 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCSim: A Large-Scale Controllable Traffic Simulator
Jun 28, 2024



With the rapid development of urban transportation and the continuous advancement in autonomous vehicles, the demand for safely and efficiently testing autonomous driving and traffic optimization algorithms arises, which needs accurate modeling of large-scale urban traffic scenarios. Existing traffic simulation systems encounter two significant limitations. Firstly, they often rely on open-source datasets or manually crafted maps, constraining the scale of simulations. Secondly, vehicle models within these systems tend to be either oversimplified or lack controllability, compromising the authenticity and diversity of the simulations. In this paper, we propose LCSim, a large-scale controllable traffic simulator. LCSim provides map tools for constructing unified high-definition map (HD map) descriptions from open-source datasets including Waymo and Argoverse or publicly available data sources like OpenStreetMap to scale up the simulation scenarios. Also, we integrate diffusion-based traffic simulation into the simulator for realistic and controllable microscopic traffic flow modeling. By leveraging these features, LCSim provides realistic and diverse virtual traffic environments. Code and Demos are available at https://github.com/tsinghua-fib-lab/LCSim.
Random pairing MLE for estimation of item parameters in Rasch model
Jun 20, 2024



The Rasch model, a classical model in the item response theory, is widely used in psychometrics to model the relationship between individuals' latent traits and their binary responses on assessments or questionnaires. In this paper, we introduce a new likelihood-based estimator -- random pairing maximum likelihood estimator ($\mathsf{RP\text{-}MLE}$) and its bootstrapped variant multiple random pairing MLE ($\mathsf{MRP\text{-}MLE}$) that faithfully estimate the item parameters in the Rasch model. The new estimators have several appealing features compared to existing ones. First, both work for sparse observations, an increasingly important scenario in the big data era. Second, both estimators are provably minimax optimal in terms of finite sample $\ell_{\infty}$ estimation error. Lastly, $\mathsf{RP\text{-}MLE}$ admits precise distributional characterization that allows uncertainty quantification on the item parameters, e.g., construction of confidence intervals of the item parameters. The main idea underlying $\mathsf{RP\text{-}MLE}$ and $\mathsf{MRP\text{-}MLE}$ is to randomly pair user-item responses to form item-item comparisons. This is carefully designed to reduce the problem size while retaining statistical independence. We also provide empirical evidence of the efficacy of the two new estimators using both simulated and real data.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024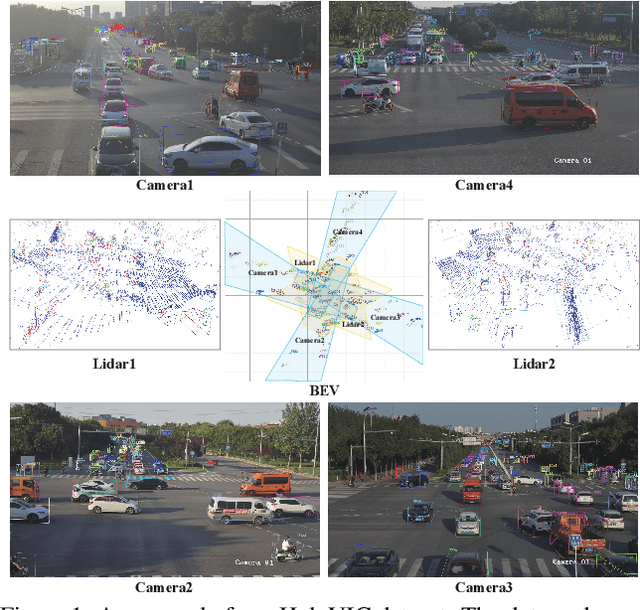
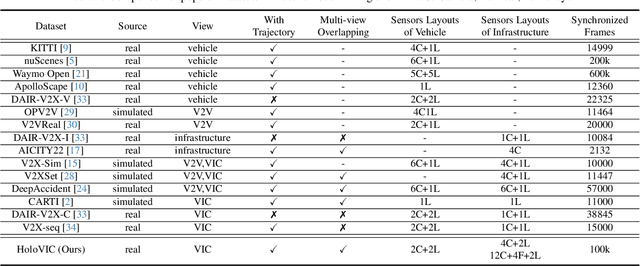
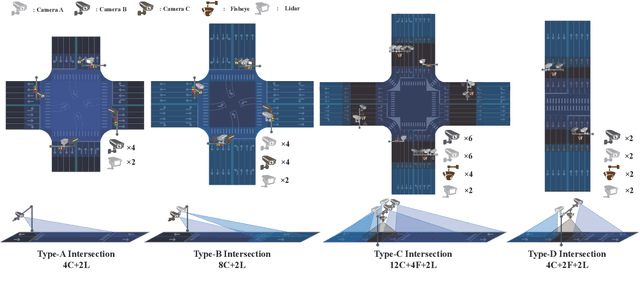
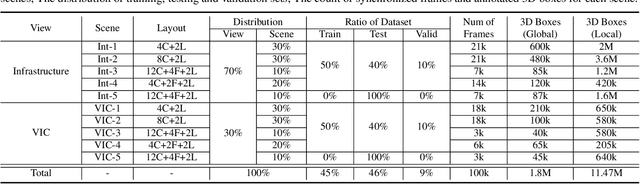
Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
Batched Nonparametric Contextual Bandits
Feb 27, 2024



We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose Batched Successive Elimination with Dynamic Binning (BaSEDB) that achieves optimal regret (up to logarithmic factors). In essence, BaSEDB dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. We also show the suboptimality of static binning under batch constraints, highlighting the necessity of dynamic binning. Additionally, our results suggest that a nearly constant number of policy updates can attain optimal regret in the fully online setting.
Top-$K$ ranking with a monotone adversary
Feb 12, 2024


In this paper, we address the top-$K$ ranking problem with a monotone adversary. We consider the scenario where a comparison graph is randomly generated and the adversary is allowed to add arbitrary edges. The statistician's goal is then to accurately identify the top-$K$ preferred items based on pairwise comparisons derived from this semi-random comparison graph. The main contribution of this paper is to develop a weighted maximum likelihood estimator (MLE) that achieves near-optimal sample complexity, up to a $\log^2(n)$ factor, where n denotes the number of items under comparison. This is made possible through a combination of analytical and algorithmic innovations. On the analytical front, we provide a refined $\ell_\infty$ error analysis of the weighted MLE that is more explicit and tighter than existing analyses. It relates the $\ell_\infty$ error with the spectral properties of the weighted comparison graph. Motivated by this, our algorithmic innovation involves the development of an SDP-based approach to reweight the semi-random graph and meet specified spectral properties. Additionally, we propose a first-order method based on the Matrix Multiplicative Weight Update (MMWU) framework. This method efficiently solves the resulting SDP in nearly-linear time relative to the size of the semi-random comparison graph.
On the design-dependent suboptimality of the Lasso
Feb 01, 2024This paper investigates the effect of the design matrix on the ability (or inability) to estimate a sparse parameter in linear regression. More specifically, we characterize the optimal rate of estimation when the smallest singular value of the design matrix is bounded away from zero. In addition to this information-theoretic result, we provide and analyze a procedure which is simultaneously statistically optimal and computationally efficient, based on soft thresholding the ordinary least squares estimator. Most surprisingly, we show that the Lasso estimator -- despite its widespread adoption for sparse linear regression -- is provably minimax rate-suboptimal when the minimum singular value is small. We present a family of design matrices and sparse parameters for which we can guarantee that the Lasso with any choice of regularization parameter -- including those which are data-dependent and randomized -- would fail in the sense that its estimation rate is suboptimal by polynomial factors in the sample size. Our lower bound is strong enough to preclude the statistical optimality of all forms of the Lasso, including its highly popular penalized, norm-constrained, and cross-validated variants.
Maximum Likelihood Estimation is All You Need for Well-Specified Covariate Shift
Nov 27, 2023A key challenge of modern machine learning systems is to achieve Out-of-Distribution (OOD) generalization -- generalizing to target data whose distribution differs from that of source data. Despite its significant importance, the fundamental question of ``what are the most effective algorithms for OOD generalization'' remains open even under the standard setting of covariate shift. This paper addresses this fundamental question by proving that, surprisingly, classical Maximum Likelihood Estimation (MLE) purely using source data (without any modification) achieves the minimax optimality for covariate shift under the well-specified setting. That is, no algorithm performs better than MLE in this setting (up to a constant factor), justifying MLE is all you need. Our result holds for a very rich class of parametric models, and does not require any boundedness condition on the density ratio. We illustrate the wide applicability of our framework by instantiating it to three concrete examples -- linear regression, logistic regression, and phase retrieval. This paper further complement the study by proving that, under the misspecified setting, MLE is no longer the optimal choice, whereas Maximum Weighted Likelihood Estimator (MWLE) emerges as minimax optimal in certain scenarios.
Provably Accelerating Ill-Conditioned Low-rank Estimation via Scaled Gradient Descent, Even with Overparameterization
Oct 09, 2023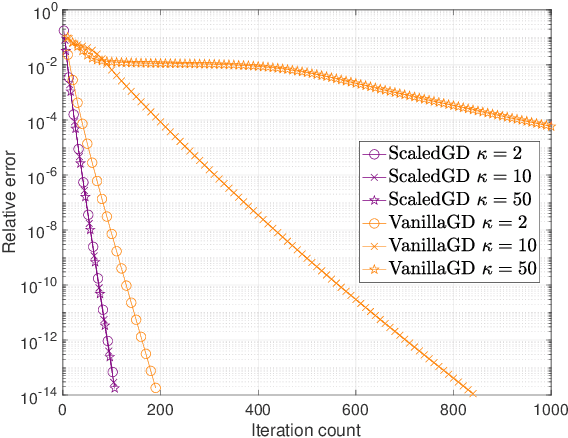
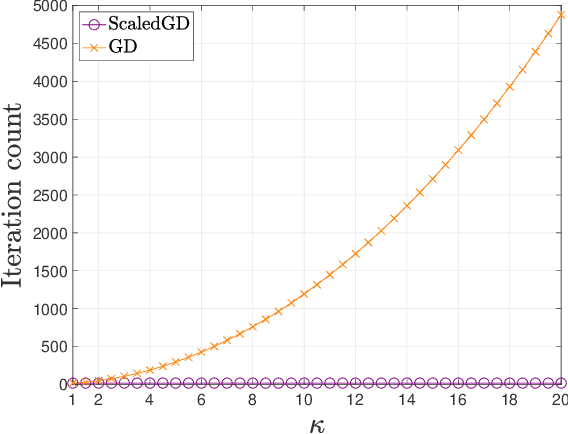
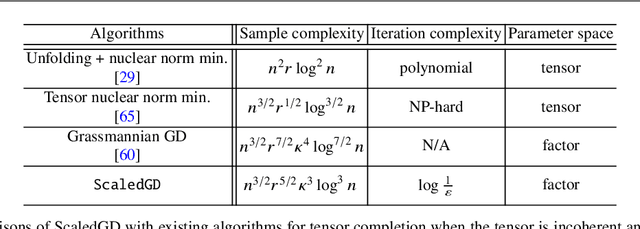
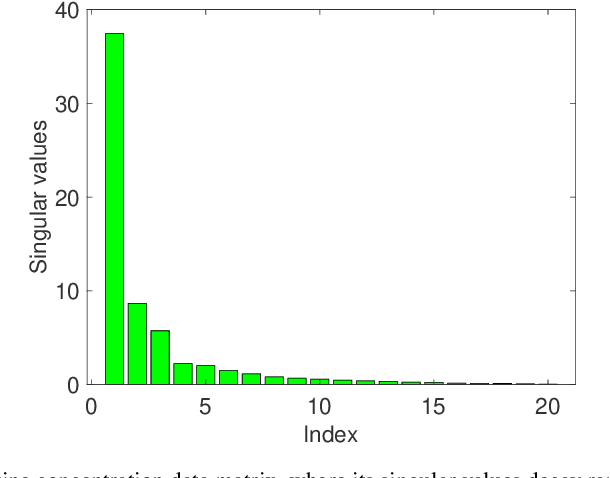
Many problems encountered in science and engineering can be formulated as estimating a low-rank object (e.g., matrices and tensors) from incomplete, and possibly corrupted, linear measurements. Through the lens of matrix and tensor factorization, one of the most popular approaches is to employ simple iterative algorithms such as gradient descent (GD) to recover the low-rank factors directly, which allow for small memory and computation footprints. However, the convergence rate of GD depends linearly, and sometimes even quadratically, on the condition number of the low-rank object, and therefore, GD slows down painstakingly when the problem is ill-conditioned. This chapter introduces a new algorithmic approach, dubbed scaled gradient descent (ScaledGD), that provably converges linearly at a constant rate independent of the condition number of the low-rank object, while maintaining the low per-iteration cost of gradient descent for a variety of tasks including sensing, robust principal component analysis and completion. In addition, ScaledGD continues to admit fast global convergence to the minimax-optimal solution, again almost independent of the condition number, from a small random initialization when the rank is over-specified in the presence of Gaussian noise. In total, ScaledGD highlights the power of appropriate preconditioning in accelerating nonconvex statistical estimation, where the iteration-varying preconditioners promote desirable invariance properties of the trajectory with respect to the symmetry in low-rank factorization without hurting generalization.
Unraveling Projection Heads in Contrastive Learning: Insights from Expansion and Shrinkage
Jun 06, 2023



We investigate the role of projection heads, also known as projectors, within the encoder-projector framework (e.g., SimCLR) used in contrastive learning. We aim to demystify the observed phenomenon where representations learned before projectors outperform those learned after -- measured using the downstream linear classification accuracy, even when the projectors themselves are linear. In this paper, we make two significant contributions towards this aim. Firstly, through empirical and theoretical analysis, we identify two crucial effects -- expansion and shrinkage -- induced by the contrastive loss on the projectors. In essence, contrastive loss either expands or shrinks the signal direction in the representations learned by an encoder, depending on factors such as the augmentation strength, the temperature used in contrastive loss, etc. Secondly, drawing inspiration from the expansion and shrinkage phenomenon, we propose a family of linear transformations to accurately model the projector's behavior. This enables us to precisely characterize the downstream linear classification accuracy in the high-dimensional asymptotic limit. Our findings reveal that linear projectors operating in the shrinkage (or expansion) regime hinder (or improve) the downstream classification accuracy. This provides the first theoretical explanation as to why (linear) projectors impact the downstream performance of learned representations. Our theoretical findings are further corroborated by extensive experiments on both synthetic data and real image data.
Sharp high-probability sample complexities for policy evaluation with linear function approximation
May 30, 2023This paper is concerned with the problem of policy evaluation with linear function approximation in discounted infinite horizon Markov decision processes. We investigate the sample complexities required to guarantee a predefined estimation error of the best linear coefficients for two widely-used policy evaluation algorithms: the temporal difference (TD) learning algorithm and the two-timescale linear TD with gradient correction (TDC) algorithm. In both the on-policy setting, where observations are generated from the target policy, and the off-policy setting, where samples are drawn from a behavior policy potentially different from the target policy, we establish the first sample complexity bound with high-probability convergence guarantee that attains the optimal dependence on the tolerance level. We also exhihit an explicit dependence on problem-related quantities, and show in the on-policy setting that our upper bound matches the minimax lower bound on crucial problem parameters, including the choice of the feature maps and the problem dimension.