 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
HUMOS: Human Motion Model Conditioned on Body Shape
Sep 05, 2024



Generating realistic human motion is essential for many computer vision and graphics applications. The wide variety of human body shapes and sizes greatly impacts how people move. However, most existing motion models ignore these differences, relying on a standardized, average body. This leads to uniform motion across different body types, where movements don't match their physical characteristics, limiting diversity. To solve this, we introduce a new approach to develop a generative motion model based on body shape. We show that it's possible to train this model using unpaired data by applying cycle consistency, intuitive physics, and stability constraints, which capture the relationship between identity and movement. The resulting model generates diverse, physically plausible, and dynamically stable human motions that are both quantitatively and qualitatively more realistic than current state-of-the-art methods. More details are available on our project page https://CarstenEpic.github.io/humos/.
fNeRF: High Quality Radiance Fields from Practical Cameras
Jun 15, 2024



In recent years, the development of Neural Radiance Fields has enabled a previously unseen level of photo-realistic 3D reconstruction of scenes and objects from multi-view camera data. However, previous methods use an oversimplified pinhole camera model resulting in defocus blur being `baked' into the reconstructed radiance field. We propose a modification to the ray casting that leverages the optics of lenses to enhance scene reconstruction in the presence of defocus blur. This allows us to improve the quality of radiance field reconstructions from the measurements of a practical camera with finite aperture. We show that the proposed model matches the defocus blur behavior of practical cameras more closely than pinhole models and other approximations of defocus blur models, particularly in the presence of partial occlusions. This allows us to achieve sharper reconstructions, improving the PSNR on validation of all-in-focus images, on both synthetic and real datasets, by up to 3 dB.
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes
Aug 16, 2023



Existing methods for the 4D reconstruction of general, non-rigidly deforming objects focus on novel-view synthesis and neglect correspondences. However, time consistency enables advanced downstream tasks like 3D editing, motion analysis, or virtual-asset creation. We propose SceNeRFlow to reconstruct a general, non-rigid scene in a time-consistent manner. Our dynamic-NeRF method takes multi-view RGB videos and background images from static cameras with known camera parameters as input. It then reconstructs the deformations of an estimated canonical model of the geometry and appearance in an online fashion. Since this canonical model is time-invariant, we obtain correspondences even for long-term, long-range motions. We employ neural scene representations to parametrize the components of our method. Like prior dynamic-NeRF methods, we use a backwards deformation model. We find non-trivial adaptations of this model necessary to handle larger motions: We decompose the deformations into a strongly regularized coarse component and a weakly regularized fine component, where the coarse component also extends the deformation field into the space surrounding the object, which enables tracking over time. We show experimentally that, unlike prior work that only handles small motion, our method enables the reconstruction of studio-scale motions.
Neural Lens Modeling
Apr 10, 2023



Recent methods for 3D reconstruction and rendering increasingly benefit from end-to-end optimization of the entire image formation process. However, this approach is currently limited: effects of the optical hardware stack and in particular lenses are hard to model in a unified way. This limits the quality that can be achieved for camera calibration and the fidelity of the results of 3D reconstruction. In this paper, we propose NeuroLens, a neural lens model for distortion and vignetting that can be used for point projection and ray casting and can be optimized through both operations. This means that it can (optionally) be used to perform pre-capture calibration using classical calibration targets, and can later be used to perform calibration or refinement during 3D reconstruction, e.g., while optimizing a radiance field. To evaluate the performance of our proposed model, we create a comprehensive dataset assembled from the Lensfun database with a multitude of lenses. Using this and other real-world datasets, we show that the quality of our proposed lens model outperforms standard packages as well as recent approaches while being much easier to use and extend. The model generalizes across many lens types and is trivial to integrate into existing 3D reconstruction and rendering systems.
Neural Assets: Volumetric Object Capture and Rendering for Interactive Environments
Dec 12, 2022



Creating realistic virtual assets is a time-consuming process: it usually involves an artist designing the object, then spending a lot of effort on tweaking its appearance. Intricate details and certain effects, such as subsurface scattering, elude representation using real-time BRDFs, making it impossible to fully capture the appearance of certain objects. Inspired by the recent progress of neural rendering, we propose an approach for capturing real-world objects in everyday environments faithfully and fast. We use a novel neural representation to reconstruct volumetric effects, such as translucent object parts, and preserve photorealistic object appearance. To support real-time rendering without compromising rendering quality, our model uses a grid of features and a small MLP decoder that is transpiled into efficient shader code with interactive framerates. This leads to a seamless integration of the proposed neural assets with existing mesh environments and objects. Thanks to the use of standard shader code rendering is portable across many existing hardware and software systems.
NeuWigs: A Neural Dynamic Model for Volumetric Hair Capture and Animation
Dec 08, 2022



The capture and animation of human hair are two of the major challenges in the creation of realistic avatars for the virtual reality. Both problems are highly challenging, because hair has complex geometry and appearance, as well as exhibits challenging motion. In this paper, we present a two-stage approach that models hair independently from the head to address these challenges in a data-driven manner. The first stage, state compression, learns a low-dimensional latent space of 3D hair states containing motion and appearance, via a novel autoencoder-as-a-tracker strategy. To better disentangle the hair and head in appearance learning, we employ multi-view hair segmentation masks in combination with a differentiable volumetric renderer. The second stage learns a novel hair dynamics model that performs temporal hair transfer based on the discovered latent codes. To enforce higher stability while driving our dynamics model, we employ the 3D point-cloud autoencoder from the compression stage for de-noising of the hair state. Our model outperforms the state of the art in novel view synthesis and is capable of creating novel hair animations without having to rely on hair observations as a driving signal. Project page is here https://ziyanw1.github.io/neuwigs/.
SSDNeRF: Semantic Soft Decomposition of Neural Radiance Fields
Dec 07, 2022



Neural Radiance Fields (NeRFs) encode the radiance in a scene parameterized by the scene's plenoptic function. This is achieved by using an MLP together with a mapping to a higher-dimensional space, and has been proven to capture scenes with a great level of detail. Naturally, the same parameterization can be used to encode additional properties of the scene, beyond just its radiance. A particularly interesting property in this regard is the semantic decomposition of the scene. We introduce a novel technique for semantic soft decomposition of neural radiance fields (named SSDNeRF) which jointly encodes semantic signals in combination with radiance signals of a scene. Our approach provides a soft decomposition of the scene into semantic parts, enabling us to correctly encode multiple semantic classes blending along the same direction -- an impossible feat for existing methods. Not only does this lead to a detailed, 3D semantic representation of the scene, but we also show that the regularizing effects of the MLP used for encoding help to improve the semantic representation. We show state-of-the-art segmentation and reconstruction results on a dataset of common objects and demonstrate how the proposed approach can be applied for high quality temporally consistent video editing and re-compositing on a dataset of casually captured selfie videos.
TAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022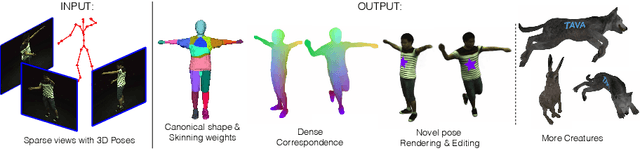

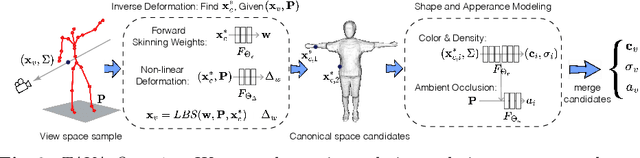
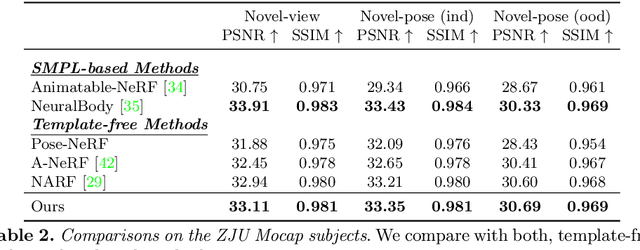
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.
Self-supervised Neural Articulated Shape and Appearance Models
May 17, 2022

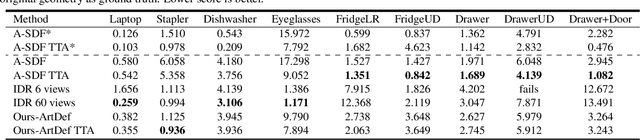

Learning geometry, motion, and appearance priors of object classes is important for the solution of a large variety of computer vision problems. While the majority of approaches has focused on static objects, dynamic objects, especially with controllable articulation, are less explored. We propose a novel approach for learning a representation of the geometry, appearance, and motion of a class of articulated objects given only a set of color images as input. In a self-supervised manner, our novel representation learns shape, appearance, and articulation codes that enable independent control of these semantic dimensions. Our model is trained end-to-end without requiring any articulation annotations. Experiments show that our approach performs well for different joint types, such as revolute and prismatic joints, as well as different combinations of these joints. Compared to state of the art that uses direct 3D supervision and does not output appearance, we recover more faithful geometry and appearance from 2D observations only. In addition, our representation enables a large variety of applications, such as few-shot reconstruction, the generation of novel articulations, and novel view-synthesis.