 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLoRA: Task-aware Low Rank Adaptation of Large Language Models
Apr 20, 2026Low-Rank Adaptation (LoRA) has become a widely adopted parameter-efficient fine-tuning method for large language models, with its effectiveness largely influenced by the allocation of ranks and scaling factors, as well as initialization. Existing LoRA variants typically address only one of these factors, often at the cost of increased training complexity or reduced practical efficiency. In this work, we present Task-aware Low-Rank Adaptation (TLoRA), a unified framework that jointly optimizes initialization and resource allocation at the outset of training. TLoRA introduces a data-driven initialization strategy that aligns the LoRA $A$ matrix with task-relevant subspaces by performing singular value decomposition on the product of pre-trained weights and input activation covariance. After this, the $A$ matrix is frozen, and only the $B$ matrix is trained. Furthermore, TLoRA employs a sensitivity-based importance metric to adaptively allocate ranks and scaling factors across layers under a fixed parameter budget. We conduct extensive experiments that demonstrate TLoRA consistently performs excellently across various tasks, including natural language understanding, commonsense reasoning, math reasoning, code generation, and chat generation, while significantly reducing the number of trainable parameters.
Mild Over-Parameterization Benefits Asymmetric Tensor PCA
Apr 11, 2026Asymmetric Tensor PCA (ATPCA) is a prototypical model for studying the trade-offs between sample complexity, computation, and memory. Existing algorithms for this problem typically require at least $d^{\left\lceil\overline{k}/2\right\rceil}$ state memory cost to recover the signal, where $d$ is the vector dimension and $\overline{k}$ is the tensor order. We focus on the setting where $\overline{k} \geq 4$ is even and consider (stochastic) gradient descent-based algorithms under a limited memory budget, which permits only mild over-parameterization of the model. We propose a matrix-parameterized method (in $d^{2}$ state memory cost) using a novel three-phase alternating-update algorithm to address the problem and demonstrate how mild over-parameterization facilitates learning in two key aspects: (i) it improves sample efficiency, allowing our method to achieve \emph{near-optimal} $d^{\overline{k}-2}$ sample complexity in our limited memory setting; and (ii) it enhances adaptivity to problem structure, a previously unrecognized phenomenon, where the required sample size naturally decreases as consecutive vectors become more aligned, and in the symmetric limit attains $d^{\overline{k}/2}$, matching the \emph{best} known polynomial-time complexity. To our knowledge, this is the \emph{first} tractable algorithm for ATPCA with $d^{\overline{k}}$-independent memory costs.
Feature Projection Learning for Better Vision-Language Reasoning
Jan 28, 2026Vision-Language Pre-Trained models, notably CLIP, that utilize contrastive learning have proven highly adept at extracting generalizable visual features. To inherit the well-learned knowledge of VLP models for downstream tasks, several approaches aim to adapt them efficiently with limited supervision. However, these methods either suffer from limited performance, excessive learnable parameters, or extended training times, all of which hinder their effectiveness in adapting the CLIP model to downstream tasks. In this work, we propose a simple yet efficient and effective method called \textit{\textbf{F}eature \textbf{P}rojection \textbf{L}earning(FPL)} to address these problems. Specifically, we develop a projection model that projects class prototype features into the query image feature space and reconstructs the query image feature map. The negative average squared reconstruction error is used as the class score. In this way, we transform the classification problem into a feature projection problem. The final output of this method is a combination of the prediction from the projection model and the original pre-trained CLIP. Comprehensive empirical evaluations confirm that FPL delivers superior accuracy, surpassing the current state-of-the-art methods by a substantial margin.
Learning Curves of Stochastic Gradient Descent in Kernel Regression
May 28, 2025

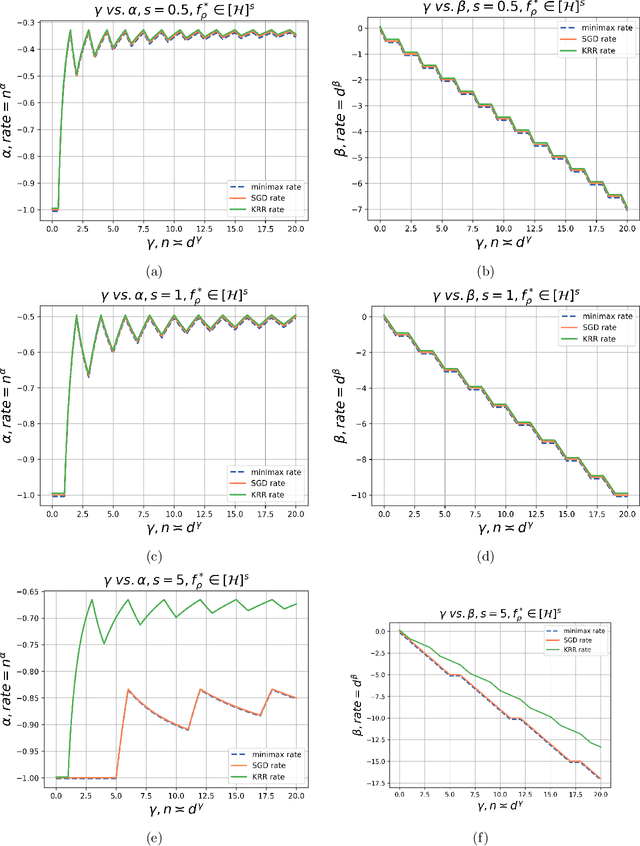
This paper considers a canonical problem in kernel regression: how good are the model performances when it is trained by the popular online first-order algorithms, compared to the offline ones, such as ridge and ridgeless regression? In this paper, we analyze the foundational single-pass Stochastic Gradient Descent (SGD) in kernel regression under source condition where the optimal predictor can even not belong to the RKHS, i.e. the model is misspecified. Specifically, we focus on the inner product kernel over the sphere and characterize the exact orders of the excess risk curves under different scales of sample sizes $n$ concerning the input dimension $d$. Surprisingly, we show that SGD achieves min-max optimal rates up to constants among all the scales, without suffering the saturation, a prevalent phenomenon observed in (ridge) regression, except when the model is highly misspecified and the learning is in a final stage where $n\gg d^{\gamma}$ with any constant $\gamma >0$. The main reason for SGD to overcome the curse of saturation is the exponentially decaying step size schedule, a common practice in deep neural network training. As a byproduct, we provide the \emph{first} provable advantage of the scheme over the iterative averaging method in the common setting.