 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture Search of Dynamic Cells for Semantic Video Segmentation
Apr 04, 2019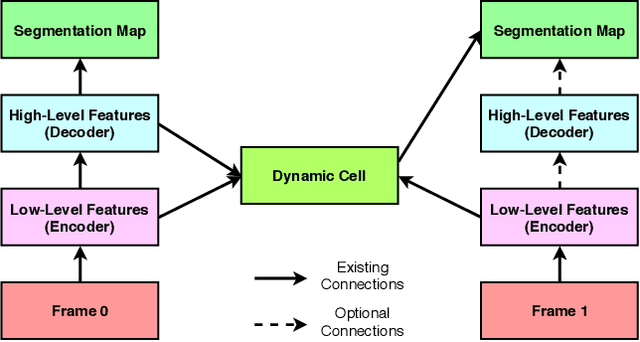

In semantic video segmentation the goal is to acquire consistent dense semantic labelling across image frames. To this end, recent approaches have been reliant on manually arranged operations applied on top of static semantic segmentation networks - with the most prominent building block being the optical flow able to provide information about scene dynamics. Related to that is the line of research concerned with speeding up static networks by approximating expensive parts of them with cheaper alternatives, while propagating information from previous frames. In this work we attempt to come up with generalisation of those methods, and instead of manually designing contextual blocks that connect per-frame outputs, we propose a neural architecture search solution, where the choice of operations together with their sequential arrangement are being predicted by a separate neural network. We showcase that such generalisation leads to stable and accurate results across common benchmarks, such as CityScapes and CamVid datasets. Importantly, the proposed methodology takes only 2 GPU-days, finds high-performing cells and does not rely on the expensive optical flow computation.
Template-Based Automatic Search of Compact Semantic Segmentation Architectures
Apr 04, 2019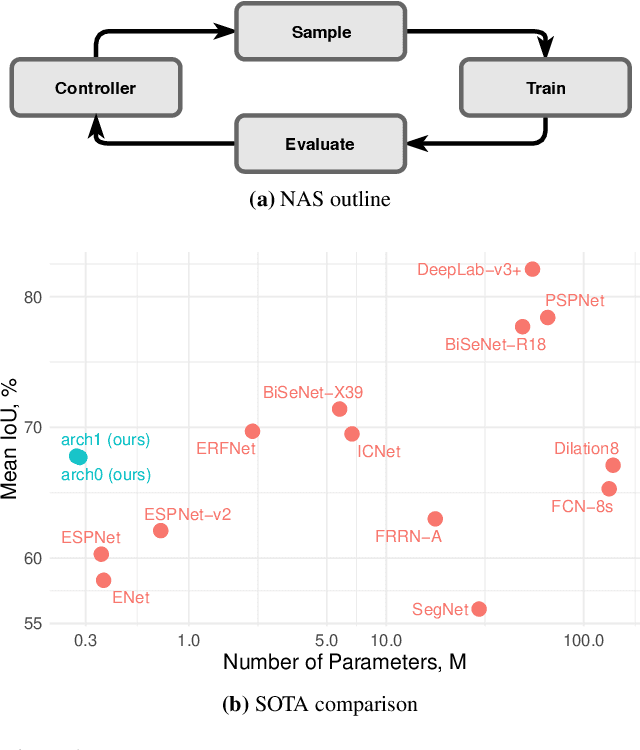
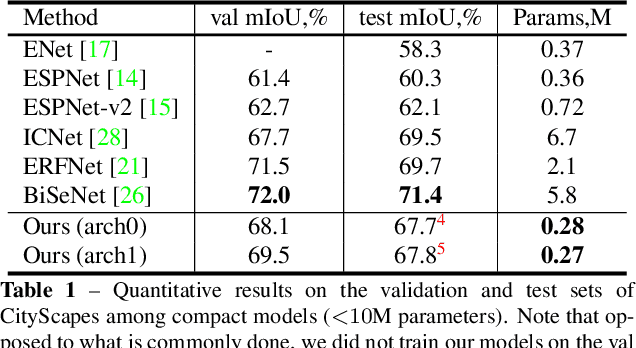
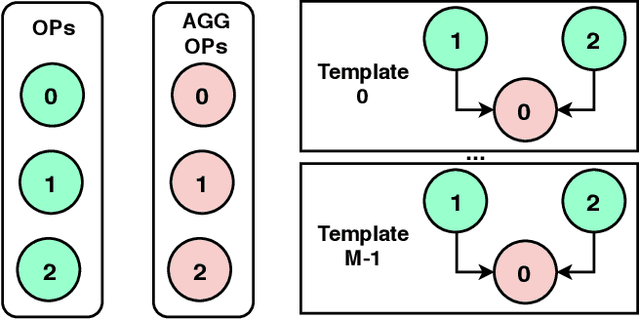
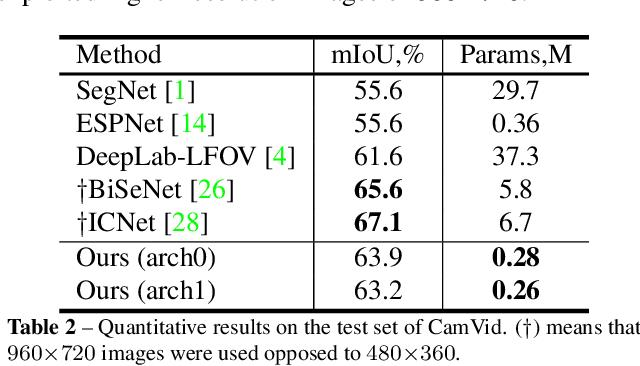
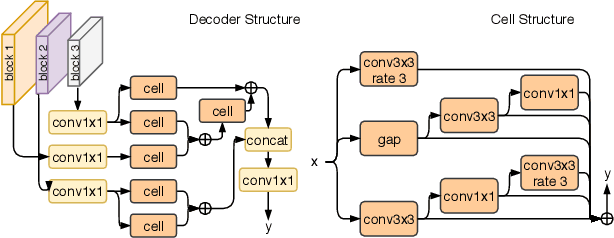
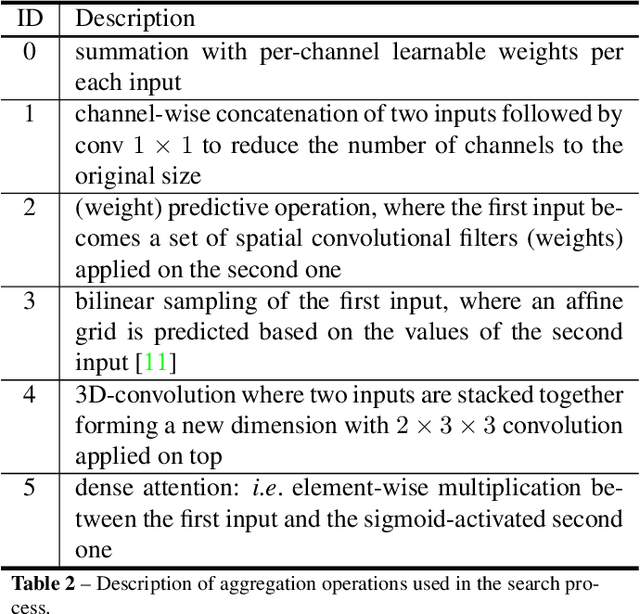
Automatic search of neural architectures for various vision and natural language tasks is becoming a prominent tool as it allows to discover high-performing structures on any dataset of interest. Nevertheless, on more difficult domains, such as dense per-pixel classification, current automatic approaches are limited in their scope - due to their strong reliance on existing image classifiers they tend to search only for a handful of additional layers with discovered architectures still containing a large number of parameters. In contrast, in this work we propose a novel solution able to find light-weight and accurate segmentation architectures starting from only few blocks of a pre-trained classification network. To this end, we progressively build up a methodology that relies on templates of sets of operations, predicts which template and how many times should be applied at each step, while also generating the connectivity structure and downsampling factors. All these decisions are being made by a recurrent neural network that is rewarded based on the score of the emitted architecture on the holdout set and trained using reinforcement learning. One discovered architecture achieves 63.2% mean IoU on CamVid and 67.8% on CityScapes having only 270K parameters.
A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition
Apr 02, 2019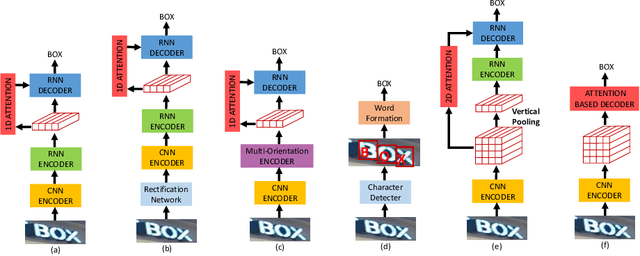
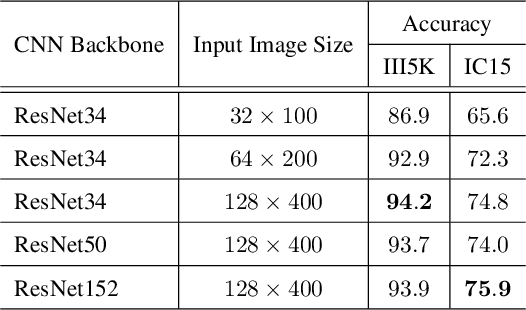
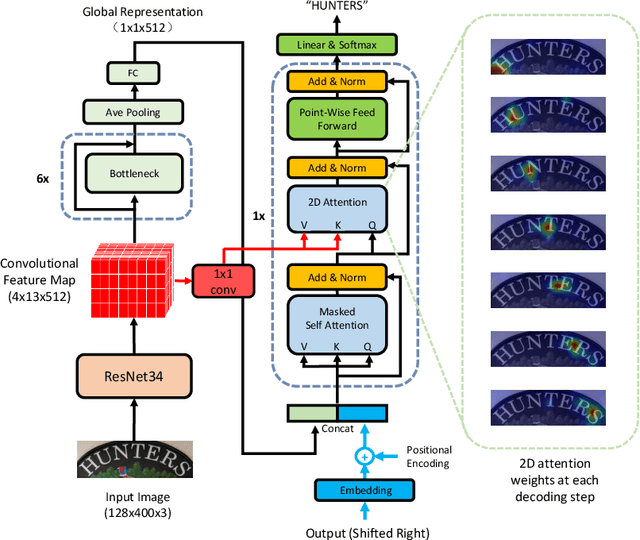
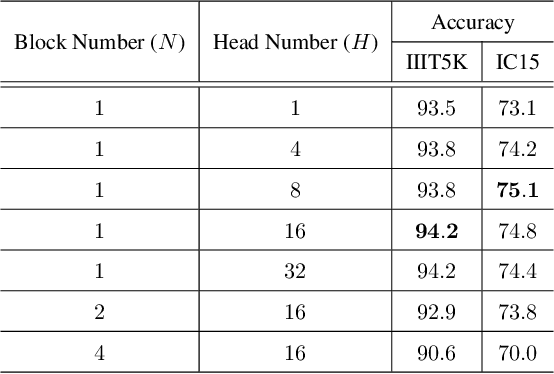
Reading irregular text of arbitrary shape in natural scene images is still a challenging problem. Many existing approaches incorporate sophisticated network structures to handle various shapes, use extra annotations for stronger supervision, or employ hard-to-train recurrent neural networks for sequence modeling. In this work, we propose a simple yet robust approach for irregular text recognition. With no need to convert input images to sequence representations, we directly connect two-dimensional CNN features to an attention-based sequence decoder. As no recurrent module is adopted, our model can be trained in parallel. It achieves 3x to 18x acceleration to backward pass and 2x to 12x acceleration to forward pass, compared with the RNN counterparts. The proposed model is trained with only word-level annotations. With this simple design, our method achieves state-of-the-art or competitive recognition performance on the evaluated regular and irregular scene text benchmark datasets. Furthermore, we show that the recognition performance does not significantly degrade with inaccurate bounding boxes. This is desirable for tasks of end-to-end text detection and recognition: robust recognition performance can still be achieved with an inaccurate text detector. We will release the code.
Training Quantized Network with Auxiliary Gradient Module
Mar 27, 2019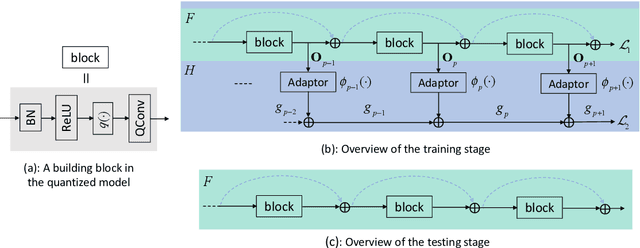
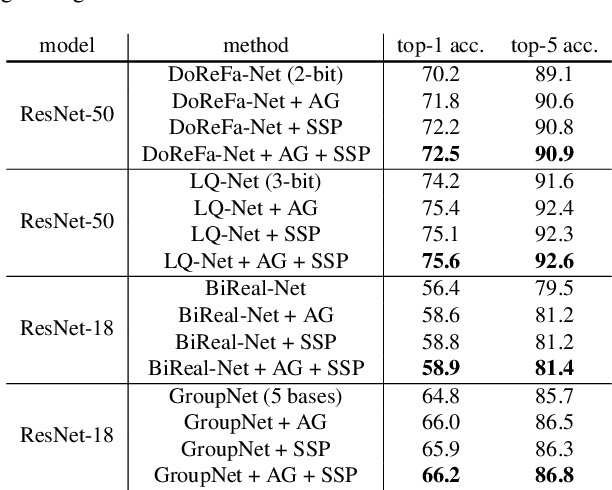
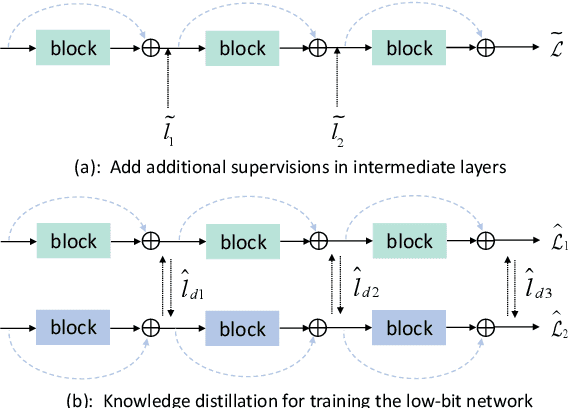

In this paper, we seek to tackle two challenges in training low-precision networks: 1) the notorious difficulty in propagating gradient through a low-precision network due to the non-differentiable quantization function; 2) the requirement of a full-precision realization of skip connections in residual type network architectures. During training, we introduce an auxiliary gradient module which mimics the effect of skip connections to assist the optimization. We then expand the original low-precision network with the full-precision auxiliary gradient module to formulate a mixed-precision residual network and optimize it jointly with the low-precision model using weight sharing and separate batch normalization. This strategy ensures that the gradient back-propagates more easily, thus alleviating a major difficulty in training low-precision networks. Moreover, we find that when training a low-precision plain network with our method, the plain network can achieve performance similar to its counterpart with residual skip connections; i.e. the plain network without floating-point skip connections is just as effective to deploy at inference time. To further promote the gradient flow during backpropagation, we then employ a stochastic structured precision strategy to stochastically sample and quantize sub-networks while keeping other parts full-precision. We evaluate the proposed method on the image classification task over various quantization approaches and show consistent performance increases.
Semi- and Weakly Supervised Directional Bootstrapping Model for Automated Skin Lesion Segmentation
Mar 12, 2019
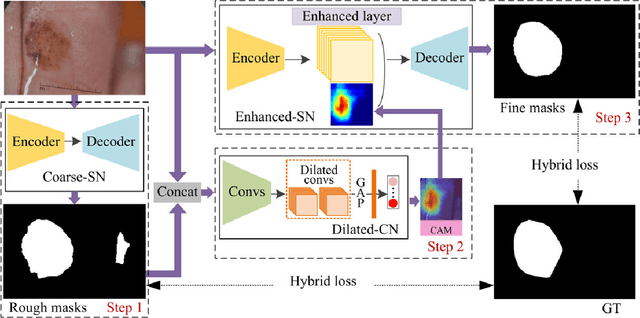
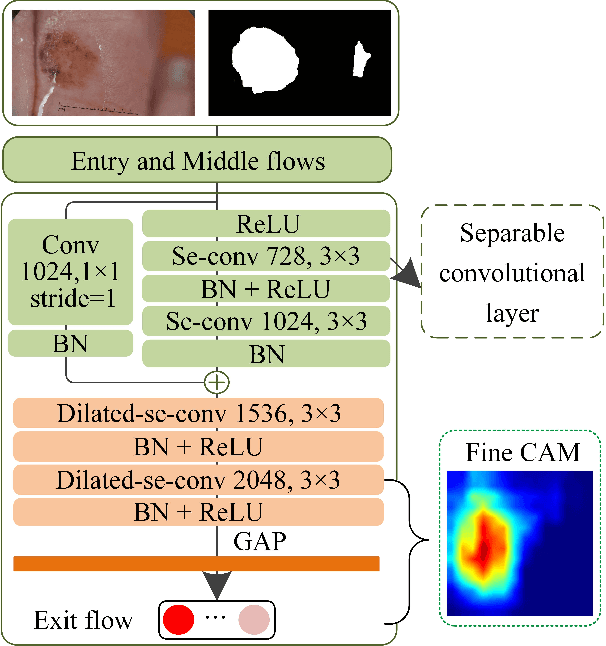

Automated skin lesion segmentation on dermoscopy images is an essential and challenging task in the computer-aided diagnosis of skin cancer. Despite their prevalence and relatively good performance, deep learning based segmentation methods require a myriad number of training images with pixel-level dense annotation, which is hard to obtain due to the efforts and costs related to dermoscopy images acquisition and annotation. In this paper, we propose the semi- and weakly supervised directional bootstrapping (SWSDB) model for skin lesion segmentation, which consists of three deep convolutional neural networks: a coarse segmentation network (coarse-SN), a dilated classification network (dilated-CN) and an enhanced segmentation network (enhanced-SN). Both the coarse-SN and enhanced-SN are trained using the images with pixel-level annotation, and the dilated-CN is trained using the images with image-level class labels. The coarse-SN generates rough segmentation masks that provide a prior bootstrapping for the dilated-CN and help it produce accurate lesion localization maps. The maps are then fed into the enhanced-SN to transfer the localization information learned from image-level labels to the enhanced-SN to generate segmentation results. Furthermore, we introduce a hybrid loss that is the weighted sum of a dice loss and a rank loss to the coarse-SN and enhanced-SN, ensuring both networks' good compatibility for the data with imbalanced classes and imbalanced hard-easy pixels. We evaluated the proposed SWSDB model on the ISIC-2017 challenge dataset and PH2 dataset and achieved a Jaccard index of 80.4% and 89.4%, respectively, setting a new record in skin lesion segmentation.
Knowledge Adaptation for Efficient Semantic Segmentation
Mar 12, 2019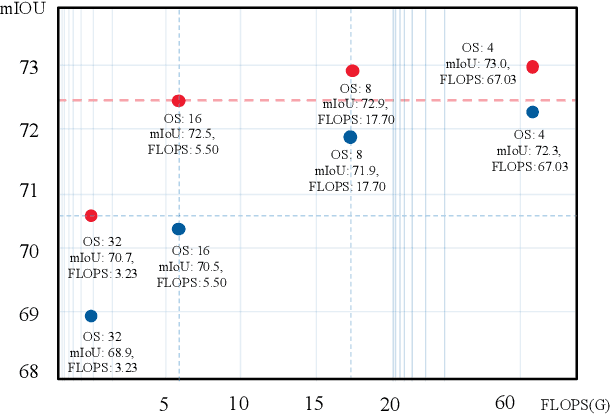
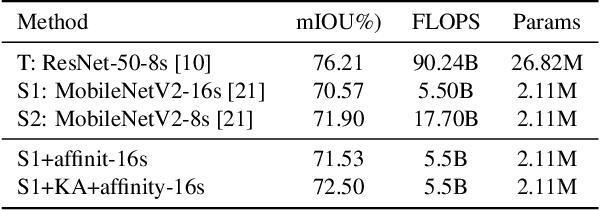
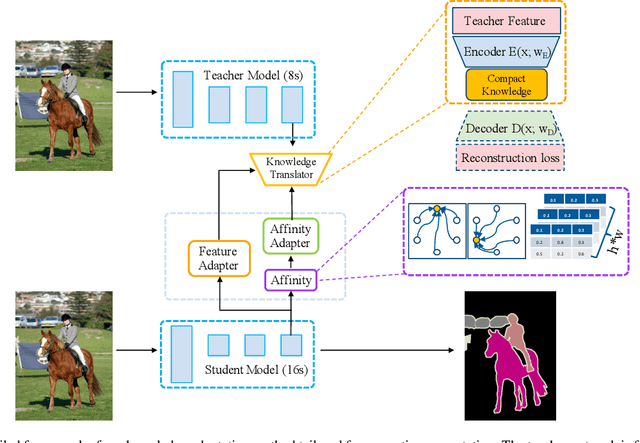
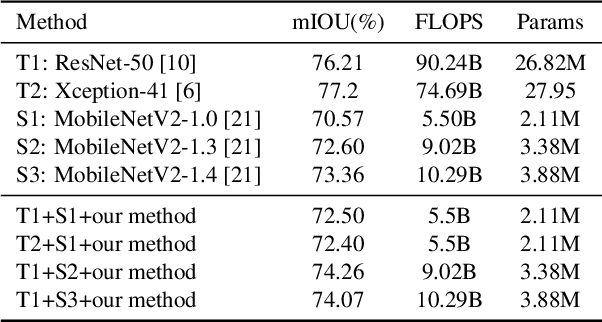
Both accuracy and efficiency are of significant importance to the task of semantic segmentation. Existing deep FCNs suffer from heavy computations due to a series of high-resolution feature maps for preserving the detailed knowledge in dense estimation. Although reducing the feature map resolution (i.e., applying a large overall stride) via subsampling operations (e.g., pooling and convolution striding) can instantly increase the efficiency, it dramatically decreases the estimation accuracy. To tackle this dilemma, we propose a knowledge distillation method tailored for semantic segmentation to improve the performance of the compact FCNs with large overall stride. To handle the inconsistency between the features of the student and teacher network, we optimize the feature similarity in a transferred latent domain formulated by utilizing a pre-trained autoencoder. Moreover, an affinity distillation module is proposed to capture the long-range dependency by calculating the non-local interactions across the whole image. To validate the effectiveness of our proposed method, extensive experiments have been conducted on three popular benchmarks: Pascal VOC, Cityscapes and Pascal Context. Built upon a highly competitive baseline, our proposed method can improve the performance of a student network by 2.5\% (mIOU boosts from 70.2 to 72.7 on the cityscapes test set) and can train a better compact model with only 8\% float operations (FLOPS) of a model that achieves comparable performances.
CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning
Mar 06, 2019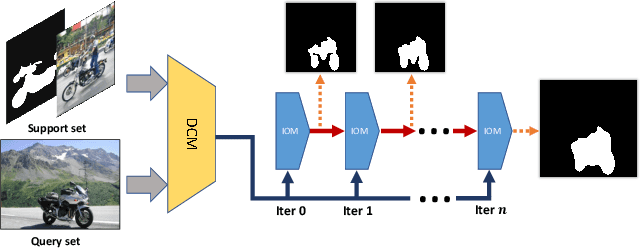
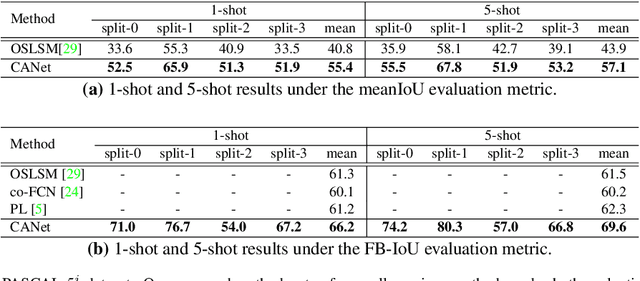
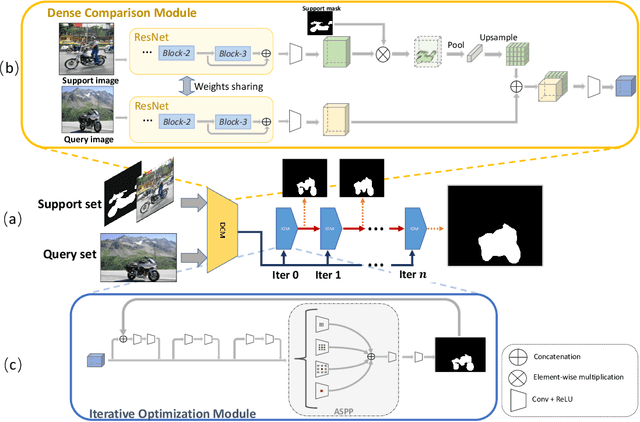

Recent progress in semantic segmentation is driven by deep Convolutional Neural Networks and large-scale labeled image datasets. However, data labeling for pixel-wise segmentation is tedious and costly. Moreover, a trained model can only make predictions within a set of pre-defined classes. In this paper, we present CANet, a class-agnostic segmentation network that performs few-shot segmentation on new classes with only a few annotated images available. Our network consists of a two-branch dense comparison module which performs multi-level feature comparison between the support image and the query image, and an iterative optimization module which iteratively refines the predicted results. Furthermore, we introduce an attention mechanism to effectively fuse information from multiple support examples under the setting of k-shot learning. Experiments on PASCAL VOC 2012 show that our method achieves a mean Intersection-over-Union score of 55.4% for 1-shot segmentation and 57.1% for 5-shot segmentation, outperforming state-of-the-art methods by a large margin of 14.6% and 13.2%, respectively.
Associatively Segmenting Instances and Semantics in Point Clouds
Feb 28, 2019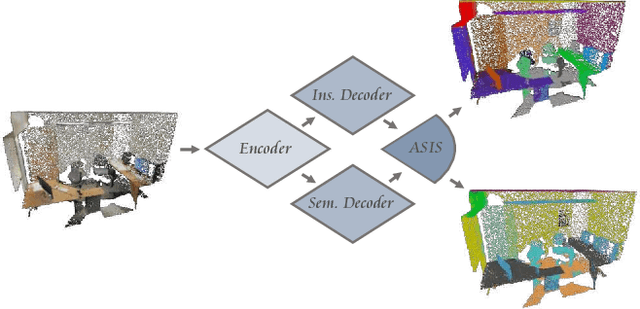
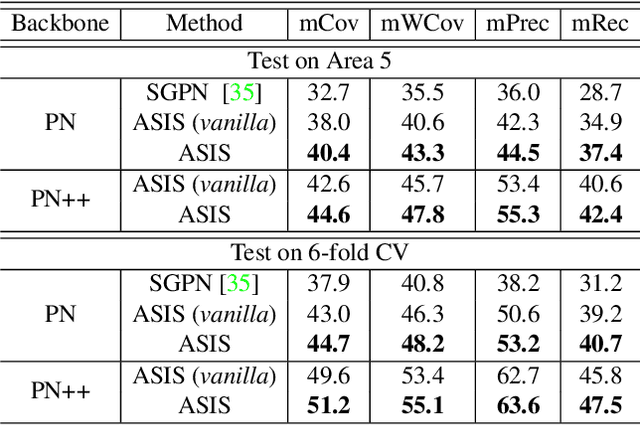

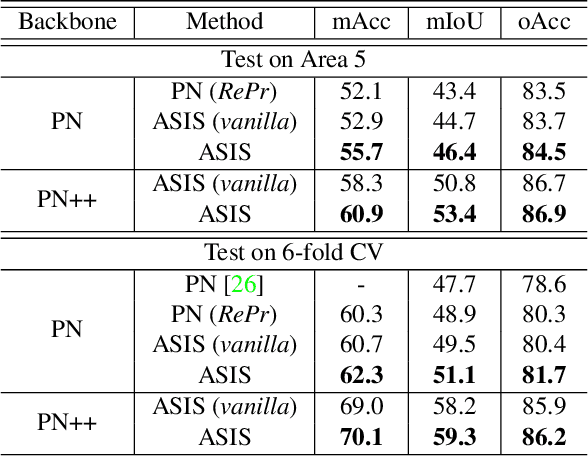
A 3D point cloud describes the real scene precisely and intuitively.To date how to segment diversified elements in such an informative 3D scene is rarely discussed. In this paper, we first introduce a simple and flexible framework to segment instances and semantics in point clouds simultaneously. Then, we propose two approaches which make the two tasks take advantage of each other, leading to a win-win situation. Specifically, we make instance segmentation benefit from semantic segmentation through learning semantic-aware point-level instance embedding. Meanwhile, semantic features of the points belonging to the same instance are fused together to make more accurate per-point semantic predictions. Our method largely outperforms the state-of-the-art method in 3D instance segmentation along with a significant improvement in 3D semantic segmentation. Code has been made available at: https://github.com/WXinlong/ASIS.
Salient Object Detection with Lossless Feature Reflection and Weighted Structural Loss
Jan 21, 2019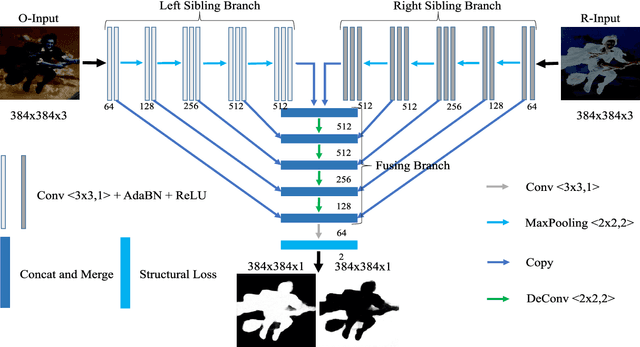


Salient object detection (SOD), which aims to identify and locate the most salient pixels or regions in images, has been attracting more and more interest due to its various real-world applications. However, this vision task is quite challenging, especially under complex image scenes. Inspired by the intrinsic reflection of natural images, in this paper we propose a novel feature learning framework for large-scale salient object detection. Specifically, we design a symmetrical fully convolutional network (SFCN) to effectively learn complementary saliency features under the guidance of lossless feature reflection. The location information, together with contextual and semantic information, of salient objects are jointly utilized to supervise the proposed network for more accurate saliency predictions. In addition, to overcome the blurry boundary problem, we propose a new weighted structural loss function to ensure clear object boundaries and spatially consistent saliency. The coarse prediction results are effectively refined by these structural information for performance improvements. Extensive experiments on seven saliency detection datasets demonstrate that our approach achieves consistently superior performance and outperforms the very recent state-of-the-art methods with a large margin.
Neighbourhood Watch: Referring Expression Comprehension via Language-guided Graph Attention Networks
Dec 12, 2018

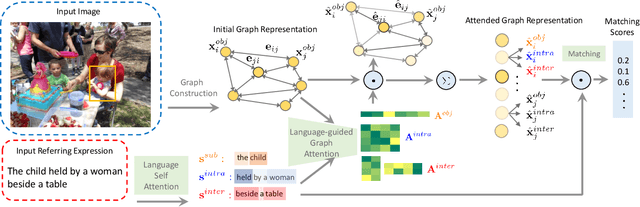
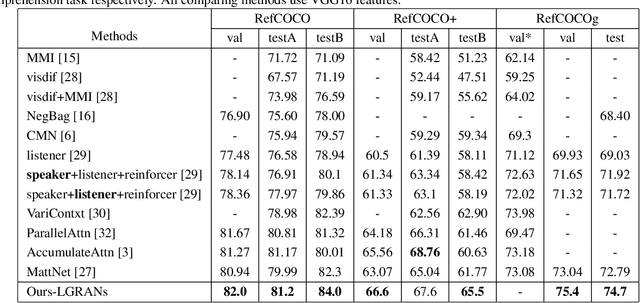
The task in referring expression comprehension is to localise the object instance in an image described by a referring expression phrased in natural language. As a language-to-vision matching task, the key to this problem is to learn a discriminative object feature that can adapt to the expression used. To avoid ambiguity, the expression normally tends to describe not only the properties of the referent itself, but also its relationships to its neighbourhood. To capture and exploit this important information we propose a graph-based, language-guided attention mechanism. Being composed of node attention component and edge attention component, the proposed graph attention mechanism explicitly represents inter-object relationships, and properties with a flexibility and power impossible with competing approaches. Furthermore, the proposed graph attention mechanism enables the comprehension decision to be visualisable and explainable. Experiments on three referring expression comprehension datasets show the advantage of the proposed approach.