 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACRONYM: A Large-Scale Grasp Dataset Based on Simulation
Nov 18, 2020
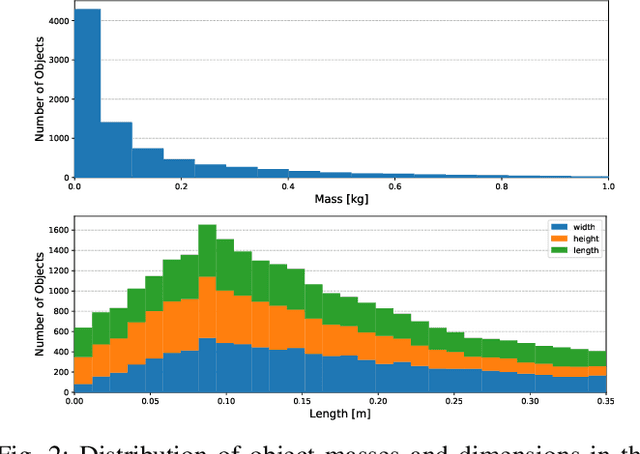

We introduce ACRONYM, a dataset for robot grasp planning based on physics simulation. The dataset contains 17.7M parallel-jaw grasps, spanning 8872 objects from 262 different categories, each labeled with the grasp result obtained from a physics simulator. We show the value of this large and diverse dataset by using it to train two state-of-the-art learning-based grasp planning algorithms. Grasp performance improves significantly when compared to the original smaller dataset. Data and tools can be accessed at https://sites.google.com/nvidia.com/graspdataset.
A Billion Ways to Grasp: An Evaluation of Grasp Sampling Schemes on a Dense, Physics-based Grasp Data Set
Dec 11, 2019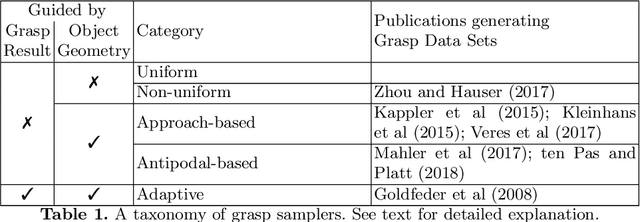
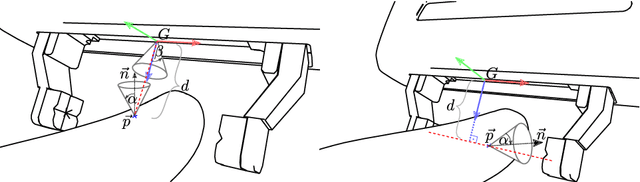


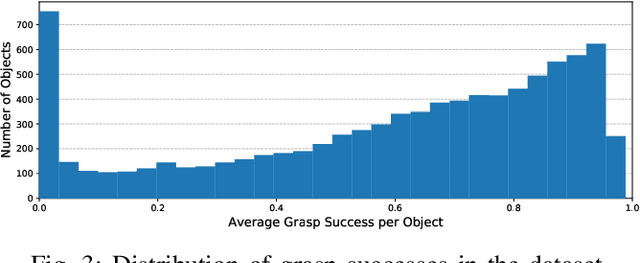
Robot grasping is often formulated as a learning problem. With the increasing speed and quality of physics simulations, generating large-scale grasping data sets that feed learning algorithms is becoming more and more popular. An often overlooked question is how to generate the grasps that make up these data sets. In this paper, we review, classify, and compare different grasp sampling strategies. Our evaluation is based on a fine-grained discretization of SE(3) and uses physics-based simulation to evaluate the quality and robustness of the corresponding parallel-jaw grasps. Specifically, we consider more than 1 billion grasps for each of the 21 objects from the YCB data set. This dense data set lets us evaluate existing sampling schemes w.r.t. their bias and efficiency. Our experiments show that some popular sampling schemes contain significant bias and do not cover all possible ways an object can be grasped.
6-DOF Grasping for Target-driven Object Manipulation in Clutter
Dec 08, 2019

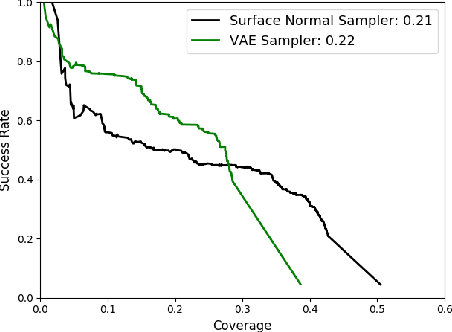
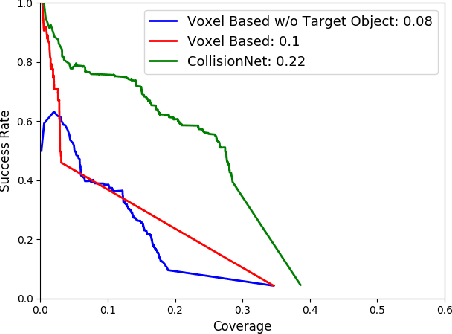
Grasping in cluttered environments is a fundamental but challenging robotic skill. It requires both reasoning about unseen object parts and potential collisions with the manipulator. Most existing data-driven approaches avoid this problem by limiting themselves to top-down planar grasps which is insufficient for many real-world scenarios and greatly limits possible grasps. We present a method that plans 6-DOF grasps for any desired object in a cluttered scene from partial point cloud observations. Our method achieves a grasp success of 80.3%, outperforming baseline approaches by 17.6% and clearing 9 cluttered table scenes (which contain 23 unknown objects and 51 picks in total) on a real robotic platform. By using our learned collision checking module, we can even reason about effective grasp sequences to retrieve objects that are not immediately accessible. Supplementary video can be found at https://youtu.be/w0B5S-gCsJk.
Self-supervised 6D Object Pose Estimation for Robot Manipulation
Sep 23, 2019
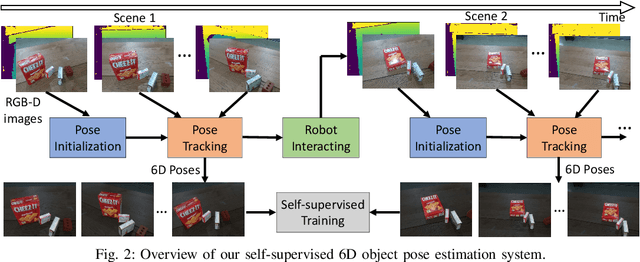
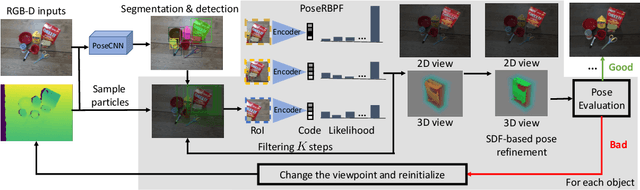
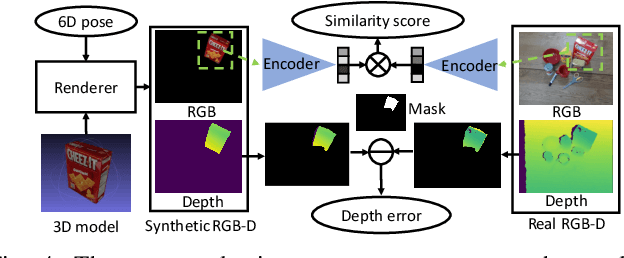
To teach robots skills, it is crucial to obtain data with supervision. Since annotating real world data is time-consuming and expensive, enabling robots to learn in a self-supervised way is important. In this work, we introduce a robot system for self-supervised 6D object pose estimation. Starting from modules trained in simulation, our system is able to label real world images with accurate 6D object poses for self-supervised learning. In addition, the robot interacts with objects in the environment to change the object configuration by grasping or pushing objects. In this way, our system is able to continuously collect data and improve its pose estimation modules. We show that the self-supervised learning improves object segmentation and 6D pose estimation performance, and consequently enables the system to grasp objects more reliably. A video showing the experiments can be found at https://youtu.be/W1Y0Mmh1Gd8.
Representing Robot Task Plans as Robust Logical-Dynamical Systems
Aug 05, 2019
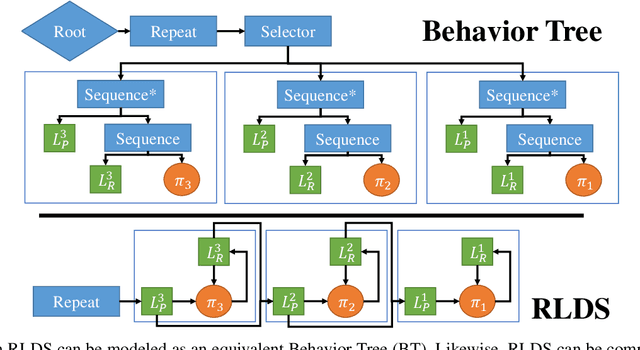


It is difficult to create robust, reusable, and reactive behaviors for robots that can be easily extended and combined. Frameworks such as Behavior Trees are flexible but difficult to characterize, especially when designing reactions and recovery behaviors to consistently converge to a desired goal condition. We propose a framework which we call Robust Logical-Dynamical Systems (RLDS), which combines the advantages of task representations like behavior trees with theoretical guarantees on performance. RLDS can also be constructed automatically from simple sequential task plans and will still achieve robust, reactive behavior in dynamic real-world environments. In this work, we describe both our proposed framework and a case study on a simple household manipulation task, with examples for how specific pieces can be implemented to achieve robust behavior. Finally, we show how in the context of these manipulation tasks, a combination of an RLDS with planning can achieve better results under adversarial conditions.
6-DOF GraspNet: Variational Grasp Generation for Object Manipulation
May 25, 2019
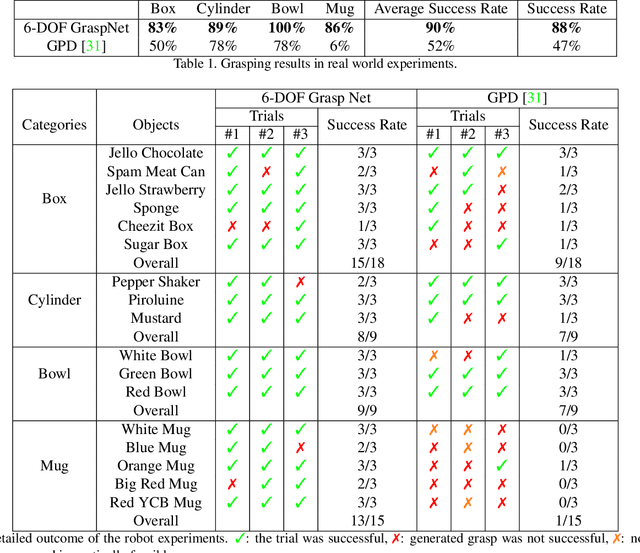

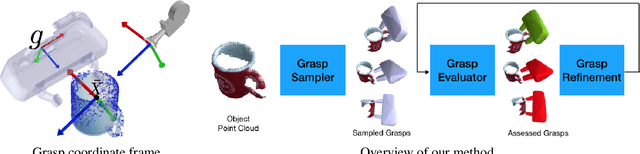
Generating grasp poses is a crucial component for any robot object manipulation task. In this work, we formulate the problem of grasp generation as sampling a set of grasps using a variational auto-encoder and assess and refine the sampled grasps using a grasp evaluator model. Both Grasp Sampler and Grasp Refinement networks take 3D point clouds observed by a depth camera as input. We evaluate our approach in simulation and real-world robot experiments. Our approach achieves 88\% success rate on various commonly used objects with diverse appearances, scales, and weights. Our model is trained purely in simulation and works in the real world without any extra steps. The video of our experiments can be found at: https://youtu.be/KNnDpGEE_NE
The RBO Dataset of Articulated Objects and Interactions
Jun 17, 2018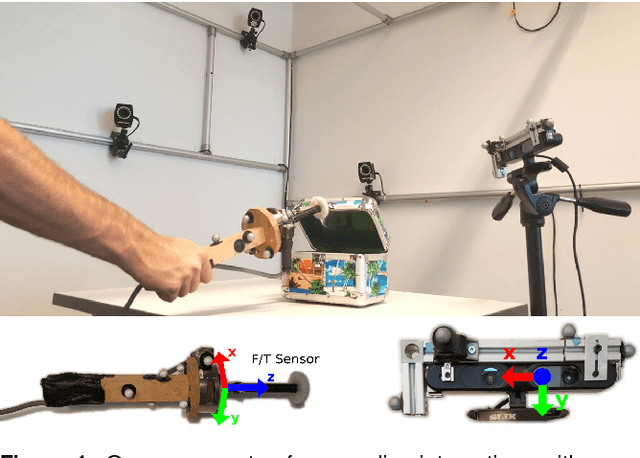
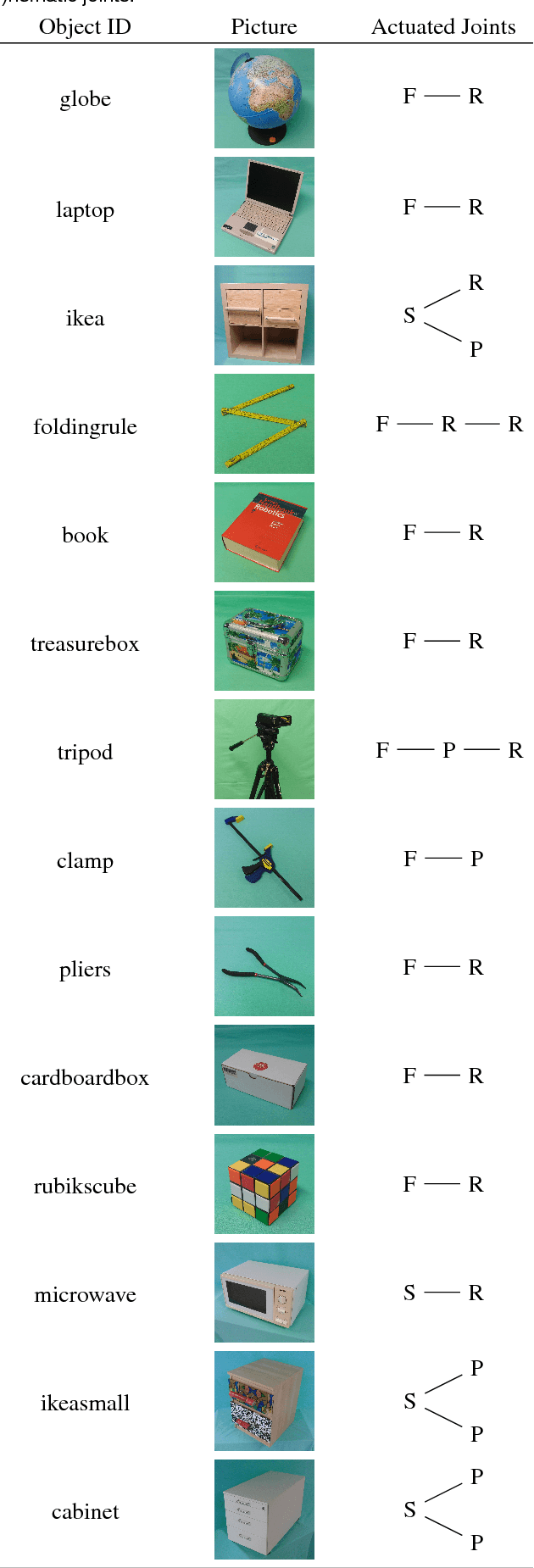
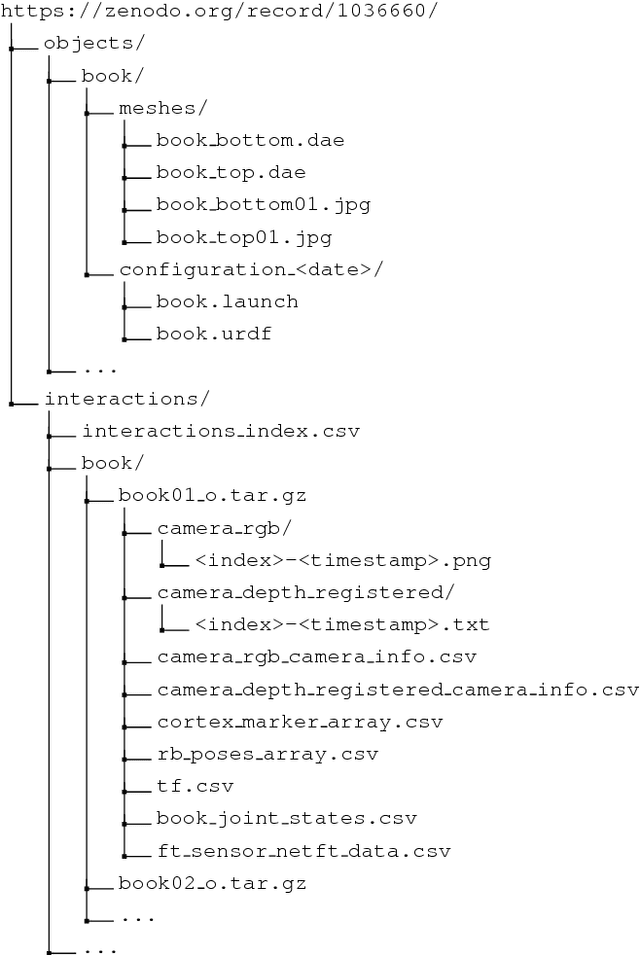
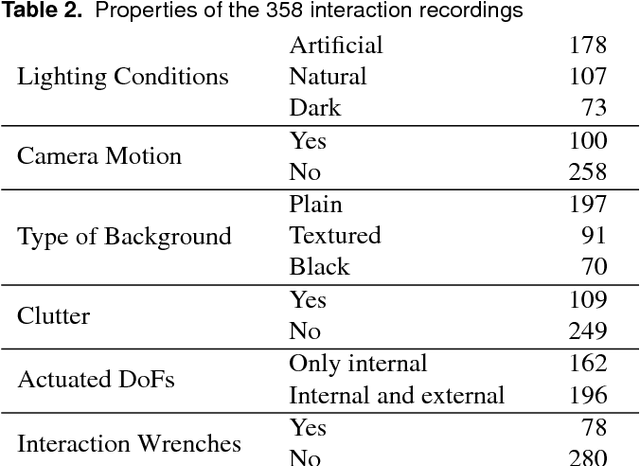
We present a dataset with models of 14 articulated objects commonly found in human environments and with RGB-D video sequences and wrenches recorded of human interactions with them. The 358 interaction sequences total 67 minutes of human manipulation under varying experimental conditions (type of interaction, lighting, perspective, and background). Each interaction with an object is annotated with the ground truth poses of its rigid parts and the kinematic state obtained by a motion capture system. For a subset of 78 sequences (25 minutes), we also measured the interaction wrenches. The object models contain textured three-dimensional triangle meshes of each link and their motion constraints. We provide Python scripts to download and visualize the data. The data is available at https://tu-rbo.github.io/articulated-objects/ and hosted at https://zenodo.org/record/1036660/.
Learning Dexterous Manipulation for a Soft Robotic Hand from Human Demonstration
Mar 20, 2017


Dexterous multi-fingered hands can accomplish fine manipulation behaviors that are infeasible with simple robotic grippers. However, sophisticated multi-fingered hands are often expensive and fragile. Low-cost soft hands offer an appealing alternative to more conventional devices, but present considerable challenges in sensing and actuation, making them difficult to apply to more complex manipulation tasks. In this paper, we describe an approach to learning from demonstration that can be used to train soft robotic hands to perform dexterous manipulation tasks. Our method uses object-centric demonstrations, where a human demonstrates the desired motion of manipulated objects with their own hands, and the robot autonomously learns to imitate these demonstrations using reinforcement learning. We propose a novel algorithm that allows us to blend and select a subset of the most feasible demonstrations to learn to imitate on the hardware, which we use with an extension of the guided policy search framework to use multiple demonstrations to learn generalizable neural network policies. We demonstrate our approach on the RBO Hand 2, with learned motor skills for turning a valve, manipulating an abacus, and grasping.