 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pseudo-colorizing of Masked Cells
Feb 12, 2023



Self-supervised learning, which is strikingly referred to as the dark matter of intelligence, is gaining more attention in biomedical applications of deep learning. In this work, we introduce a novel self-supervision objective for the analysis of cells in biomedical microscopy images. We propose training deep learning models to pseudo-colorize masked cells. We use a physics-informed pseudo-spectral colormap that is well suited for colorizing cell topology. Our experiments reveal that approximating semantic segmentation by pseudo-colorization is beneficial for subsequent fine-tuning on cell detection. Inspired by the recent success of masked image modeling, we additionally mask out cell parts and train to reconstruct these parts to further enrich the learned representations. We compare our pre-training method with self-supervised frameworks including contrastive learning (SimCLR), masked autoencoders (MAEs), and edge-based self-supervision. We build upon our previous work and train hybrid models for cell detection, which contain both convolutional and vision transformer modules. Our pre-training method can outperform SimCLR, MAE-like masked image modeling, and edge-based self-supervision when pre-training on a diverse set of six fluorescence microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former
Space, Time, and Interaction: A Taxonomy of Corner Cases in Trajectory Datasets for Automated Driving
Oct 17, 2022
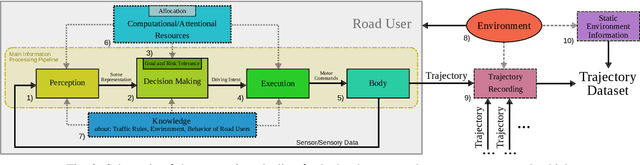
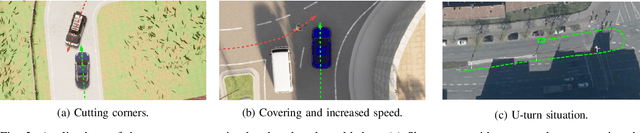
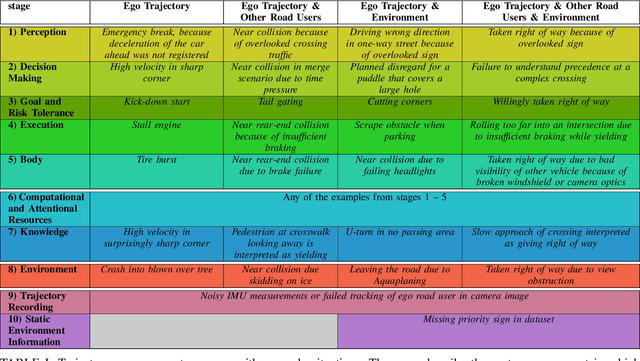
Trajectory data analysis is an essential component for highly automated driving. Complex models developed with these data predict other road users' movement and behavior patterns. Based on these predictions - and additional contextual information such as the course of the road, (traffic) rules, and interaction with other road users - the highly automated vehicle (HAV) must be able to reliably and safely perform the task assigned to it, e.g., moving from point A to B. Ideally, the HAV moves safely through its environment, just as we would expect a human driver to do. However, if unusual trajectories occur, so-called trajectory corner cases, a human driver can usually cope well, but an HAV can quickly get into trouble. In the definition of trajectory corner cases, which we provide in this work, we will consider the relevance of unusual trajectories with respect to the task at hand. Based on this, we will also present a taxonomy of different trajectory corner cases. The categorization of corner cases into the taxonomy will be shown with examples and is done by cause and required data sources. To illustrate the complexity between the machine learning (ML) model and the corner case cause, we present a general processing chain underlying the taxonomy.
Robust Self-Tuning Data Association for Geo-Referencing Using Lane Markings
Jul 28, 2022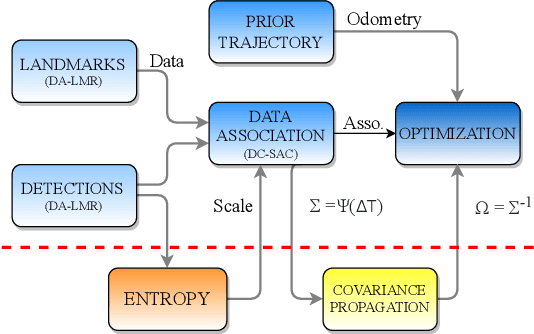
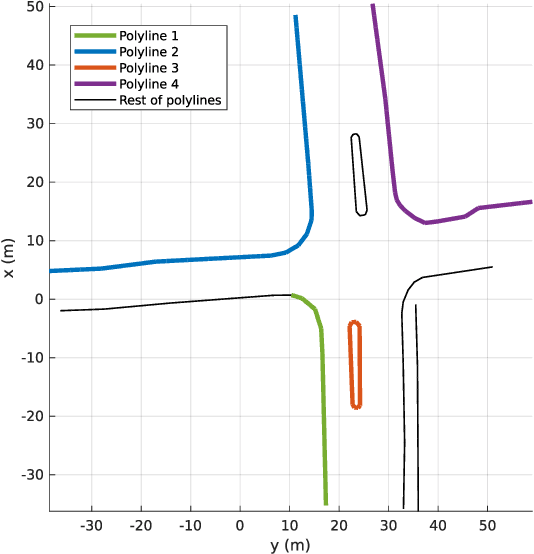
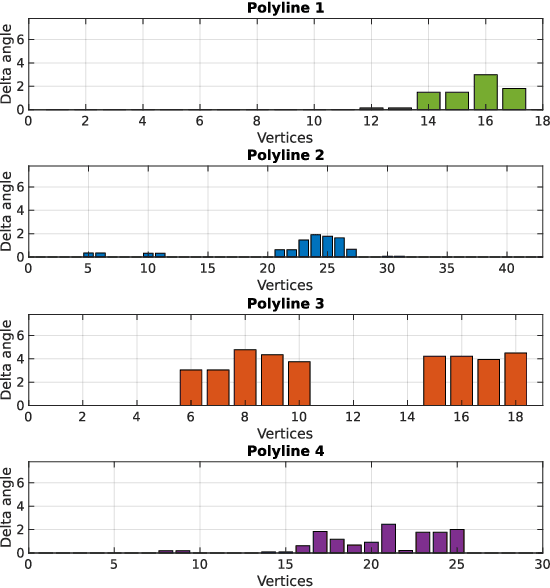
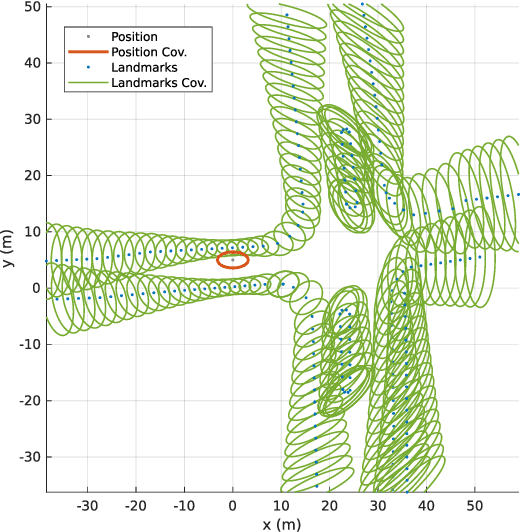
Localization in aerial imagery-based maps offers many advantages, such as global consistency, geo-referenced maps, and the availability of publicly accessible data. However, the landmarks that can be observed from both aerial imagery and on-board sensors is limited. This leads to ambiguities or aliasing during the data association. Building upon a highly informative representation (that allows efficient data association), this paper presents a complete pipeline for resolving these ambiguities. Its core is a robust self-tuning data association that adapts the search area depending on the entropy of the measurements. Additionally, to smooth the final result, we adjust the information matrix for the associated data as a function of the relative transform produced by the data association process. We evaluate our method on real data from urban and rural scenarios around the city of Karlsruhe in Germany. We compare state-of-the-art outlier mitigation methods with our self-tuning approach, demonstrating a considerable improvement, especially for outer-urban scenarios.
Improving Predictive Performance and Calibration by Weight Fusion in Semantic Segmentation
Jul 22, 2022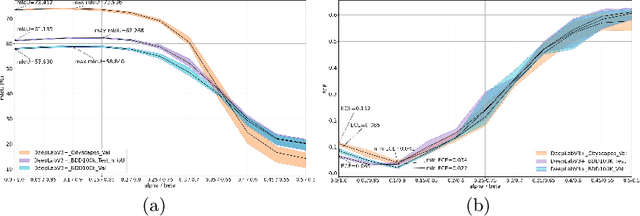

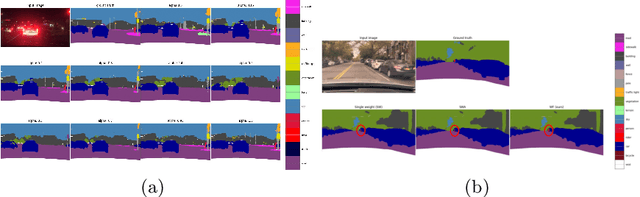
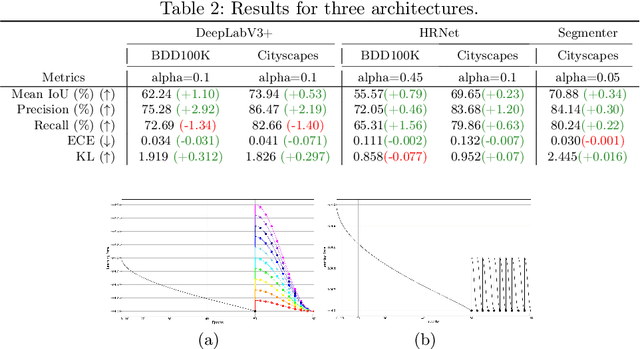
Averaging predictions of a deep ensemble of networks is apopular and effective method to improve predictive performance andcalibration in various benchmarks and Kaggle competitions. However, theruntime and training cost of deep ensembles grow linearly with the size ofthe ensemble, making them unsuitable for many applications. Averagingensemble weights instead of predictions circumvents this disadvantageduring inference and is typically applied to intermediate checkpoints ofa model to reduce training cost. Albeit effective, only few works haveimproved the understanding and the performance of weight averaging.Here, we revisit this approach and show that a simple weight fusion (WF)strategy can lead to a significantly improved predictive performance andcalibration. We describe what prerequisites the weights must meet interms of weight space, functional space and loss. Furthermore, we presenta new test method (called oracle test) to measure the functional spacebetween weights. We demonstrate the versatility of our WF strategy acrossstate of the art segmentation CNNs and Transformers as well as real worlddatasets such as BDD100K and Cityscapes. We compare WF with similarapproaches and show our superiority for in- and out-of-distribution datain terms of predictive performance and calibration.
Mapping LiDAR and Camera Measurements in a Dual Top-View Grid Representation Tailored for Automated Vehicles
Apr 21, 2022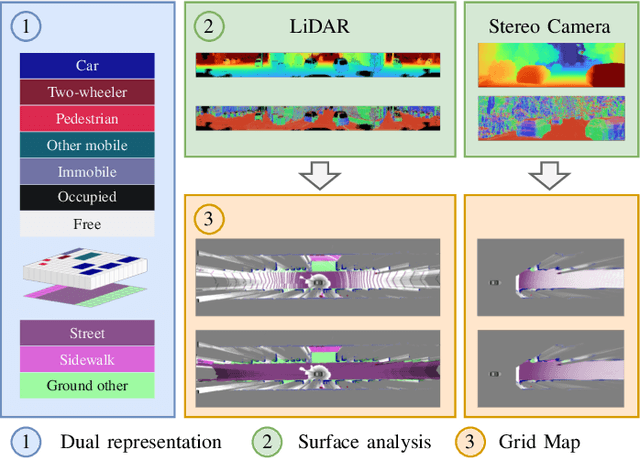

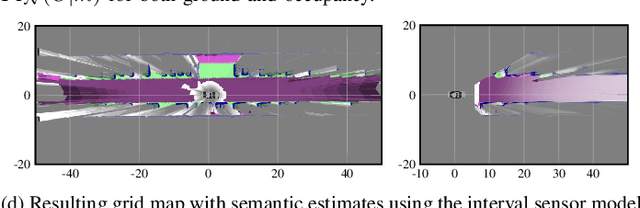

We present a generic evidential grid mapping pipeline designed for imaging sensors such as LiDARs and cameras. Our grid-based evidential model contains semantic estimates for cell occupancy and ground separately. We specify the estimation steps for input data represented by point sets, but mainly focus on input data represented by images such as disparity maps or LiDAR range images. Instead of relying on an external ground segmentation only, we deduce occupancy evidence by analyzing the surface orientation around measurements. We conduct experiments and evaluate the presented method using LiDAR and stereo camera data recorded in real traffic scenarios. Our method estimates cell occupancy robustly and with a high level of detail while maximizing efficiency and minimizing the dependency to external processing modules.
Sensor Data Fusion in Top-View Grid Maps using Evidential Reasoning with Advanced Conflict Resolution
Apr 19, 2022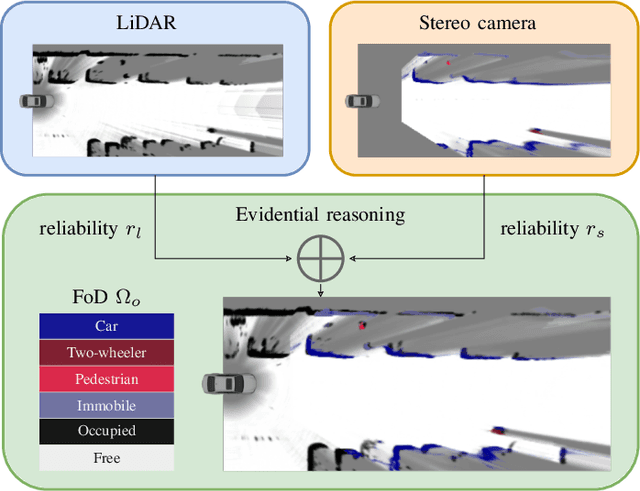
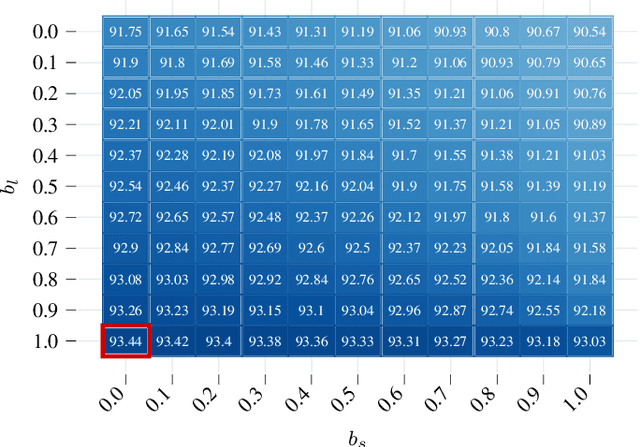

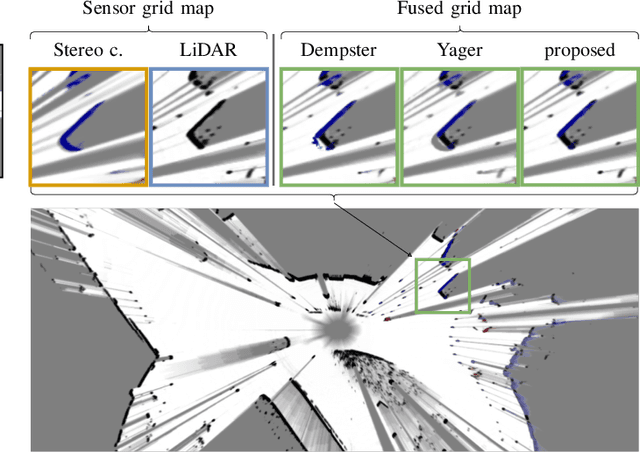
We present a new method to combine evidential top-view grid maps estimated based on heterogeneous sensor sources. Dempster's combination rule that is usually applied in this context provides undesired results with highly conflicting inputs. Therefore, we use more advanced evidential reasoning techniques and improve the conflict resolution by modeling the reliability of the evidence sources. We propose a data-driven reliability estimation to optimize the fusion quality using the Kitti-360 dataset. We apply the proposed method to the fusion of LiDAR and stereo camera data and evaluate the results qualitatively and quantitatively. The results demonstrate that our proposed method robustly combines measurements from heterogeneous sensors and successfully resolves sensor conflicts.
Fast and Robust Ground Surface Estimation from LIDAR Measurements using Uniform B-Splines
Mar 02, 2022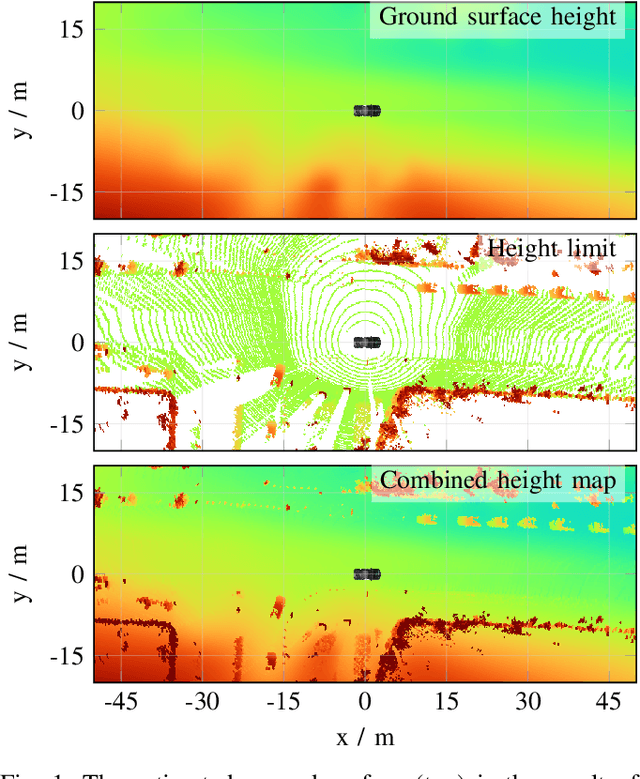

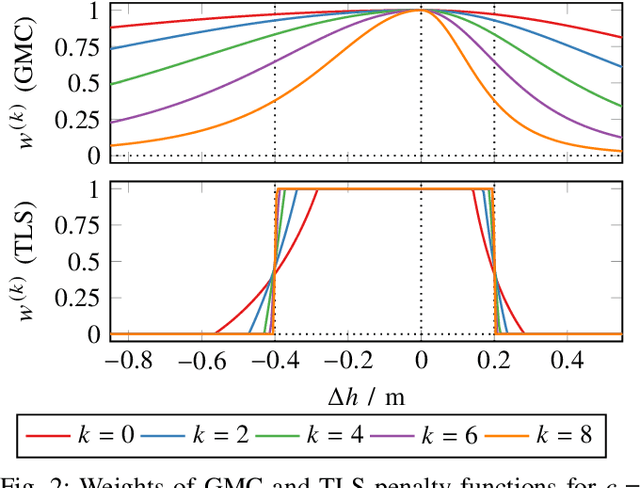
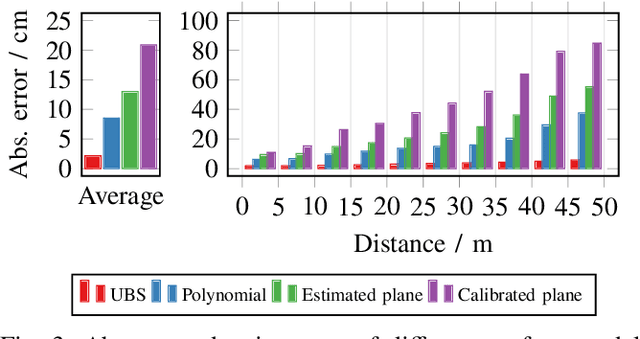
We propose a fast and robust method to estimate the ground surface from LIDAR measurements on an automated vehicle. The ground surface is modeled as a UBS which is robust towards varying measurement densities and with a single parameter controlling the smoothness prior. We model the estimation process as a robust LS optimization problem which can be reformulated as a linear problem and thus solved efficiently. Using the SemanticKITTI data set, we conduct a quantitative evaluation by classifying the point-wise semantic annotations into ground and non-ground points. Finally, we validate the approach on our research vehicle in real-world scenarios.
Improving Lidar-Based Semantic Segmentation of Top-View Grid Maps by Learning Features in Complementary Representations
Mar 02, 2022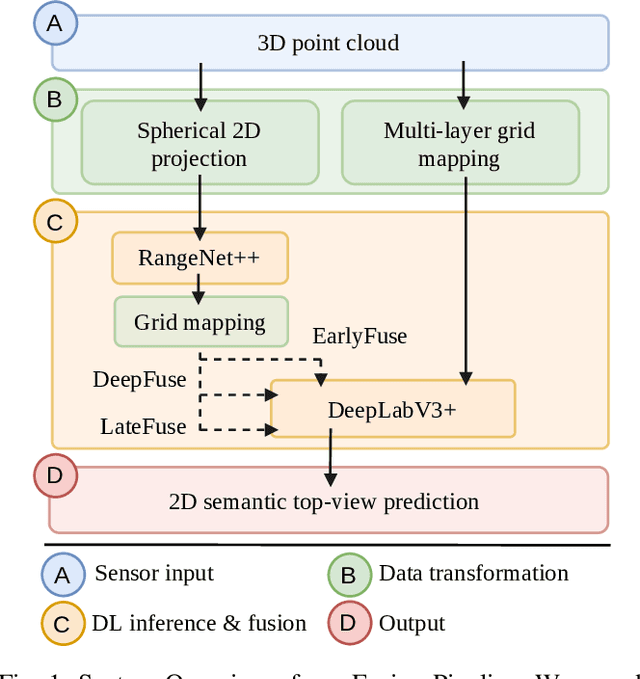
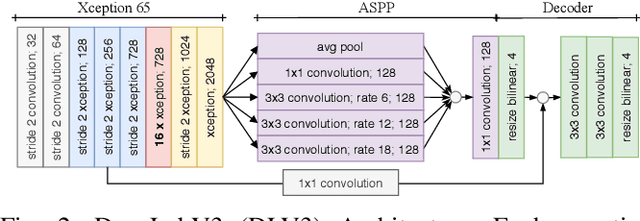
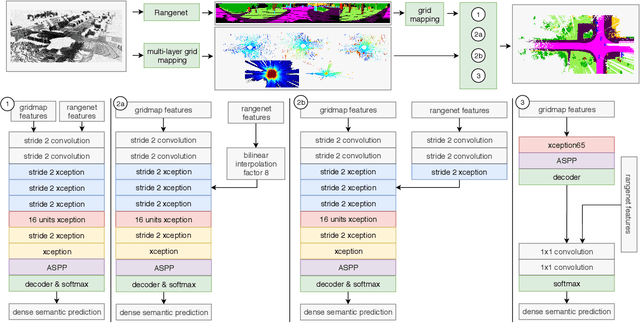

In this paper we introduce a novel way to predict semantic information from sparse, single-shot LiDAR measurements in the context of autonomous driving. In particular, we fuse learned features from complementary representations. The approach is aimed specifically at improving the semantic segmentation of top-view grid maps. Towards this goal the 3D LiDAR point cloud is projected onto two orthogonal 2D representations. For each representation a tailored deep learning architecture is developed to effectively extract semantic information which are fused by a superordinate deep neural network. The contribution of this work is threefold: (1) We examine different stages within the segmentation network for fusion. (2) We quantify the impact of embedding different features. (3) We use the findings of this survey to design a tailored deep neural network architecture leveraging respective advantages of different representations. Our method is evaluated using the SemanticKITTI dataset which provides a point-wise semantic annotation of more than 23.000 LiDAR measurements.
Large-Scale 3D Semantic Reconstruction for Automated Driving Vehicles with Adaptive Truncated Signed Distance Function
Feb 28, 2022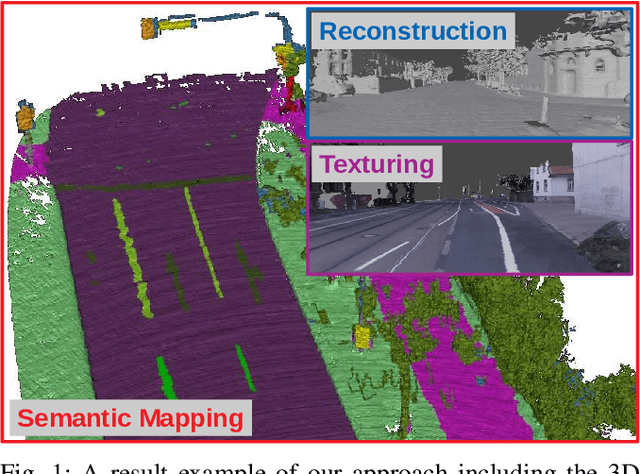
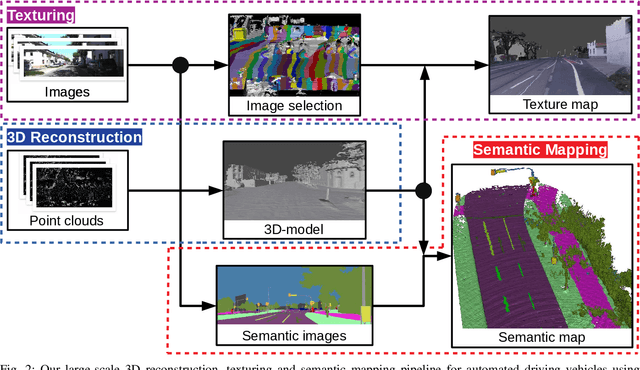
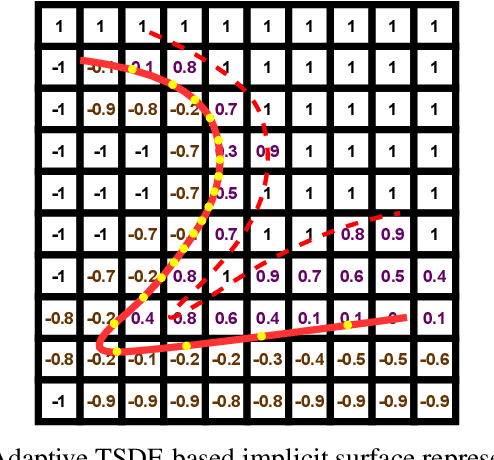

The Large-scale 3D reconstruction, texturing and semantic mapping are nowadays widely used for automated driving vehicles, virtual reality and automatic data generation. However, most approaches are developed for RGB-D cameras with colored dense point clouds and not suitable for large-scale outdoor environments using sparse LiDAR point clouds. Since a 3D surface can be usually observed from multiple camera images with different view poses, an optimal image patch selection for the texturing and an optimal semantic class estimation for the semantic mapping are still challenging. To address these problems, we propose a novel 3D reconstruction, texturing and semantic mapping system using LiDAR and camera sensors. An Adaptive Truncated Signed Distance Function is introduced to describe surfaces implicitly, which can deal with different LiDAR point sparsities and improve model quality. The from this implicit function extracted triangle mesh map is then textured from a series of registered camera images by applying an optimal image patch selection strategy. Besides that, a Markov Random Field-based data fusion approach is proposed to estimate the optimal semantic class for each triangle mesh. Our approach is evaluated on a synthetic dataset, the KITTI dataset and a dataset recorded with our experimental vehicle. The results show that the 3D models generated using our approach are more accurate in comparison to using other state-of-the-art approaches. The texturing and semantic mapping achieve also very promising results.
TEScalib: Targetless Extrinsic Self-Calibration of LiDAR and Stereo Camera for Automated Driving Vehicles with Uncertainty Analysis
Feb 28, 2022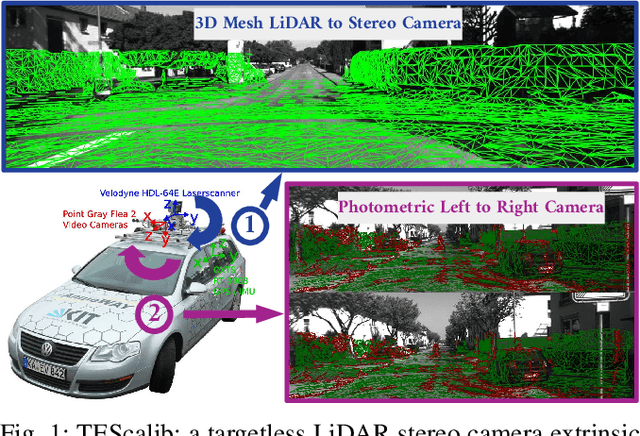
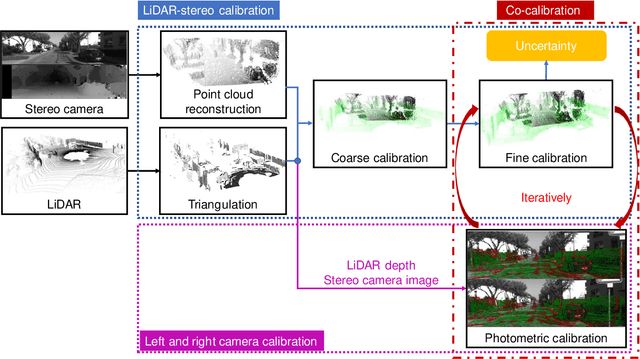
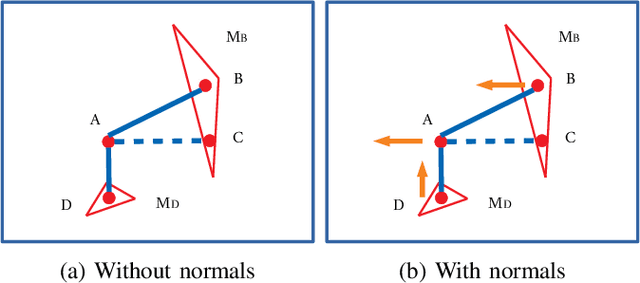
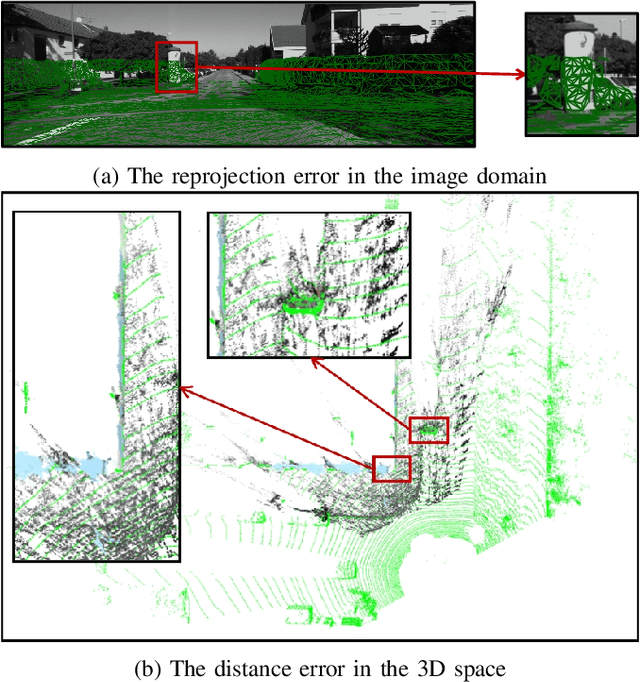
In this paper, we present TEScalib, a novel extrinsic self-calibration approach of LiDAR and stereo camera using the geometric and photometric information of surrounding environments without any calibration targets for automated driving vehicles. Since LiDAR and stereo camera are widely used for sensor data fusion on automated driving vehicles, their extrinsic calibration is highly important. However, most of the LiDAR and stereo camera calibration approaches are mainly target-based and therefore time consuming. Even the newly developed targetless approaches in last years are either inaccurate or unsuitable for driving platforms. To address those problems, we introduce TEScalib. By applying a 3D mesh reconstruction-based point cloud registration, the geometric information is used to estimate the LiDAR to stereo camera extrinsic parameters accurately and robustly. To calibrate the stereo camera, a photometric error function is builded and the LiDAR depth is involved to transform key points from one camera to another. During driving, these two parts are processed iteratively. Besides that, we also propose an uncertainty analysis for reflecting the reliability of the estimated extrinsic parameters. Our TEScalib approach evaluated on the KITTI dataset achieves very promising results.