 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Hierarchical Patterns for identifying MDD patients: A Multisite Study
Feb 22, 2022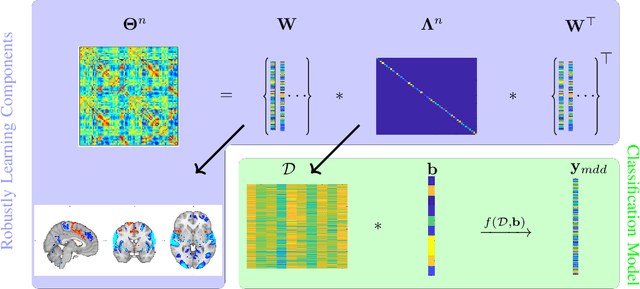
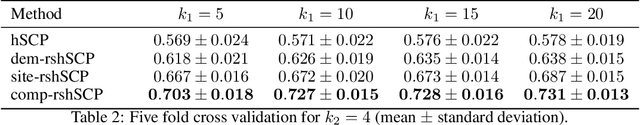

Many supervised machine learning frameworks have been proposed for disease classification using functional magnetic resonance imaging (fMRI) data, producing important biomarkers. More recently, data pooling has flourished, making the result generalizable across a large population. But, this success depends on the population diversity and variability introduced due to the pooling of the data that is not a primary research interest. Here, we look at hierarchical Sparse Connectivity Patterns (hSCPs) as biomarkers for major depressive disorder (MDD). We propose a novel model based on hSCPs to predict MDD patients from functional connectivity matrices extracted from resting-state fMRI data. Our model consists of three coupled terms. The first term decomposes connectivity matrices into hierarchical low-rank sparse components corresponding to synchronous patterns across the human brain. These components are then combined via patient-specific weights capturing heterogeneity in the data. The second term is a classification loss that uses the patient-specific weights to classify MDD patients from healthy ones. Both of these terms are combined with the third term, a robustness loss function to improve the reproducibility of hSCPs. This reduces the variability introduced due to site and population diversity (age and sex) on the predictive accuracy and pattern stability in a large dataset pooled from five different sites. Our results show the impact of diversity on prediction performance. Our model can reduce diversity and improve the predictive and generalizing capability of the components. Finally, our results show that our proposed model can robustly identify clinically relevant patterns characteristic of MDD with high reproducibility.
Subtyping brain diseases from imaging data
Feb 16, 2022
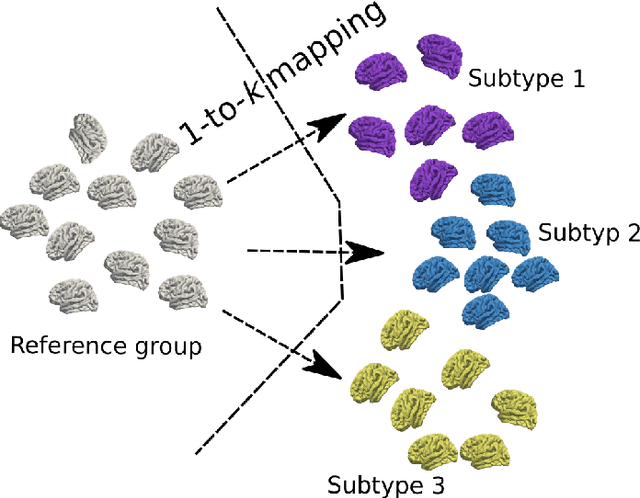
The imaging community has increasingly adopted machine learning (ML) methods to provide individualized imaging signatures related to disease diagnosis, prognosis, and response to treatment. Clinical neuroscience and cancer imaging have been two areas in which ML has offered particular promise. However, many neurologic and neuropsychiatric diseases, as well as cancer, are often heterogeneous in terms of their clinical manifestations, neuroanatomical patterns or genetic underpinnings. Therefore, in such cases, seeking a single disease signature might be ineffectual in delivering individualized precision diagnostics. The current chapter focuses on ML methods, especially semi-supervised clustering, that seek disease subtypes using imaging data. Work from Alzheimer Disease and its prodromal stages, psychosis, depression, autism, and brain cancer are discussed. Our goal is to provide the readers with a broad overview in terms of methodology and clinical applications.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021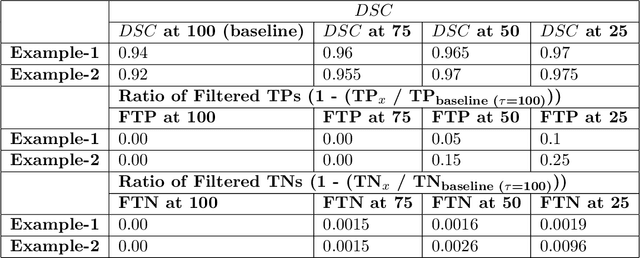
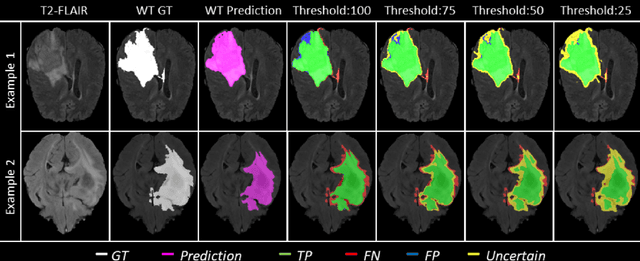
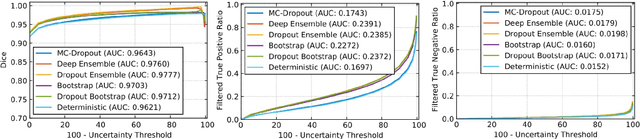
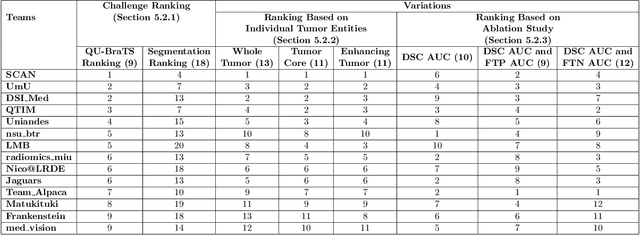
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
The Brain Tumor Sequence Registration Challenge: Establishing Correspondence between Pre-Operative and Follow-up MRI scans of diffuse glioma patients
Dec 13, 2021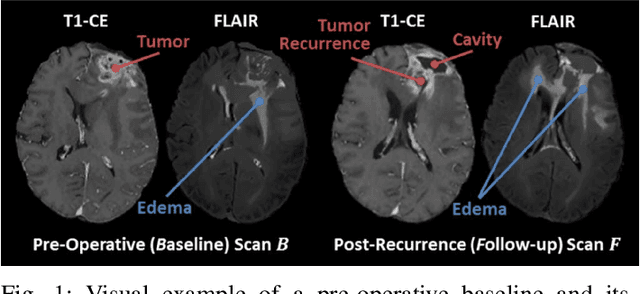
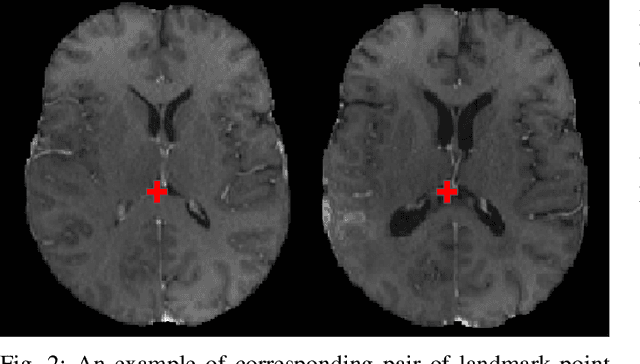
Registration of longitudinal brain Magnetic Resonance Imaging (MRI) scans containing pathologies is challenging due to tissue appearance changes, and still an unsolved problem. This paper describes the first Brain Tumor Sequence Registration (BraTS-Reg) challenge, focusing on estimating correspondences between pre-operative and follow-up scans of the same patient diagnosed with a brain diffuse glioma. The BraTS-Reg challenge intends to establish a public benchmark environment for deformable registration algorithms. The associated dataset comprises de-identified multi-institutional multi-parametric MRI (mpMRI) data, curated for each scan's size and resolution, according to a common anatomical template. Clinical experts have generated extensive annotations of landmarks points within the scans, descriptive of distinct anatomical locations across the temporal domain. The training data along with these ground truth annotations will be released to participants to design and develop their registration algorithms, whereas the annotations for the validation and the testing data will be withheld by the organizers and used to evaluate the containerized algorithms of the participants. Each submitted algorithm will be quantitatively evaluated using several metrics, such as the Median Absolute Error (MAE), Robustness, and the Jacobian determinant.
Multidimensional representations in late-life depression: convergence in neuroimaging, cognition, clinical symptomatology and genetics
Oct 25, 2021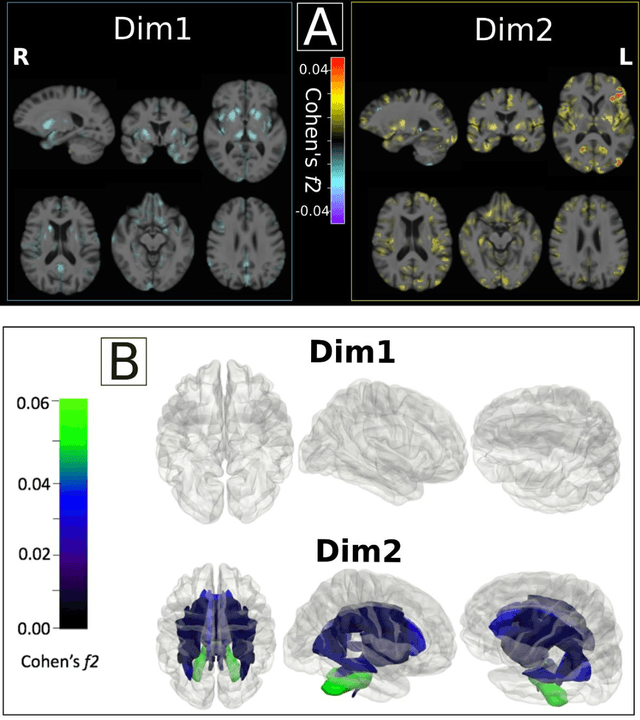
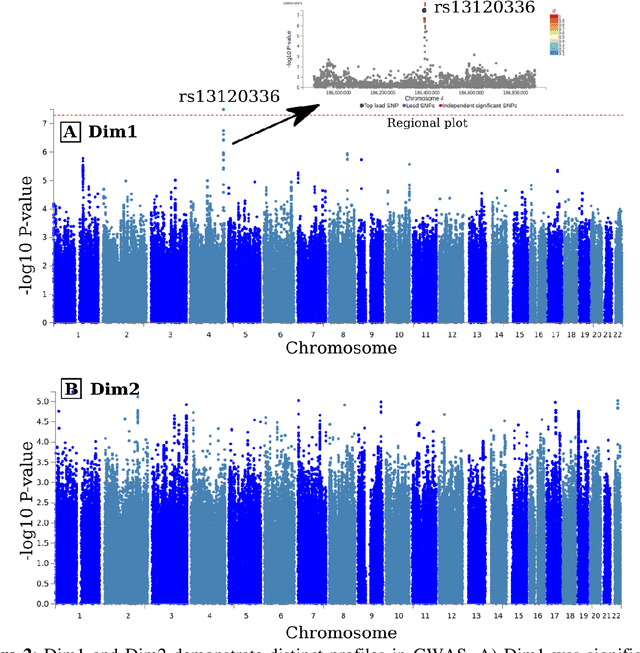
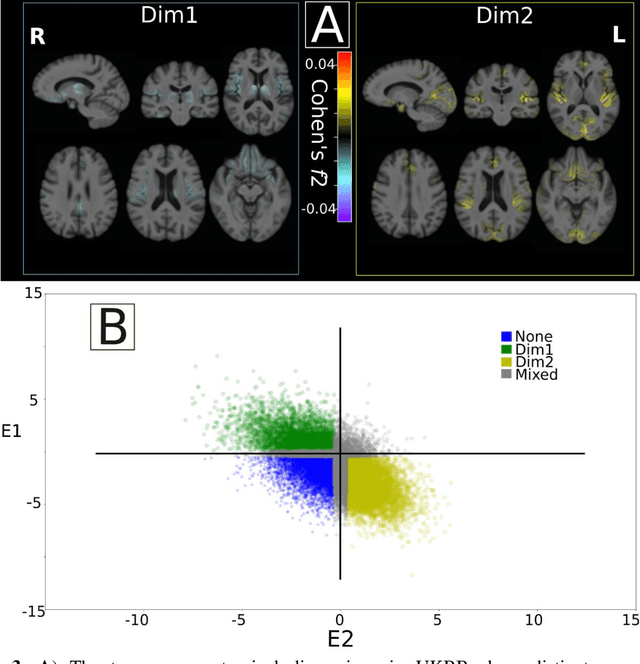
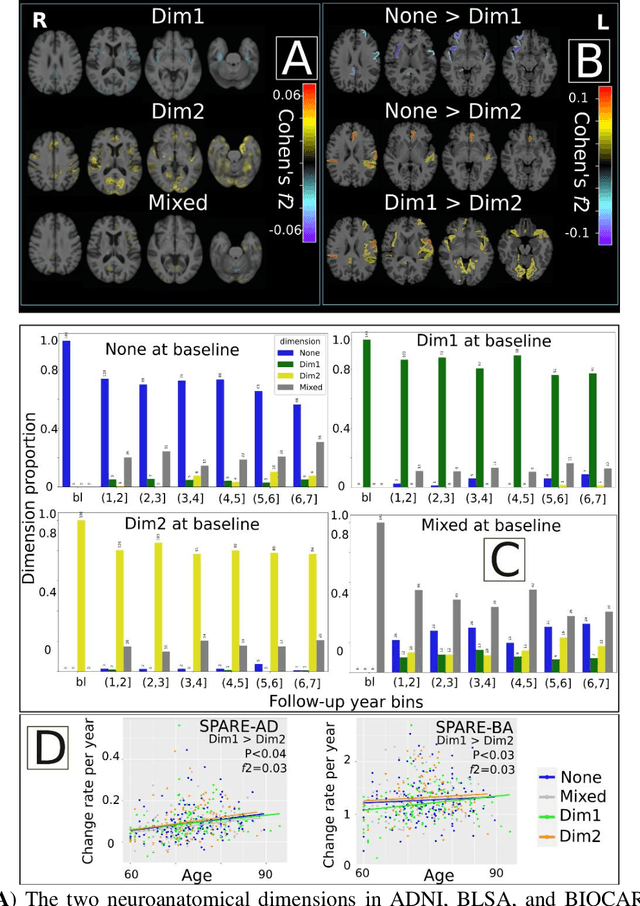
Late-life depression (LLD) is characterized by considerable heterogeneity in clinical manifestation. Unraveling such heterogeneity would aid in elucidating etiological mechanisms and pave the road to precision and individualized medicine. We sought to delineate, cross-sectionally and longitudinally, disease-related heterogeneity in LLD linked to neuroanatomy, cognitive functioning, clinical symptomatology, and genetic profiles. Multimodal data from a multicentre sample (N=996) were analyzed. A semi-supervised clustering method (HYDRA) was applied to regional grey matter (GM) brain volumes to derive dimensional representations. Two dimensions were identified, which accounted for the LLD-related heterogeneity in voxel-wise GM maps, white matter (WM) fractional anisotropy (FA), neurocognitive functioning, clinical phenotype, and genetics. Dimension one (Dim1) demonstrated relatively preserved brain anatomy without WM disruptions relative to healthy controls. In contrast, dimension two (Dim2) showed widespread brain atrophy and WM integrity disruptions, along with cognitive impairment and higher depression severity. Moreover, one de novo independent genetic variant (rs13120336) was significantly associated with Dim 1 but not with Dim 2. Notably, the two dimensions demonstrated significant SNP-based heritability of 18-27% within the general population (N=12,518 in UKBB). Lastly, in a subset of individuals having longitudinal measurements, Dim2 demonstrated a more rapid longitudinal decrease in GM and brain age, and was more likely to progress to Alzheimers disease, compared to Dim1 (N=1,413 participants and 7,225 scans from ADNI, BLSA, and BIOCARD datasets).
Disentangling Alzheimer's disease neurodegeneration from typical brain aging using machine learning
Sep 08, 2021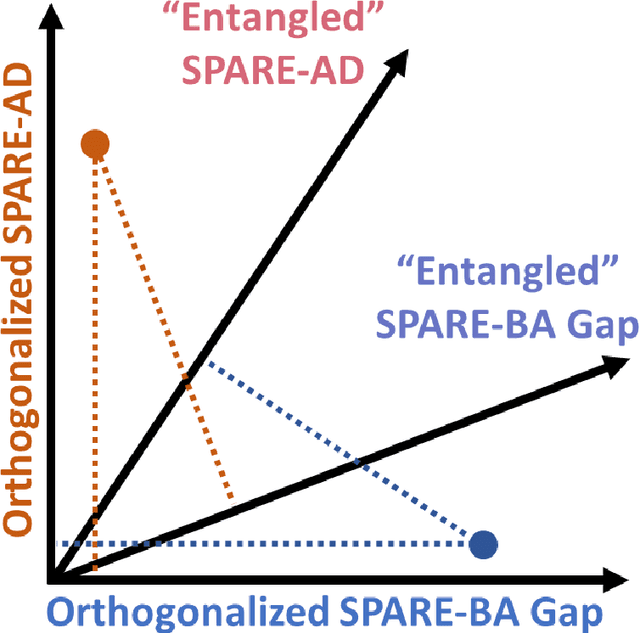
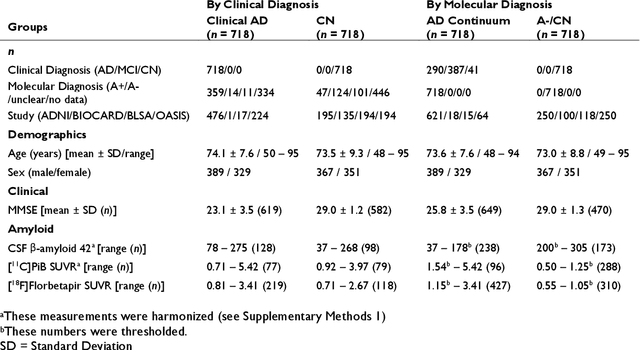
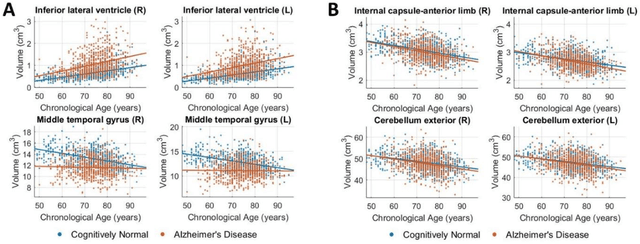
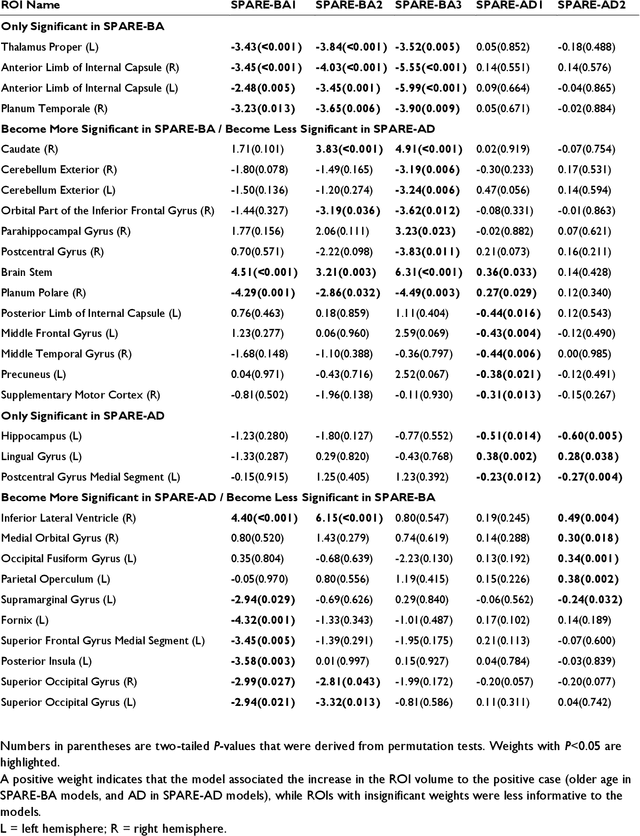
Neuroimaging biomarkers that distinguish between typical brain aging and Alzheimer's disease (AD) are valuable for determining how much each contributes to cognitive decline. Machine learning models can derive multi-variate brain change patterns related to the two processes, including the SPARE-AD (Spatial Patterns of Atrophy for Recognition of Alzheimer's Disease) and SPARE-BA (of Brain Aging) investigated herein. However, substantial overlap between brain regions affected in the two processes confounds measuring them independently. We present a methodology toward disentangling the two. T1-weighted MRI images of 4,054 participants (48-95 years) with AD, mild cognitive impairment (MCI), or cognitively normal (CN) diagnoses from the iSTAGING (Imaging-based coordinate SysTem for AGIng and NeurodeGenerative diseases) consortium were analyzed. First, a subset of AD patients and CN adults were selected based purely on clinical diagnoses to train SPARE-BA1 (regression of age using CN individuals) and SPARE-AD1 (classification of CN versus AD). Second, analogous groups were selected based on clinical and molecular markers to train SPARE-BA2 and SPARE-AD2: amyloid-positive (A+) AD continuum group (consisting of A+AD, A+MCI, and A+ and tau-positive CN individuals) and amyloid-negative (A-) CN group. Finally, the combined group of the AD continuum and A-/CN individuals was used to train SPARE-BA3, with the intention to estimate brain age regardless of AD-related brain changes. Disentangled SPARE models derived brain patterns that were more specific to the two types of the brain changes. Correlation between the SPARE-BA and SPARE-AD was significantly reduced. Correlation of disentangled SPARE-AD was non-inferior to the molecular measurements and to the number of APOE4 alleles, but was less to AD-related psychometric test scores, suggesting contribution of advanced brain aging to these scores.
Harmonization with Flow-based Causal Inference
Jul 10, 2021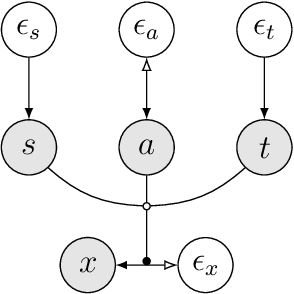
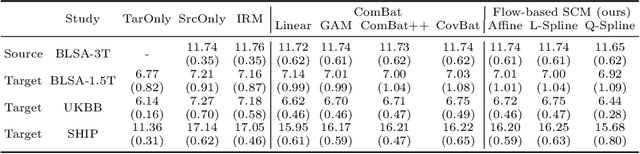
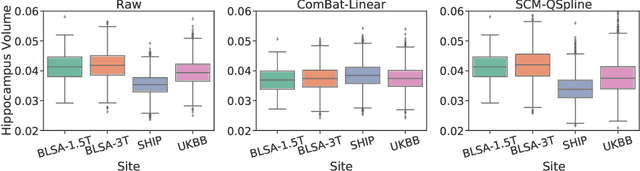
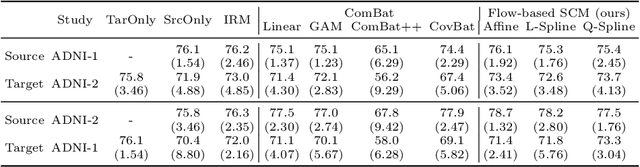
Heterogeneity in medical data, e.g., from data collected at different sites and with different protocols in a clinical study, is a fundamental hurdle for accurate prediction using machine learning models, as such models often fail to generalize well. This paper leverages a recently proposed normalizing-flow-based method to perform counterfactual inference upon a structural causal model (SCM), in order to achieve harmonization of such data. A causal model is used to model observed effects (brain magnetic resonance imaging data) that result from known confounders (site, gender and age) and exogenous noise variables. Our formulation exploits the bijection induced by flow for the purpose of harmonization. We infer the posterior of exogenous variables, intervene on observations, and draw samples from the resultant SCM to obtain counterfactuals. This approach is evaluated extensively on multiple, large, real-world medical datasets and displayed better cross-domain generalization compared to state-of-the-art algorithms. Further experiments that evaluate the quality of confounder-independent data generated by our model using regression and classification tasks are provided.
The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification
Jul 05, 2021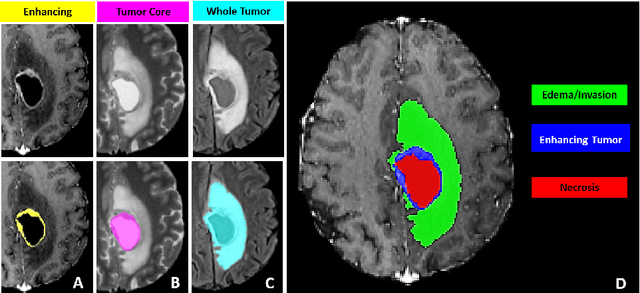
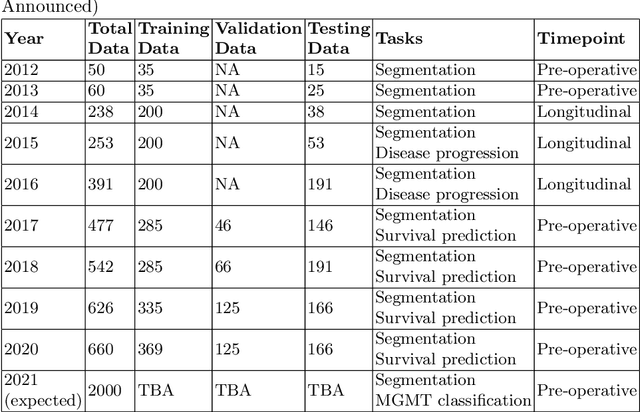
The BraTS 2021 challenge celebrates its 10th anniversary and is jointly organized by the Radiological Society of North America (RSNA), the American Society of Neuroradiology (ASNR), and the Medical Image Computing and Computer Assisted Interventions (MICCAI) society. Since its inception, BraTS has been focusing on being a common benchmarking venue for brain glioma segmentation algorithms, with well-curated multi-institutional multi-parametric magnetic resonance imaging (mpMRI) data. Gliomas are the most common primary malignancies of the central nervous system, with varying degrees of aggressiveness and prognosis. The RSNA-ASNR-MICCAI BraTS 2021 challenge targets the evaluation of computational algorithms assessing the same tumor compartmentalization, as well as the underlying tumor's molecular characterization, in pre-operative baseline mpMRI data from 2,000 patients. Specifically, the two tasks that BraTS 2021 focuses on are: a) the segmentation of the histologically distinct brain tumor sub-regions, and b) the classification of the tumor's O[6]-methylguanine-DNA methyltransferase (MGMT) promoter methylation status. The performance evaluation of all participating algorithms in BraTS 2021 will be conducted through the Sage Bionetworks Synapse platform (Task 1) and Kaggle (Task 2), concluding in distributing to the top ranked participants monetary awards of $60,000 collectively.
The Federated Tumor Segmentation (FeTS) Challenge
May 14, 2021
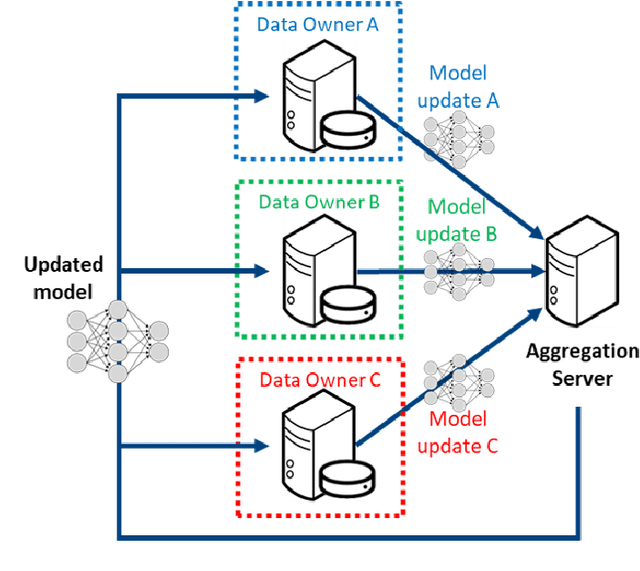
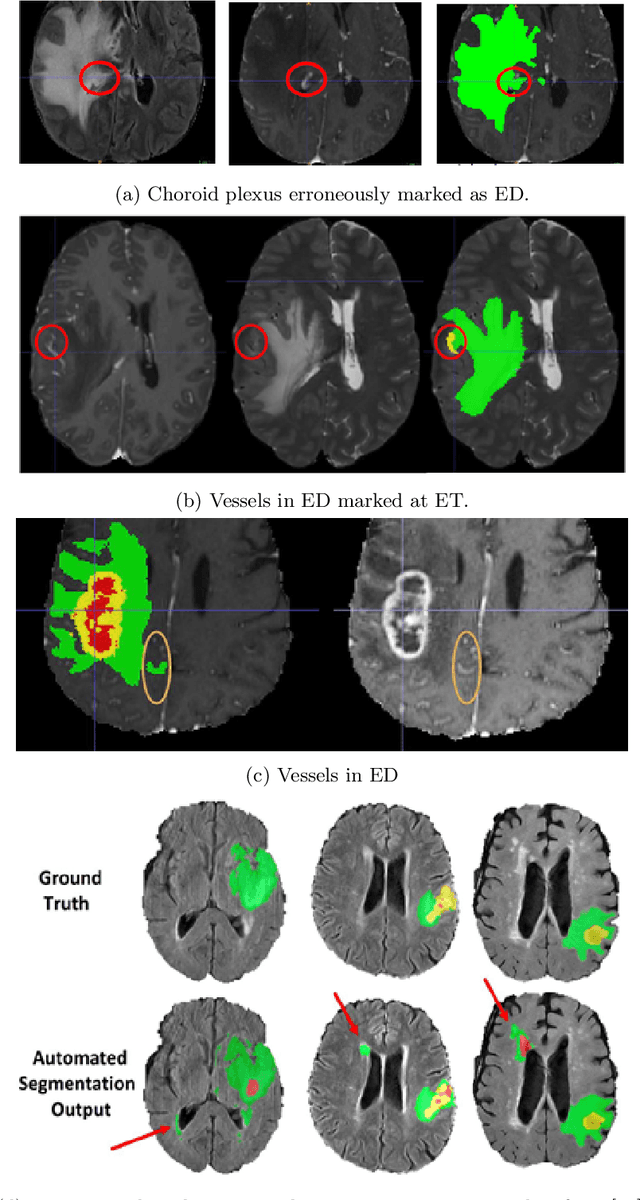
This manuscript describes the first challenge on Federated Learning, namely the Federated Tumor Segmentation (FeTS) challenge 2021. International challenges have become the standard for validation of biomedical image analysis methods. However, the actual performance of participating (even the winning) algorithms on "real-world" clinical data often remains unclear, as the data included in challenges are usually acquired in very controlled settings at few institutions. The seemingly obvious solution of just collecting increasingly more data from more institutions in such challenges does not scale well due to privacy and ownership hurdles. Towards alleviating these concerns, we are proposing the FeTS challenge 2021 to cater towards both the development and the evaluation of models for the segmentation of intrinsically heterogeneous (in appearance, shape, and histology) brain tumors, namely gliomas. Specifically, the FeTS 2021 challenge uses clinically acquired, multi-institutional magnetic resonance imaging (MRI) scans from the BraTS 2020 challenge, as well as from various remote independent institutions included in the collaborative network of a real-world federation (https://www.fets.ai/). The goals of the FeTS challenge are directly represented by the two included tasks: 1) the identification of the optimal weight aggregation approach towards the training of a consensus model that has gained knowledge via federated learning from multiple geographically distinct institutions, while their data are always retained within each institution, and 2) the federated evaluation of the generalizability of brain tumor segmentation models "in the wild", i.e. on data from institutional distributions that were not part of the training datasets.
Learning Robust Hierarchical Patterns of Human Brain across Many fMRI Studies
May 13, 2021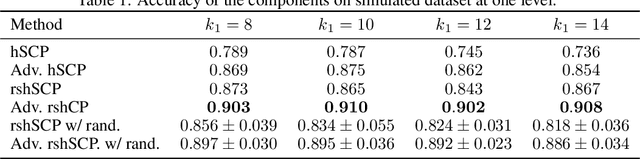
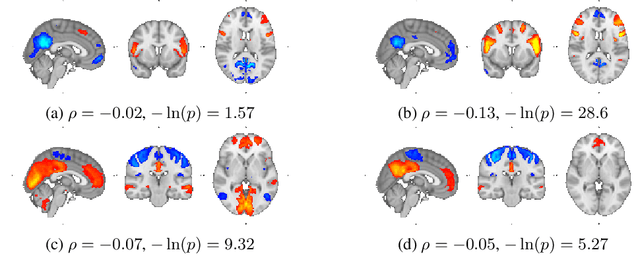
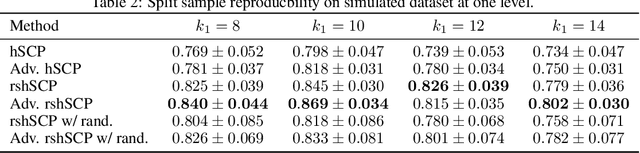
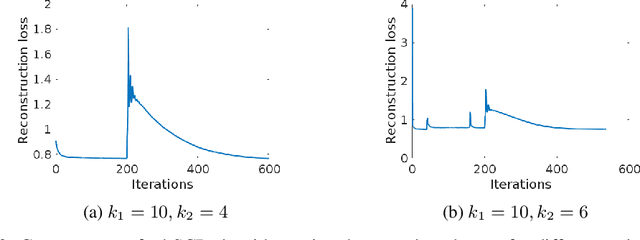
Resting-state fMRI has been shown to provide surrogate biomarkers for the analysis of various diseases. In addition, fMRI data helps in understanding the brain's functional working during resting state and task-induced activity. To improve the statistical power of biomarkers and the understanding mechanism of the brain, pooling of multi-center studies has become increasingly popular. But pooling the data from multiple sites introduces variations due to hardware, software, and environment. In this paper, we look at the estimation problem of hierarchical Sparsity Connectivity Patterns (hSCPs) in fMRI data acquired on multiple sites. We introduce a simple yet effective matrix factorization based formulation to reduce site-related effects while preserving biologically relevant variations. We leverage adversarial learning in the unsupervised regime to improve the reproducibility of the components. Experiments on simulated datasets display that the proposed method can estimate components with improved accuracy and reproducibility. We also demonstrate the improved reproducibility of the components while preserving age-related variation on a real dataset compiled from multiple sites.