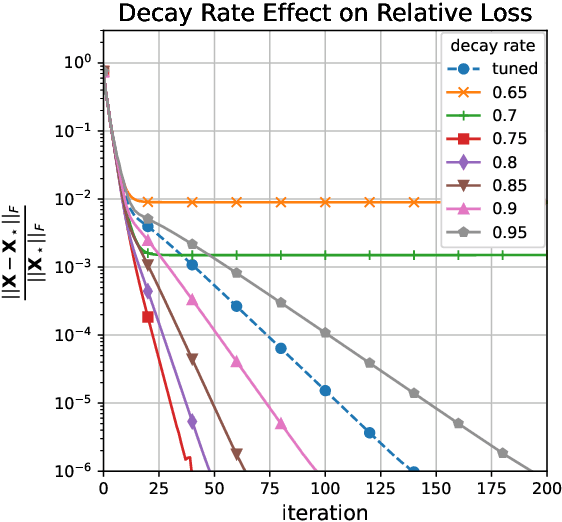


An increasing number of data science and machine learning problems rely on computation with tensors, which better capture the multi-way relationships and interactions of data than matrices. When tapping into this critical advantage, a key challenge is to develop computationally efficient and provably correct algorithms for extracting useful information from tensor data that are simultaneously robust to corruptions and ill-conditioning. This paper tackles tensor robust principal component analysis (RPCA), which aims to recover a low-rank tensor from its observations contaminated by sparse corruptions, under the Tucker decomposition. To minimize the computation and memory footprints, we propose to directly recover the low-dimensional tensor factors -- starting from a tailored spectral initialization -- via scaled gradient descent (ScaledGD), coupled with an iteration-varying thresholding operation to adaptively remove the impact of corruptions. Theoretically, we establish that the proposed algorithm converges linearly to the true low-rank tensor at a constant rate that is independent with its condition number, as long as the level of corruptions is not too large. Empirically, we demonstrate that the proposed algorithm achieves better and more scalable performance than state-of-the-art matrix and tensor RPCA algorithms through synthetic experiments and real-world applications.
Pessimism for Offline Linear Contextual Bandits using $\ell_p$ Confidence Sets
May 21, 2022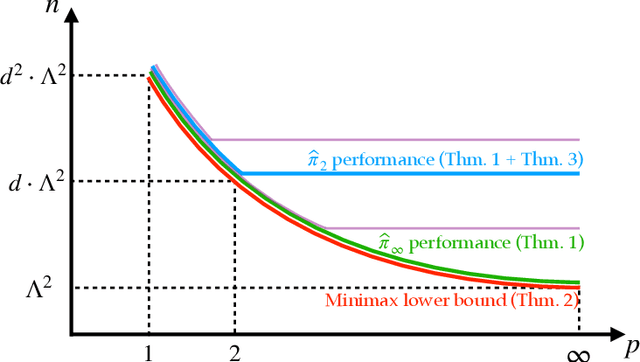
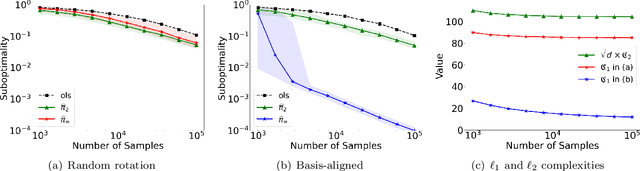
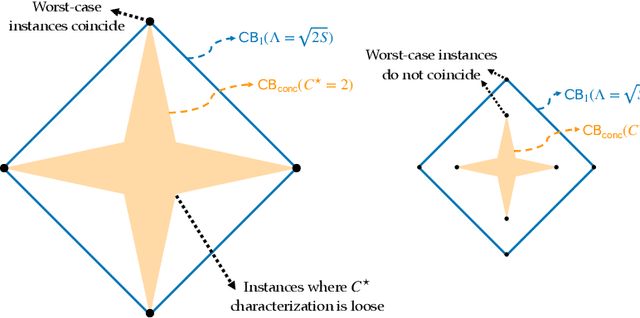
We present a family $\{\hat{\pi}\}_{p\ge 1}$ of pessimistic learning rules for offline learning of linear contextual bandits, relying on confidence sets with respect to different $\ell_p$ norms, where $\hat{\pi}_2$ corresponds to Bellman-consistent pessimism (BCP), while $\hat{\pi}_\infty$ is a novel generalization of lower confidence bound (LCB) to the linear setting. We show that the novel $\hat{\pi}_\infty$ learning rule is, in a sense, adaptively optimal, as it achieves the minimax performance (up to log factors) against all $\ell_q$-constrained problems, and as such it strictly dominates all other predictors in the family, including $\hat{\pi}_2$.
Optimally tackling covariate shift in RKHS-based nonparametric regression
May 06, 2022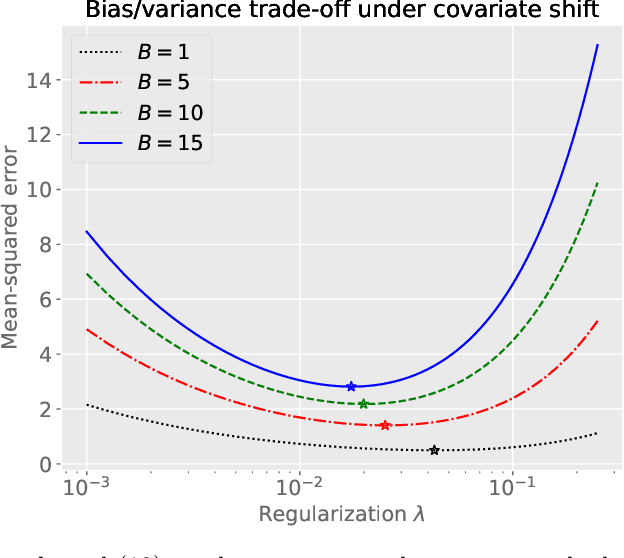
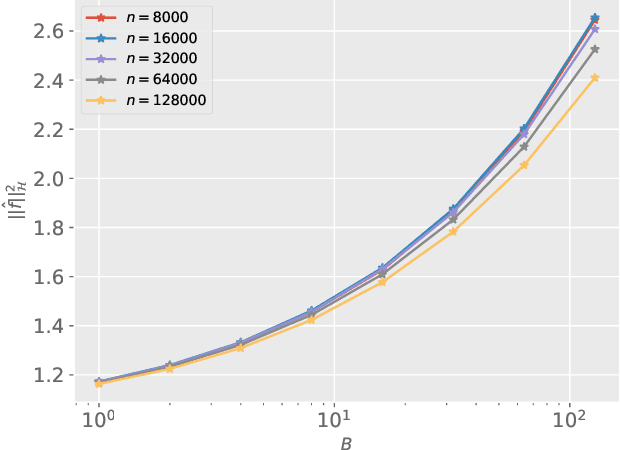
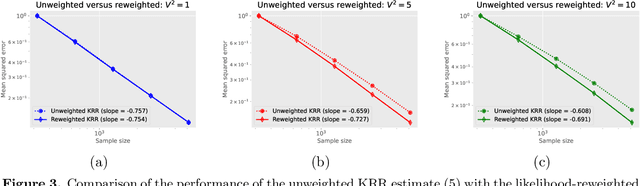
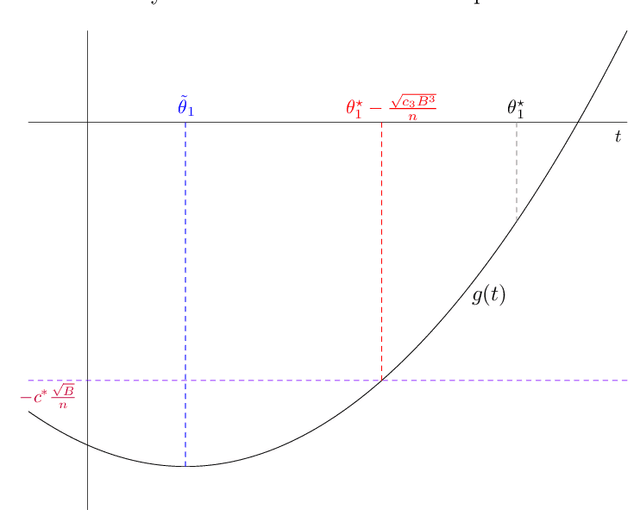
We study the covariate shift problem in the context of nonparametric regression over a reproducing kernel Hilbert space (RKHS). We focus on two natural families of covariate shift problems defined using the likelihood ratios between the source and target distributions. When the likelihood ratios are uniformly bounded, we prove that the kernel ridge regression (KRR) estimator with a carefully chosen regularization parameter is minimax rate-optimal (up to a log factor) for a large family of RKHSs with regular kernel eigenvalues. Interestingly, KRR does not require full knowledge of the likelihood ratio apart from an upper bound on it. In striking contrast to the standard statistical setting without covariate shift, we also demonstrate that a na\"\i ve estimator, which minimizes the empirical risk over the function class, is strictly suboptimal under covariate shift as compared to KRR. We then address the larger class of covariate shift problems where likelihood ratio is possibly unbounded yet has a finite second moment. Here, we show via careful simulations that KRR fails to attain the optimal rate. Instead, we propose a reweighted KRR estimator that weights samples based on a careful truncation of the likelihood ratios. Again, we are able to show that this estimator is minimax optimal, up to logarithmic factors.
Jump-Start Reinforcement Learning
Apr 05, 2022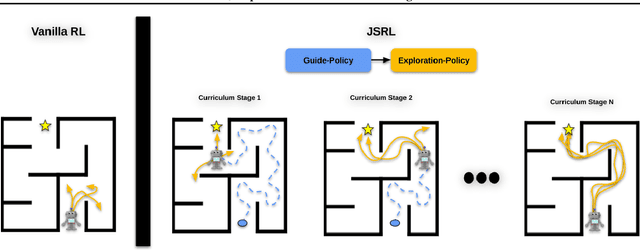
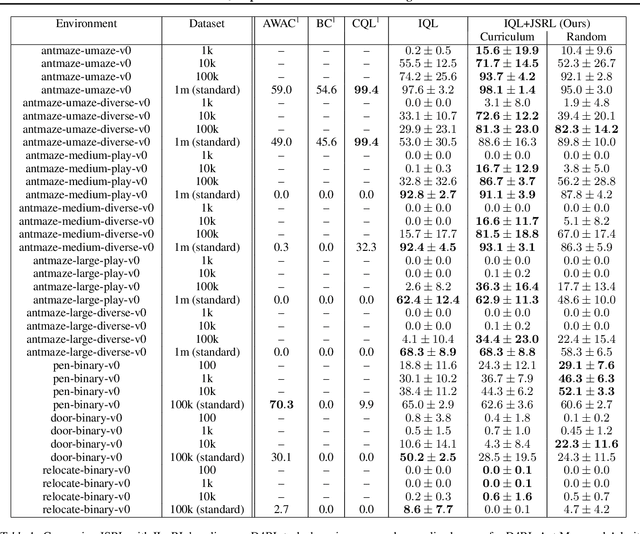
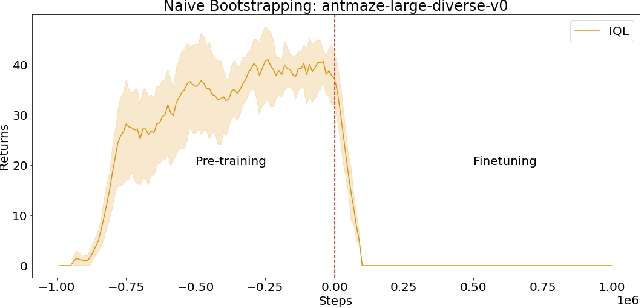
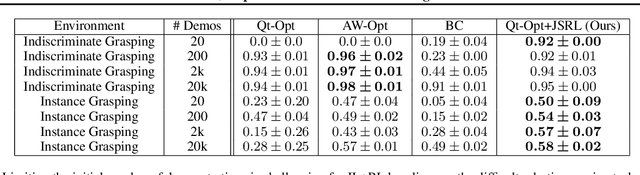
Reinforcement learning (RL) provides a theoretical framework for continuously improving an agent's behavior via trial and error. However, efficiently learning policies from scratch can be very difficult, particularly for tasks with exploration challenges. In such settings, it might be desirable to initialize RL with an existing policy, offline data, or demonstrations. However, naively performing such initialization in RL often works poorly, especially for value-based methods. In this paper, we present a meta algorithm that can use offline data, demonstrations, or a pre-existing policy to initialize an RL policy, and is compatible with any RL approach. In particular, we propose Jump-Start Reinforcement Learning (JSRL), an algorithm that employs two policies to solve tasks: a guide-policy, and an exploration-policy. By using the guide-policy to form a curriculum of starting states for the exploration-policy, we are able to efficiently improve performance on a set of simulated robotic tasks. We show via experiments that JSRL is able to significantly outperform existing imitation and reinforcement learning algorithms, particularly in the small-data regime. In addition, we provide an upper bound on the sample complexity of JSRL and show that with the help of a guide-policy, one can improve the sample complexity for non-optimism exploration methods from exponential in horizon to polynomial.