 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-fine: A RNN-based hierarchical attention model for vehicle re-identification
Dec 11, 2018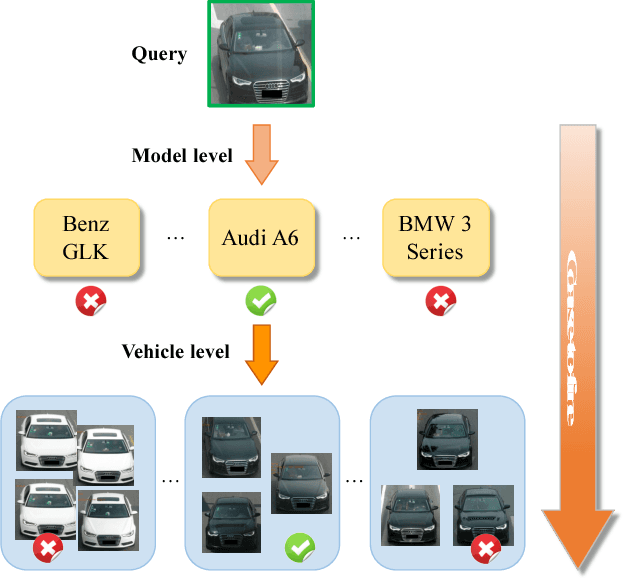

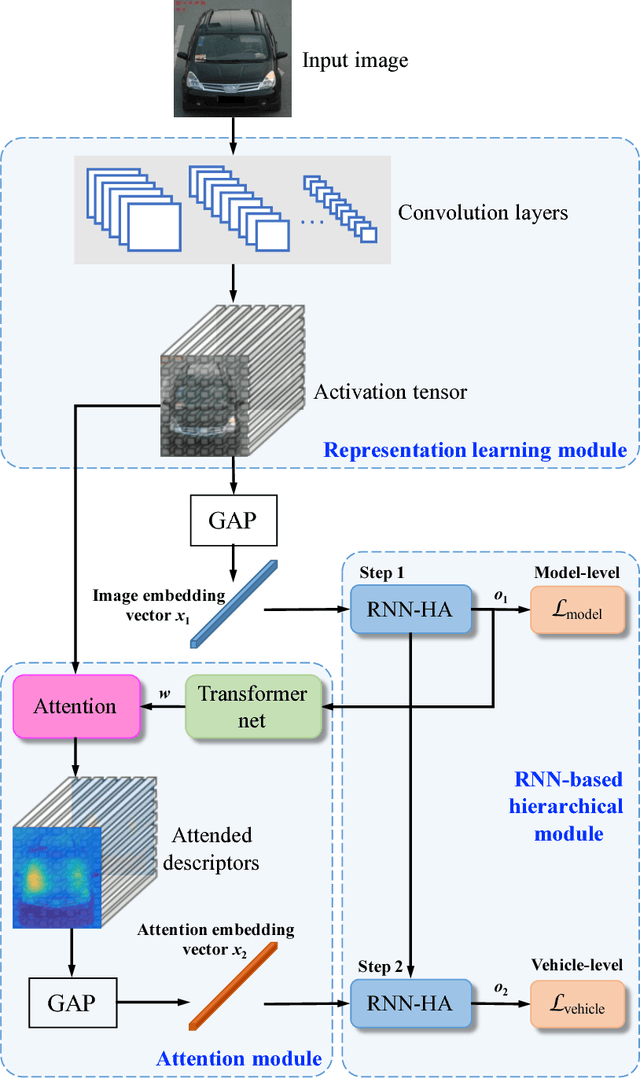
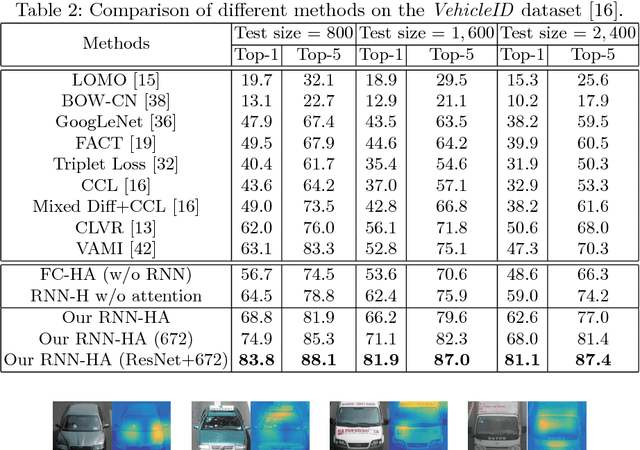
Vehicle re-identification is an important problem and becomes desirable with the rapid expansion of applications in video surveillance and intelligent transportation. By recalling the identification process of human vision, we are aware that there exists a native hierarchical dependency when humans identify different vehicles. Specifically, humans always firstly determine one vehicle's coarse-grained category, i.e., the car model/type. Then, under the branch of the predicted car model/type, they are going to identify specific vehicles by relying on subtle visual cues, e.g., customized paintings and windshield stickers, at the fine-grained level. Inspired by the coarse-to-fine hierarchical process, we propose an end-to-end RNN-based Hierarchical Attention (RNN-HA) classification model for vehicle re-identification. RNN-HA consists of three mutually coupled modules: the first module generates image representations for vehicle images, the second hierarchical module models the aforementioned hierarchical dependent relationship, and the last attention module focuses on capturing the subtle visual information distinguishing specific vehicles from each other. By conducting comprehensive experiments on two vehicle re-identification benchmark datasets VeRi and VehicleID, we demonstrate that the proposed model achieves superior performance over state-of-the-art methods.
Visual Question Answering as Reading Comprehension
Nov 29, 2018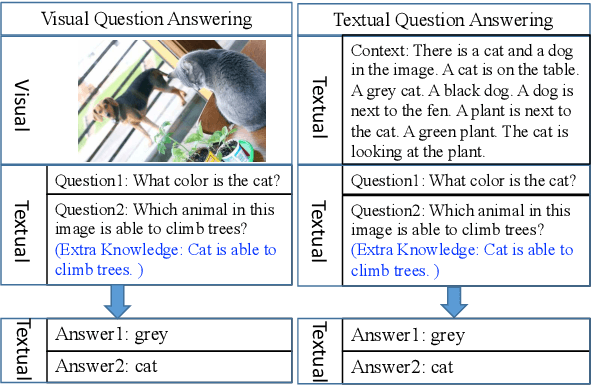
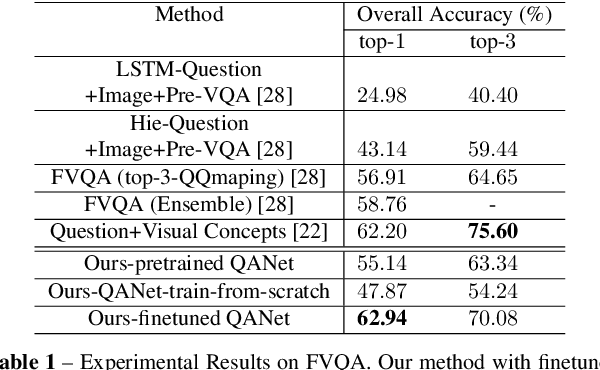
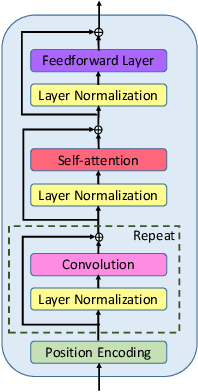
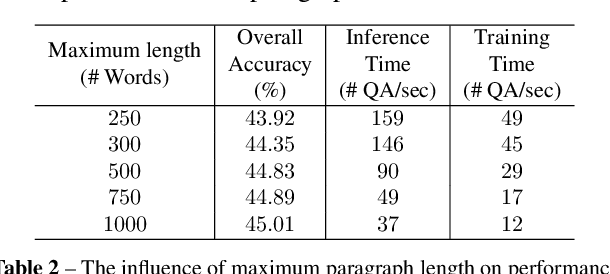
Visual question answering (VQA) demands simultaneous comprehension of both the image visual content and natural language questions. In some cases, the reasoning needs the help of common sense or general knowledge which usually appear in the form of text. Current methods jointly embed both the visual information and the textual feature into the same space. However, how to model the complex interactions between the two different modalities is not an easy task. In contrast to struggling on multimodal feature fusion, in this paper, we propose to unify all the input information by natural language so as to convert VQA into a machine reading comprehension problem. With this transformation, our method not only can tackle VQA datasets that focus on observation based questions, but can also be naturally extended to handle knowledge-based VQA which requires to explore large-scale external knowledge base. It is a step towards being able to exploit large volumes of text and natural language processing techniques to address VQA problem. Two types of models are proposed to deal with open-ended VQA and multiple-choice VQA respectively. We evaluate our models on three VQA benchmarks. The comparable performance with the state-of-the-art demonstrates the effectiveness of the proposed method.
Structured Binary Neural Networks for Accurate Image Classification and Semantic Segmentation
Nov 27, 2018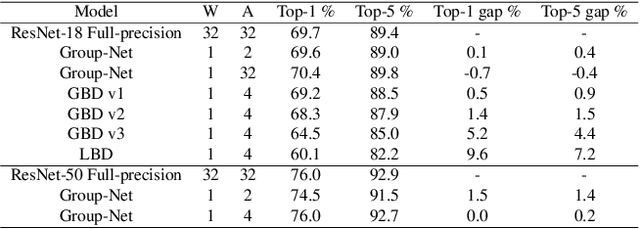
In this paper, we propose to train convolutional neural networks (CNNs) with both binarized weights and activations, leading to quantized models specifically} for mobile devices with limited power capacity and computation resources. Previous works on quantizing CNNs seek to approximate the floating-point information using a set of discrete values, which we call value approximation, but typically assume the same architecture as the full-precision networks. In this paper, however, we take a novel 'structure approximation' view for quantization---it is very likely that a different architecture may be better for best performance. In particular, we propose a `network decomposition' strategy, named \textbf{Group-Net}, in which we divide the network into groups. In this way, each full-precision group can be effectively reconstructed by aggregating a set of homogeneous binary branches. In addition, we learn effective connections among groups to improve the representational capability. Moreover, the proposed Group-Net shows strong generalization to other tasks. For instance, we extend Group-Net for highly accurate semantic segmentation by embedding rich context into the binary structure. Experiments on both classification and semantic segmentation tasks demonstrate the superior performance of the proposed methods over various popular architectures. In particular, we outperform the previous best binary neural networks in terms of accuracy and major computation savings.
RGB-D Based Action Recognition with Light-weight 3D Convolutional Networks
Nov 24, 2018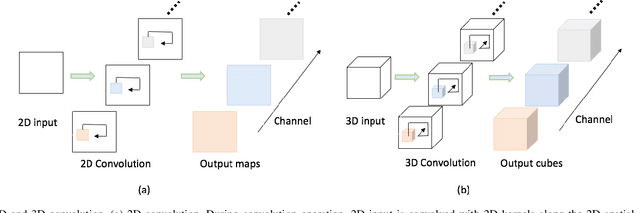
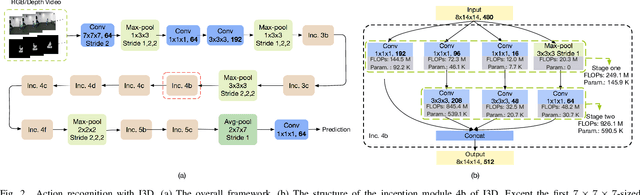
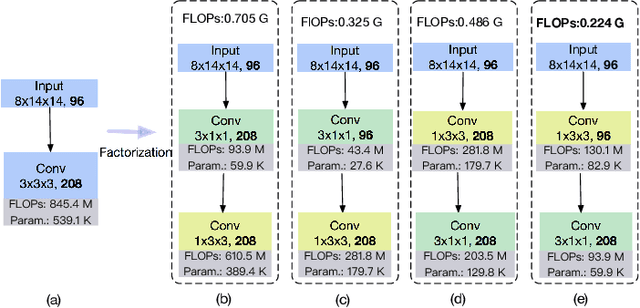
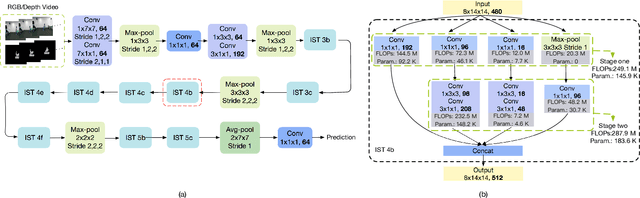
Different from RGB videos, depth data in RGB-D videos provide key complementary information for tristimulus visual data which potentially could achieve accuracy improvement for action recognition. However, most of the existing action recognition models solely using RGB videos limit the performance capacity. Additionally, the state-of-the-art action recognition models, namely 3D convolutional neural networks (3D-CNNs) contain tremendous parameters suffering from computational inefficiency. In this paper, we propose a series of 3D light-weight architectures for action recognition based on RGB-D data. Compared with conventional 3D-CNN models, the proposed light-weight 3D-CNNs have considerably less parameters involving lower computation cost, while it results in favorable recognition performance. Experimental results on two public benchmark datasets show that our models can approximate or outperform the state-of-the-art approaches. Specifically, on the RGB+D-NTU (NTU) dataset, we achieve 93.2% and 97.6% for cross-subject and cross-view measurement, and on the Northwestern-UCLA Multiview Action 3D (N-UCLA) dataset, we achieve 95.5% accuracy of cross-view.
Adversarial Learning of Structure-Aware Fully Convolutional Networks for Landmark Localization
Nov 02, 2018
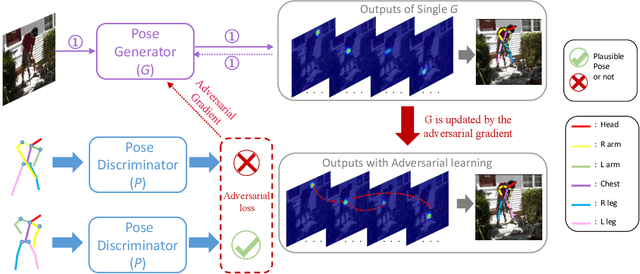
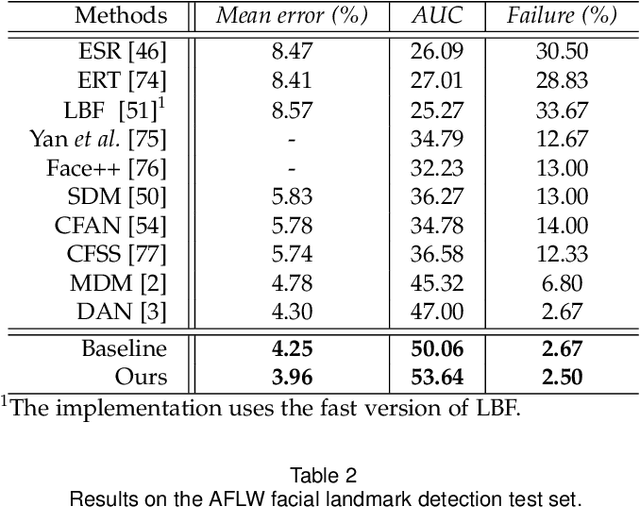
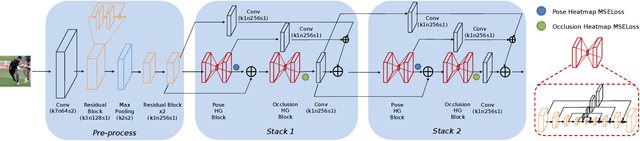
Landmark/pose estimation in single monocular images have received much effort in computer vision due to its important applications. It remains a challenging task when input images severe occlusions caused by, e.g., adverse camera views. Under such circumstances, biologically implausible pose predictions may be produced. In contrast, human vision is able to predict poses by exploiting geometric constraints of landmark point inter-connectivity. To address the problem, by incorporating priors about the structure of pose components, we propose a novel structure-aware fully convolutional network to implicitly take such priors into account during training of the deep network. Explicit learning of such constraints is typically challenging. Instead, inspired by how human identifies implausible poses, we design discriminators to distinguish the real poses from the fake ones (such as biologically implausible ones). If the pose generator G generates results that the discriminator fails to distinguish from real ones, the network successfully learns the priors. Training of the network follows the strategy of conditional Generative Adversarial Networks (GANs). The effectiveness of the proposed network is evaluated on three pose-related tasks: 2D single human pose estimation, 2D facial landmark estimation and 3D single human pose estimation. The proposed approach significantly outperforms the state-of-the-art methods and almost always generates plausible pose predictions, demonstrating the usefulness of implicit learning of structures using GANs.
Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition
Nov 02, 2018
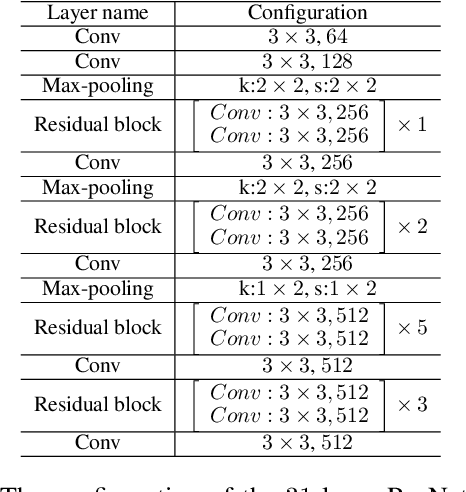
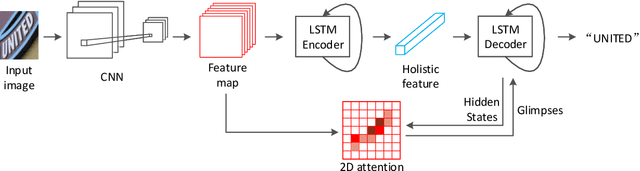
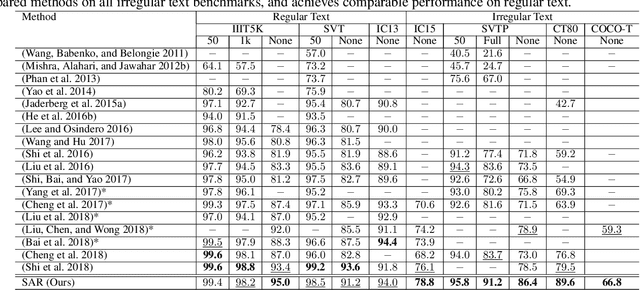
Recognizing irregular text in natural scene images is challenging due to the large variance in text appearance, such as curvature, orientation and distortion. Most existing approaches rely heavily on sophisticated model designs and/or extra fine-grained annotations, which, to some extent, increase the difficulty in algorithm implementation and data collection. In this work, we propose an easy-to-implement strong baseline for irregular scene text recognition, using off-the-shelf neural network components and only word-level annotations. It is composed of a $31$-layer ResNet, an LSTM-based encoder-decoder framework and a 2-dimensional attention module. Despite its simplicity, the proposed method is robust and achieves state-of-the-art performance on both regular and irregular scene text recognition benchmarks. The code will be released.
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Oct 25, 2018
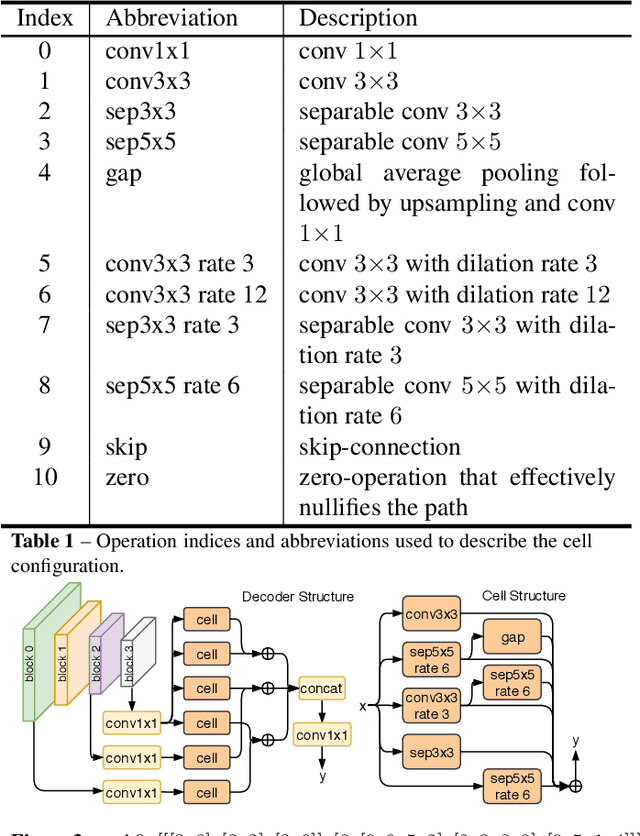
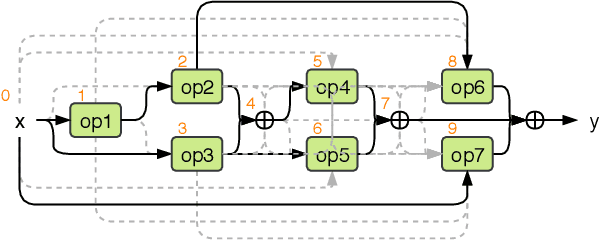

Automated design of architectures tailored for a specific task at hand is an extremely promising, albeit inherently difficult, venue to explore. While most results in this domain have been achieved on image classification and language modelling problems, here we concentrate on dense per-pixel tasks, in particular, semantic image segmentation using fully convolutional networks. In contrast to the aforementioned areas, the design choice of a fully convolutional network requires several changes, ranging from the sort of operations that need to be used - e.g., dilated convolutions - to solving of a more difficult optimisation problem. In this work, we are particularly interested in searching for high-performance compact segmentation architectures, able to run in real-time using limited resources. To achieve that, we intentionally over-parameterise the architecture during the training time via a set of auxiliary cells that provide an intermediate supervisory signal and can be omitted during the evaluation phase. The design of the auxiliary cell is emitted by a controller, a neural architecture with the fixed structure trained using reinforcement learning. More crucially, we demonstrate how to efficiently search for these architectures within limited time and computational budgets. In particular, we rely on a progressive strategy that terminates non-promising architectures from being further trained, and on Polyak averaging coupled with knowledge distillation to speed-up the convergence. Quantitatively, in 8 GPU-days our approach discovers a set of architectures performing on-par with state-of-the-art among compact models.
Light-Weight RefineNet for Real-Time Semantic Segmentation
Oct 08, 2018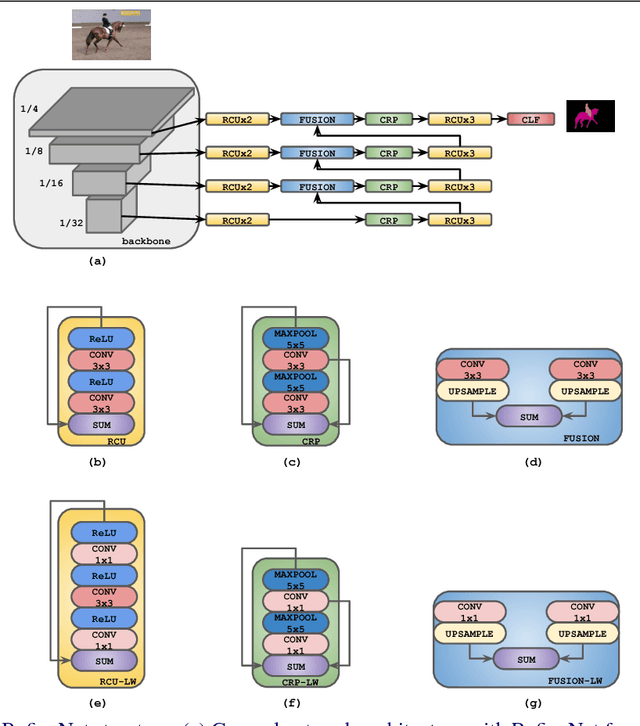

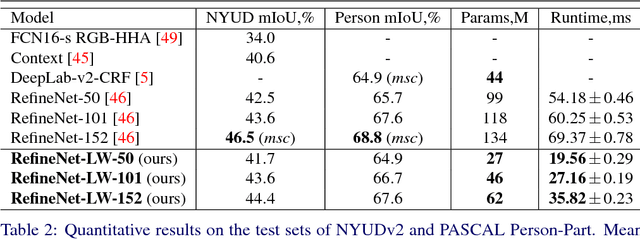

We consider an important task of effective and efficient semantic image segmentation. In particular, we adapt a powerful semantic segmentation architecture, called RefineNet, into the more compact one, suitable even for tasks requiring real-time performance on high-resolution inputs. To this end, we identify computationally expensive blocks in the original setup, and propose two modifications aimed to decrease the number of parameters and floating point operations. By doing that, we achieve more than twofold model reduction, while keeping the performance levels almost intact. Our fastest model undergoes a significant speed-up boost from 20 FPS to 55 FPS on a generic GPU card on 512x512 inputs with solid 81.1% mean iou performance on the test set of PASCAL VOC, while our slowest model with 32 FPS (from original 17 FPS) shows 82.7% mean iou on the same dataset. Alternatively, we showcase that our approach is easily mixable with light-weight classification networks: we attain 79.2% mean iou on PASCAL VOC using a model that contains only 3.3M parameters and performs only 9.3B floating point operations.
Correlation Propagation Networks for Scene Text Detection
Sep 30, 2018

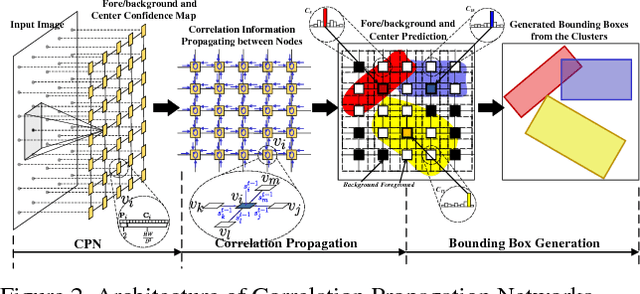

In this work, we propose a novel hybrid method for scene text detection namely Correlation Propagation Network (CPN). It is an end-to-end trainable framework engined by advanced Convolutional Neural Networks. Our CPN predicts text objects according to both top-down observations and the bottom-up cues. Multiple candidate boxes are assembled by a spatial communication mechanism call Correlation Propagation (CP). The extracted spatial features by CNN are regarded as node features in a latticed graph and Correlation Propagation algorithm runs distributively on each node to update the hypothesis of corresponding object centers. The CP process can flexibly handle scale-varying and rotated text objects without using predefined bounding box templates. Benefit from its distributive nature, CPN is computationally efficient and enjoys a high level of parallelism. Moreover, we introduce deformable convolution to the backbone network to enhance the adaptability to long texts. The evaluation on public benchmarks shows that the proposed method achieves state-of-art performance, and it significantly outperforms the existing methods for handling multi-scale and multi-oriented text objects with much lower computation cost.
Diagnostics in Semantic Segmentation
Sep 27, 2018
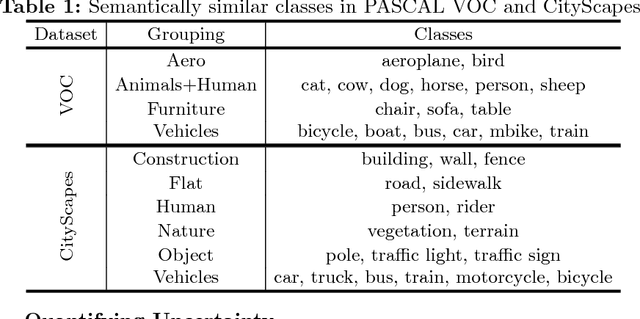
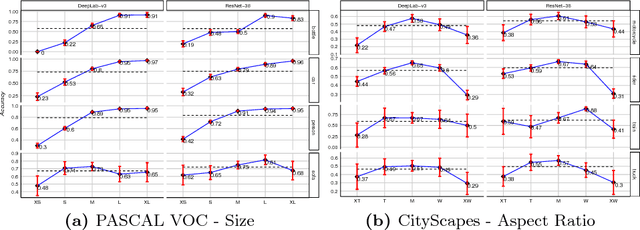
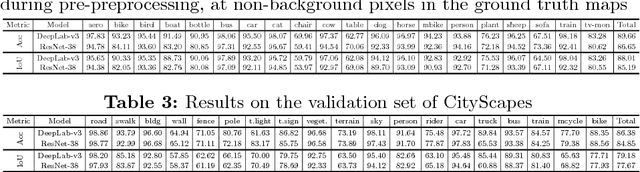
Over the past years, computer vision community has contributed to enormous progress in semantic image segmentation, a per-pixel classification task, crucial for dense scene understanding and rapidly becoming vital in lots of real-world applications, including driverless cars and medical imaging. Most recent models are now reaching previously unthinkable numbers (e.g., 89% mean iou on PASCAL VOC, 83% on CityScapes), and, while intersection-over-union and a range of other metrics provide the general picture of model performance, in this paper we aim to extend them into other meaningful and important for applications characteristics, answering such questions as 'how accurate the model segmentation is on small objects in the general scene?', or 'what are the sources of uncertainty that cause the model to make an erroneous prediction?'. Besides establishing a methodology that covers the performance of a single model from different perspectives, we also showcase several extensions that can be worth pursuing in order to further improve current results in semantic segmentation.