 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Blind Super-Resolution Network for Spatial-Specific and Spatial-Agnostic Degradations
Jun 09, 2025Prior methodologies have disregarded the diversities among distinct degradation types during image reconstruction, employing a uniform network model to handle multiple deteriorations. Nevertheless, we discover that prevalent degradation modalities, including sampling, blurring, and noise, can be roughly categorized into two classes. We classify the first class as spatial-agnostic dominant degradations, less affected by regional changes in image space, such as downsampling and noise degradation. The second class degradation type is intimately associated with the spatial position of the image, such as blurring, and we identify them as spatial-specific dominant degradations. We introduce a dynamic filter network integrating global and local branches to address these two degradation types. This network can greatly alleviate the practical degradation problem. Specifically, the global dynamic filtering layer can perceive the spatial-agnostic dominant degradation in different images by applying weights generated by the attention mechanism to multiple parallel standard convolution kernels, enhancing the network's representation ability. Meanwhile, the local dynamic filtering layer converts feature maps of the image into a spatially specific dynamic filtering operator, which performs spatially specific convolution operations on the image features to handle spatial-specific dominant degradations. By effectively integrating both global and local dynamic filtering operators, our proposed method outperforms state-of-the-art blind super-resolution algorithms in both synthetic and real image datasets.
Incorporating Uncertainty-Guided and Top-k Codebook Matching for Real-World Blind Image Super-Resolution
Jun 09, 2025Recent advancements in codebook-based real image super-resolution (SR) have shown promising results in real-world applications. The core idea involves matching high-quality image features from a codebook based on low-resolution (LR) image features. However, existing methods face two major challenges: inaccurate feature matching with the codebook and poor texture detail reconstruction. To address these issues, we propose a novel Uncertainty-Guided and Top-k Codebook Matching SR (UGTSR) framework, which incorporates three key components: (1) an uncertainty learning mechanism that guides the model to focus on texture-rich regions, (2) a Top-k feature matching strategy that enhances feature matching accuracy by fusing multiple candidate features, and (3) an Align-Attention module that enhances the alignment of information between LR and HR features. Experimental results demonstrate significant improvements in texture realism and reconstruction fidelity compared to existing methods. We will release the code upon formal publication.
Single Image Super-Resolution via a Holistic Attention Network
Aug 20, 2020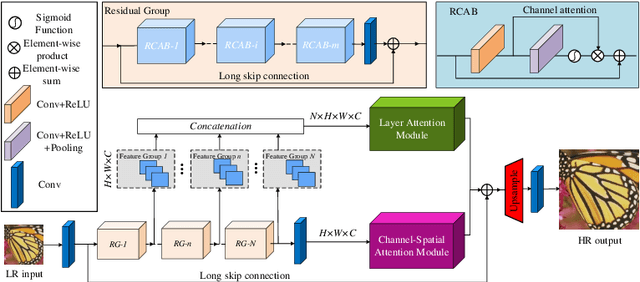

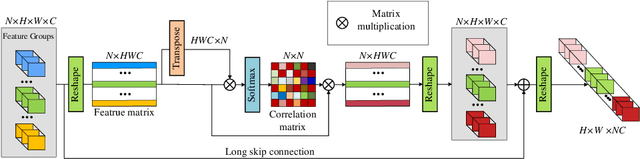

Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.