 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Intersection-Aware 3D Human Motion Generation Using an Efficient Human Sphere Proxy
May 26, 2026Human motion generation has made tremendous progress in recent years, with state-of-the-art approaches surpassing ground truth data in leading evaluation benchmarks. However, visual inspection of the generated motions paints a different picture. Even state-of-the-art approaches generate motions frequently containing self-intersections, i.e., body parts interpenetrating, which are strong artifacts, severely limiting the perceived motion quality. We introduce a novel loss, which explicitly penalizes self-intersections, to the training of human motion generation methods. We base our loss on a sphere proxy of human geometry, which allows us to calculate a self-intersection loss 98% faster and uses 83% less memory than comparable methods based on triangular meshes. The loss is agnostic to the specific approach, and we add it to the training of the recent human motion generation methods human motion diffusion model (MDM) and MoMask. Our extensive experiments show a reduction of self-intersections in generated motions of up to 49% while improving other evaluation metrics. The code is available at https://github.com/boschresearch/humansphereproxy .
MULTI: Disentangling Camera Lens, Sensor, View, and Domain for Novel Image Generation
May 12, 2026Recent text-to-image models produce high-quality images, yet text ambiguity hinders precise control when specific styles or objects are required. There have been a number of recent works dealing with learning and composing multiple objects and patterns. However, current work focuses almost entirely on image content, overlooking imaging factors such as camera lens, sensor types, imaging viewpoints, and scenes' domain characteristics. We introduce this new challenge as Imaging Factor Disentanglement and show limitations of current approaches in the regime. We, therefore, propose the new method Multi-factor disentanglement through Textual Inversion (MULTI). It consists of two stages: in the first stage, we learn general factors, and in the second stage, we extract dataset-specific ones. This setup enables the extension of existing datasets and novel factor combinations, thereby reducing distribution gaps. It further supports modifications of specific factors and image-to-image generation via ControlNets. The evaluation on our new DF-RICO benchmark demonstrates the effectiveness of MULTI and highlights the importance of Factor Disentanglement as a new direction of research.
Incremental Object Detection with Prompt-based Methods
Aug 20, 2025Visual prompt-based methods have seen growing interest in incremental learning (IL) for image classification. These approaches learn additional embedding vectors while keeping the model frozen, making them efficient to train. However, no prior work has applied such methods to incremental object detection (IOD), leaving their generalizability unclear. In this paper, we analyze three different prompt-based methods under a complex domain-incremental learning setting. We additionally provide a wide range of reference baselines for comparison. Empirically, we show that the prompt-based approaches we tested underperform in this setting. However, a strong yet practical method, combining visual prompts with replaying a small portion of previous data, achieves the best results. Together with additional experiments on prompt length and initialization, our findings offer valuable insights for advancing prompt-based IL in IOD.
Criteria for Uncertainty-based Corner Cases Detection in Instance Segmentation
Apr 17, 2024The operating environment of a highly automated vehicle is subject to change, e.g., weather, illumination, or the scenario containing different objects and other participants in which the highly automated vehicle has to navigate its passengers safely. These situations must be considered when developing and validating highly automated driving functions. This already poses a problem for training and evaluating deep learning models because without the costly labeling of thousands of recordings, not knowing whether the data contains relevant, interesting data for further model training, it is a guess under which conditions and situations the model performs poorly. For this purpose, we present corner case criteria based on the predictive uncertainty. With our corner case criteria, we are able to detect uncertainty-based corner cases of an object instance segmentation model without relying on ground truth (GT) data. We evaluated each corner case criterion using the COCO and the NuImages dataset to analyze the potential of our approach. We also provide a corner case decision function that allows us to distinguish each object into True Positive (TP), localization and/or classification corner case, or False Positive (FP). We also present our first results of an iterative training cycle that outperforms the baseline and where the data added to the training dataset is selected based on the corner case decision function.
A Safety-Adapted Loss for Pedestrian Detection in Automated Driving
Feb 05, 2024In safety-critical domains like automated driving (AD), errors by the object detector may endanger pedestrians and other vulnerable road users (VRU). As common evaluation metrics are not an adequate safety indicator, recent works employ approaches to identify safety-critical VRU and back-annotate the risk to the object detector. However, those approaches do not consider the safety factor in the deep neural network (DNN) training process. Thus, state-of-the-art DNN penalizes all misdetections equally irrespective of their criticality. Subsequently, to mitigate the occurrence of critical failure cases, i.e., false negatives, a safety-aware training strategy might be required to enhance the detection performance for critical pedestrians. In this paper, we propose a novel safety-aware loss variation that leverages the estimated per-pedestrian criticality scores during training. We exploit the reachability set-based time-to-collision (TTC-RSB) metric from the motion domain along with distance information to account for the worst-case threat quantifying the criticality. Our evaluation results using RetinaNet and FCOS on the nuScenes dataset demonstrate that training the models with our safety-aware loss function mitigates the misdetection of critical pedestrians without sacrificing performance for the general case, i.e., pedestrians outside the safety-critical zone.
Space, Time, and Interaction: A Taxonomy of Corner Cases in Trajectory Datasets for Automated Driving
Oct 17, 2022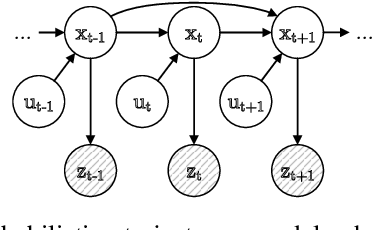
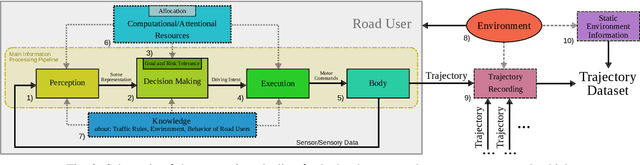
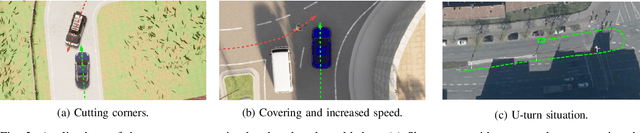
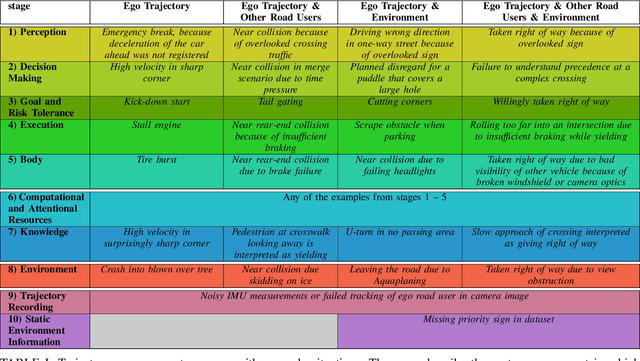
Trajectory data analysis is an essential component for highly automated driving. Complex models developed with these data predict other road users' movement and behavior patterns. Based on these predictions - and additional contextual information such as the course of the road, (traffic) rules, and interaction with other road users - the highly automated vehicle (HAV) must be able to reliably and safely perform the task assigned to it, e.g., moving from point A to B. Ideally, the HAV moves safely through its environment, just as we would expect a human driver to do. However, if unusual trajectories occur, so-called trajectory corner cases, a human driver can usually cope well, but an HAV can quickly get into trouble. In the definition of trajectory corner cases, which we provide in this work, we will consider the relevance of unusual trajectories with respect to the task at hand. Based on this, we will also present a taxonomy of different trajectory corner cases. The categorization of corner cases into the taxonomy will be shown with examples and is done by cause and required data sources. To illustrate the complexity between the machine learning (ML) model and the corner case cause, we present a general processing chain underlying the taxonomy.
Description of Corner Cases in Automated Driving: Goals and Challenges
Sep 28, 2021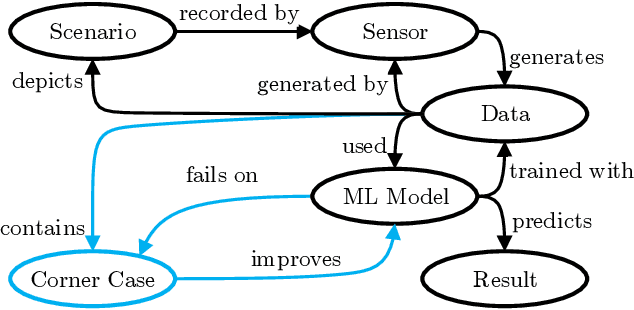


Scaling the distribution of automated vehicles requires handling various unexpected and possibly dangerous situations, termed corner cases (CC). Since many modules of automated driving systems are based on machine learning (ML), CC are an essential part of the data for their development. However, there is only a limited amount of CC data in large-scale data collections, which makes them challenging in the context of ML. With a better understanding of CC, offline applications, e.g., dataset analysis, and online methods, e.g., improved performance of automated driving systems, can be improved. While there are knowledge-based descriptions and taxonomies for CC, there is little research on machine-interpretable descriptions. In this extended abstract, we will give a brief overview of the challenges and goals of such a description.
Out-of-distribution Detection and Generation using Soft Brownian Offset Sampling and Autoencoders
May 04, 2021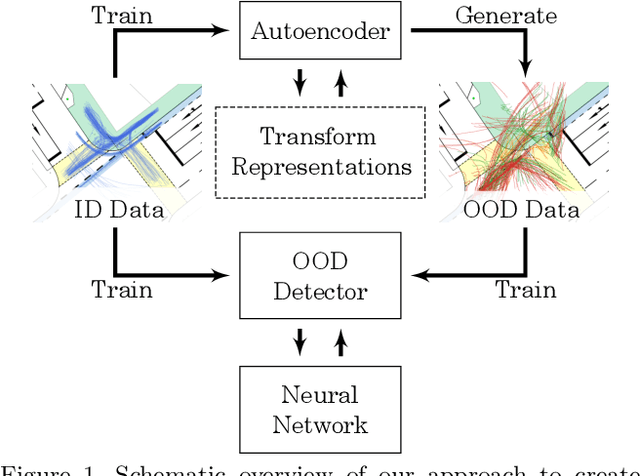
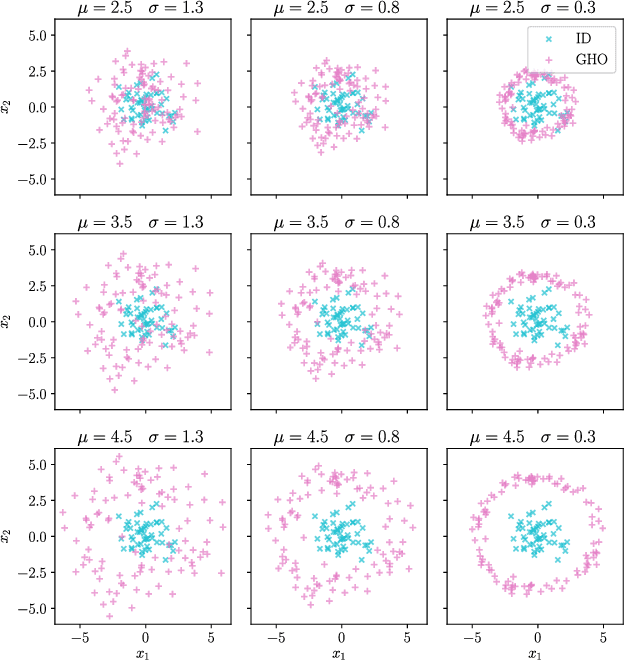
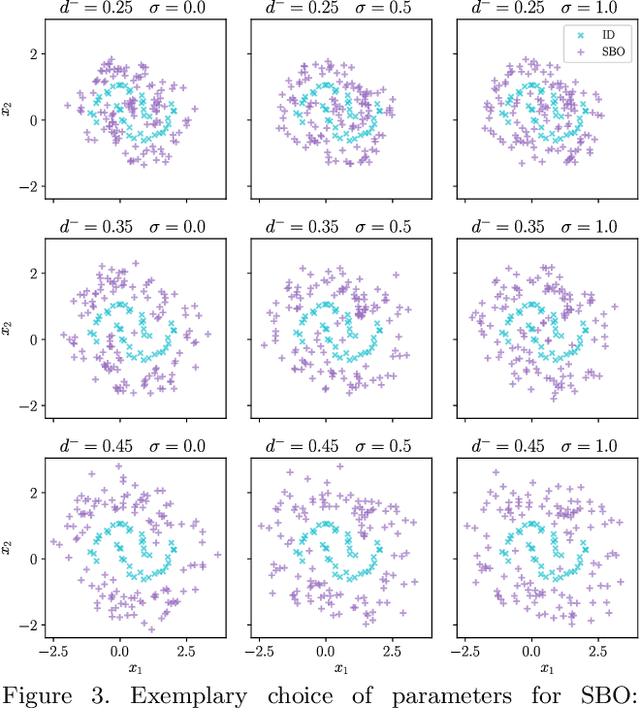
Deep neural networks often suffer from overconfidence which can be partly remedied by improved out-of-distribution detection. For this purpose, we propose a novel approach that allows for the generation of out-of-distribution datasets based on a given in-distribution dataset. This new dataset can then be used to improve out-of-distribution detection for the given dataset and machine learning task at hand. The samples in this dataset are with respect to the feature space close to the in-distribution dataset and therefore realistic and plausible. Hence, this dataset can also be used to safeguard neural networks, i.e., to validate the generalization performance. Our approach first generates suitable representations of an in-distribution dataset using an autoencoder and then transforms them using our novel proposed Soft Brownian Offset method. After transformation, the decoder part of the autoencoder allows for the generation of these implicit out-of-distribution samples. This newly generated dataset then allows for mixing with other datasets and thus improved training of an out-of-distribution classifier, increasing its performance. Experimentally, we show that our approach is promising for time series using synthetic data. Using our new method, we also show in a quantitative case study that we can improve the out-of-distribution detection for the MNIST dataset. Finally, we provide another case study on the synthetic generation of out-of-distribution trajectories, which can be used to validate trajectory prediction algorithms for automated driving.
An Application-Driven Conceptualization of Corner Cases for Perception in Highly Automated Driving
Mar 05, 2021
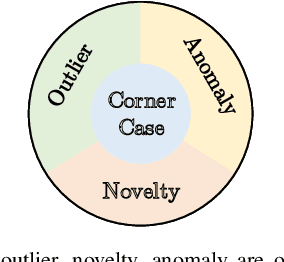
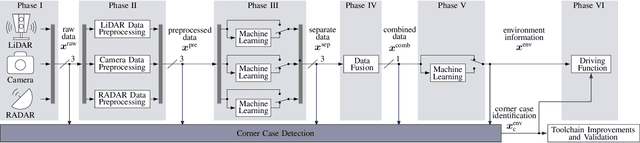
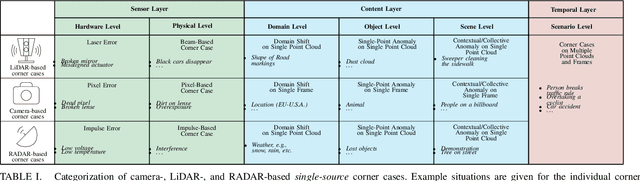
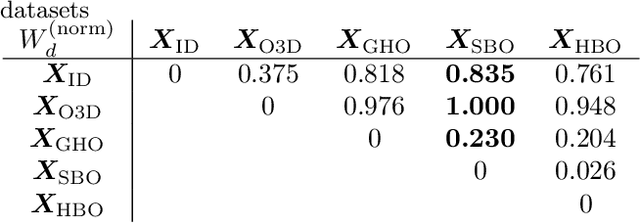
Systems and functions that rely on machine learning (ML) are the basis of highly automated driving. An essential task of such ML models is to reliably detect and interpret unusual, new, and potentially dangerous situations. The detection of those situations, which we refer to as corner cases, is highly relevant for successfully developing, applying, and validating automotive perception functions in future vehicles where multiple sensor modalities will be used. A complication for the development of corner case detectors is the lack of consistent definitions, terms, and corner case descriptions, especially when taking into account various automotive sensors. In this work, we provide an application-driven view of corner cases in highly automated driving. To achieve this goal, we first consider existing definitions from the general outlier, novelty, anomaly, and out-of-distribution detection to show relations and differences to corner cases. Moreover, we extend an existing camera-focused systematization of corner cases by adding RADAR (radio detection and ranging) and LiDAR (light detection and ranging) sensors. For this, we describe an exemplary toolchain for data acquisition and processing, highlighting the interfaces of the corner case detection. We also define a novel level of corner cases, the method layer corner cases, which appear due to uncertainty inherent in the methodology or the data distribution.
Quantile Surfaces -- Generalizing Quantile Regression to Multivariate Targets
Sep 29, 2020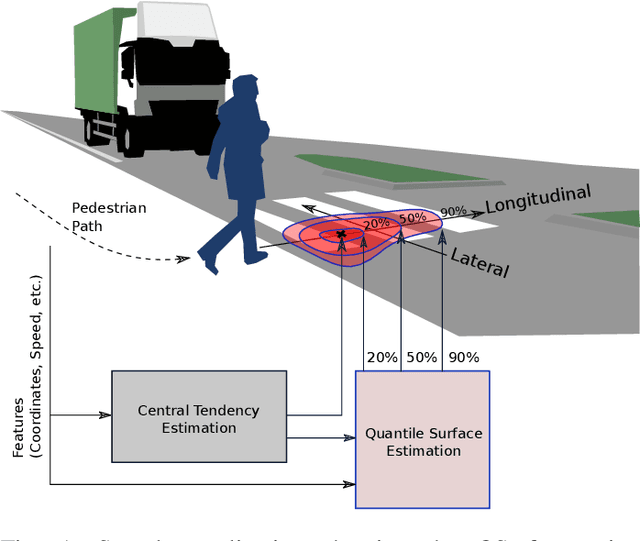
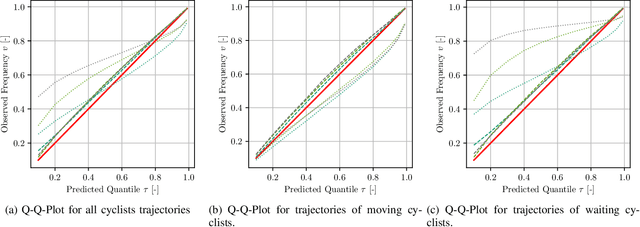
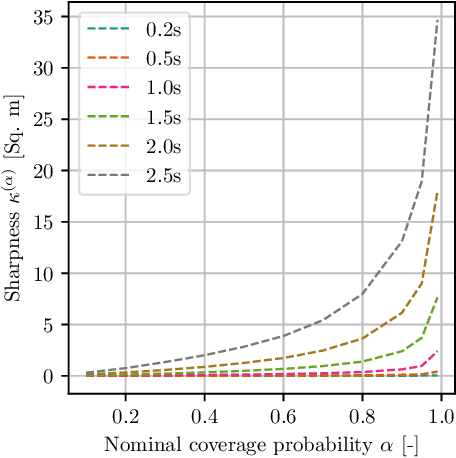
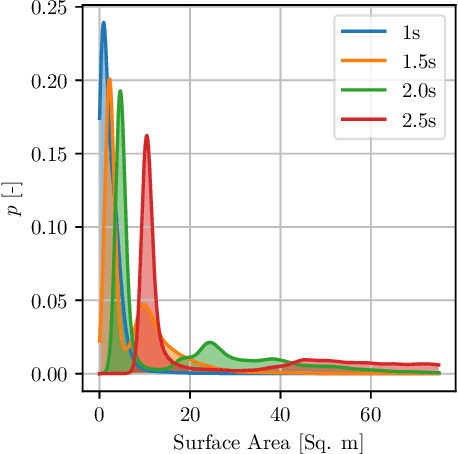
In this article, we present a novel approach to multivariate probabilistic forecasting. Our approach is based on an extension of single-output quantile regression (QR) to multivariate-targets, called quantile surfaces (QS). QS uses a simple yet compelling idea of indexing observations of a probabilistic forecast through direction and vector length to estimate a central tendency. We extend the single-output QR technique to multivariate probabilistic targets. QS efficiently models dependencies in multivariate target variables and represents probability distributions through discrete quantile levels. Therefore, we present a novel two-stage process. In the first stage, we perform a deterministic point forecast (i.e., central tendency estimation). Subsequently, we model the prediction uncertainty using QS involving neural networks called quantile surface regression neural networks (QSNN). Additionally, we introduce new methods for efficient and straightforward evaluation of the reliability and sharpness of the issued probabilistic QS predictions. We complement this by the directional extension of the Continuous Ranked Probability Score (CRPS) score. Finally, we evaluate our novel approach on synthetic data and two currently researched real-world challenges in two different domains: First, probabilistic forecasting for renewable energy power generation, second, short-term cyclists trajectory forecasting for autonomously driving vehicles. Especially for the latter, our empirical results show that even a simple one-layer QSNN outperforms traditional parametric multivariate forecasting techniques, thus improving the state-of-the-art performance.