 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Fatigued Movements for Virtual Character Animation
Oct 12, 2023Virtual character animation and movement synthesis have advanced rapidly during recent years, especially through a combination of extensive motion capture datasets and machine learning. A remaining challenge is interactively simulating characters that fatigue when performing extended motions, which is indispensable for the realism of generated animations. However, capturing such movements is problematic, as performing movements like backflips with fatigued variations up to exhaustion raises capture cost and risk of injury. Surprisingly, little research has been done on faithful fatigue modeling. To address this, we propose a deep reinforcement learning-based approach, which -- for the first time in literature -- generates control policies for full-body physically simulated agents aware of cumulative fatigue. For this, we first leverage Generative Adversarial Imitation Learning (GAIL) to learn an expert policy for the skill; Second, we learn a fatigue policy by limiting the generated constant torque bounds based on endurance time to non-linear, state- and time-dependent limits in the joint-actuation space using a Three-Compartment Controller (3CC) model. Our results demonstrate that agents can adapt to different fatigue and rest rates interactively, and discover realistic recovery strategies without the need for any captured data of fatigued movement.
* 16 pages, 22 figures. To be published in ACM SIGGRAPH Asia Conference Papers 2023. ACM ISBN 979-8-4007-0315-7/23/12
State of the Art on Diffusion Models for Visual Computing
Oct 11, 2023The field of visual computing is rapidly advancing due to the emergence of generative artificial intelligence (AI), which unlocks unprecedented capabilities for the generation, editing, and reconstruction of images, videos, and 3D scenes. In these domains, diffusion models are the generative AI architecture of choice. Within the last year alone, the literature on diffusion-based tools and applications has seen exponential growth and relevant papers are published across the computer graphics, computer vision, and AI communities with new works appearing daily on arXiv. This rapid growth of the field makes it difficult to keep up with all recent developments. The goal of this state-of-the-art report (STAR) is to introduce the basic mathematical concepts of diffusion models, implementation details and design choices of the popular Stable Diffusion model, as well as overview important aspects of these generative AI tools, including personalization, conditioning, inversion, among others. Moreover, we give a comprehensive overview of the rapidly growing literature on diffusion-based generation and editing, categorized by the type of generated medium, including 2D images, videos, 3D objects, locomotion, and 4D scenes. Finally, we discuss available datasets, metrics, open challenges, and social implications. This STAR provides an intuitive starting point to explore this exciting topic for researchers, artists, and practitioners alike.
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
Sep 30, 2023



Inverse rendering, the process of inferring scene properties from images, is a challenging inverse problem. The task is ill-posed, as many different scene configurations can give rise to the same image. Most existing solutions incorporate priors into the inverse-rendering pipeline to encourage plausible solutions, but they do not consider the inherent ambiguities and the multi-modal distribution of possible decompositions. In this work, we propose a novel scheme that integrates a denoising diffusion probabilistic model pre-trained on natural illumination maps into an optimization framework involving a differentiable path tracer. The proposed method allows sampling from combinations of illumination and spatially-varying surface materials that are, both, natural and explain the image observations. We further conduct an extensive comparative study of different priors on illumination used in previous work on inverse rendering. Our method excels in recovering materials and producing highly realistic and diverse environment map samples that faithfully explain the illumination of the input images.
ROAM: Robust and Object-aware Motion Generation using Neural Pose Descriptors
Aug 24, 2023
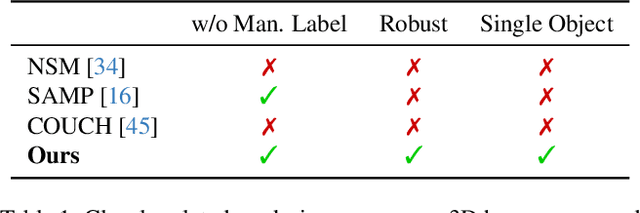
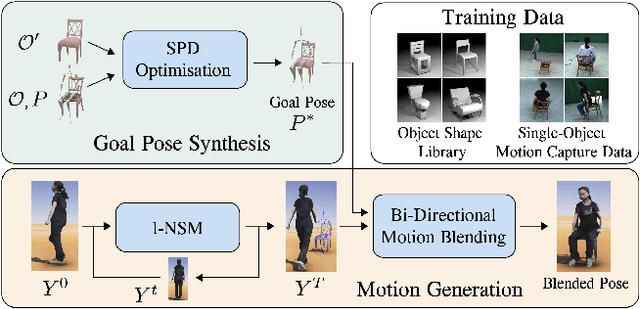

Existing automatic approaches for 3D virtual character motion synthesis supporting scene interactions do not generalise well to new objects outside training distributions, even when trained on extensive motion capture datasets with diverse objects and annotated interactions. This paper addresses this limitation and shows that robustness and generalisation to novel scene objects in 3D object-aware character synthesis can be achieved by training a motion model with as few as one reference object. We leverage an implicit feature representation trained on object-only datasets, which encodes an SE(3)-equivariant descriptor field around the object. Given an unseen object and a reference pose-object pair, we optimise for the object-aware pose that is closest in the feature space to the reference pose. Finally, we use l-NSM, i.e., our motion generation model that is trained to seamlessly transition from locomotion to object interaction with the proposed bidirectional pose blending scheme. Through comprehensive numerical comparisons to state-of-the-art methods and in a user study, we demonstrate substantial improvements in 3D virtual character motion and interaction quality and robustness to scenarios with unseen objects. Our project page is available at https://vcai.mpi-inf.mpg.de/projects/ROAM/.
NeuralClothSim: Neural Deformation Fields Meet the Kirchhoff-Love Thin Shell Theory
Aug 24, 2023



Cloth simulation is an extensively studied problem, with a plethora of solutions available in computer graphics literature. Existing cloth simulators produce realistic cloth deformations that obey different types of boundary conditions. Nevertheless, their operational principle remains limited in several ways: They operate on explicit surface representations with a fixed spatial resolution, perform a series of discretised updates (which bounds their temporal resolution), and require comparably large amounts of storage. Moreover, back-propagating gradients through the existing solvers is often not straightforward, which poses additional challenges when integrating them into modern neural architectures. In response to the limitations mentioned above, this paper takes a fundamentally different perspective on physically-plausible cloth simulation and re-thinks this long-standing problem: We propose NeuralClothSim, i.e., a new cloth simulation approach using thin shells, in which surface evolution is encoded in neural network weights. Our memory-efficient and differentiable solver operates on a new continuous coordinate-based representation of dynamic surfaces, i.e., neural deformation fields (NDFs); it supervises NDF evolution with the rules of the non-linear Kirchhoff-Love shell theory. NDFs are adaptive in the sense that they 1) allocate their capacity to the deformation details as the latter arise during the cloth evolution and 2) allow surface state queries at arbitrary spatial and temporal resolutions without retraining. We show how to train our NeuralClothSim solver while imposing hard boundary conditions and demonstrate multiple applications, such as material interpolation and simulation editing. The experimental results highlight the effectiveness of our formulation and its potential impact.
SceNeRFlow: Time-Consistent Reconstruction of General Dynamic Scenes
Aug 16, 2023



Existing methods for the 4D reconstruction of general, non-rigidly deforming objects focus on novel-view synthesis and neglect correspondences. However, time consistency enables advanced downstream tasks like 3D editing, motion analysis, or virtual-asset creation. We propose SceNeRFlow to reconstruct a general, non-rigid scene in a time-consistent manner. Our dynamic-NeRF method takes multi-view RGB videos and background images from static cameras with known camera parameters as input. It then reconstructs the deformations of an estimated canonical model of the geometry and appearance in an online fashion. Since this canonical model is time-invariant, we obtain correspondences even for long-term, long-range motions. We employ neural scene representations to parametrize the components of our method. Like prior dynamic-NeRF methods, we use a backwards deformation model. We find non-trivial adaptations of this model necessary to handle larger motions: We decompose the deformations into a strongly regularized coarse component and a weakly regularized fine component, where the coarse component also extends the deformation field into the space surrounding the object, which enables tracking over time. We show experimentally that, unlike prior work that only handles small motion, our method enables the reconstruction of studio-scale motions.
WaveNeRF: Wavelet-based Generalizable Neural Radiance Fields
Aug 09, 2023



Neural Radiance Field (NeRF) has shown impressive performance in novel view synthesis via implicit scene representation. However, it usually suffers from poor scalability as requiring densely sampled images for each new scene. Several studies have attempted to mitigate this problem by integrating Multi-View Stereo (MVS) technique into NeRF while they still entail a cumbersome fine-tuning process for new scenes. Notably, the rendering quality will drop severely without this fine-tuning process and the errors mainly appear around the high-frequency features. In the light of this observation, we design WaveNeRF, which integrates wavelet frequency decomposition into MVS and NeRF to achieve generalizable yet high-quality synthesis without any per-scene optimization. To preserve high-frequency information when generating 3D feature volumes, WaveNeRF builds Multi-View Stereo in the Wavelet domain by integrating the discrete wavelet transform into the classical cascade MVS, which disentangles high-frequency information explicitly. With that, disentangled frequency features can be injected into classic NeRF via a novel hybrid neural renderer to yield faithful high-frequency details, and an intuitive frequency-guided sampling strategy can be designed to suppress artifacts around high-frequency regions. Extensive experiments over three widely studied benchmarks show that WaveNeRF achieves superior generalizable radiance field modeling when only given three images as input.
VINECS: Video-based Neural Character Skinning
Jul 03, 2023



Rigging and skinning clothed human avatars is a challenging task and traditionally requires a lot of manual work and expertise. Recent methods addressing it either generalize across different characters or focus on capturing the dynamics of a single character observed under different pose configurations. However, the former methods typically predict solely static skinning weights, which perform poorly for highly articulated poses, and the latter ones either require dense 3D character scans in different poses or cannot generate an explicit mesh with vertex correspondence over time. To address these challenges, we propose a fully automated approach for creating a fully rigged character with pose-dependent skinning weights, which can be solely learned from multi-view video. Therefore, we first acquire a rigged template, which is then statically skinned. Next, a coordinate-based MLP learns a skinning weights field parameterized over the position in a canonical pose space and the respective pose. Moreover, we introduce our pose- and view-dependent appearance field allowing us to differentiably render and supervise the posed mesh using multi-view imagery. We show that our approach outperforms state-of-the-art while not relying on dense 4D scans.
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars
Jun 02, 2023

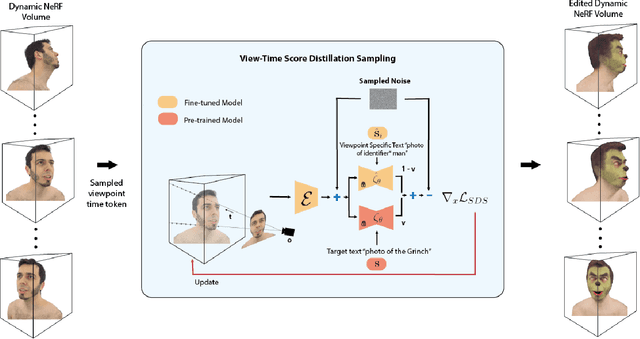
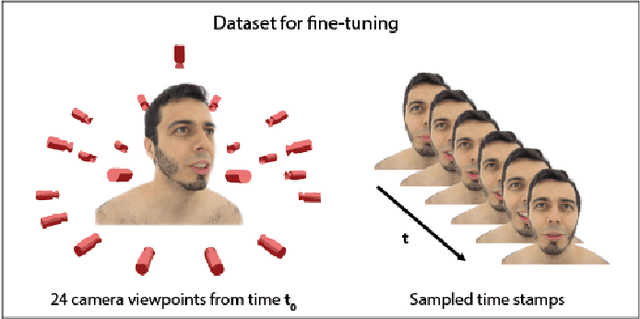
Capturing and editing full head performances enables the creation of virtual characters with various applications such as extended reality and media production. The past few years witnessed a steep rise in the photorealism of human head avatars. Such avatars can be controlled through different input data modalities, including RGB, audio, depth, IMUs and others. While these data modalities provide effective means of control, they mostly focus on editing the head movements such as the facial expressions, head pose and/or camera viewpoint. In this paper, we propose AvatarStudio, a text-based method for editing the appearance of a dynamic full head avatar. Our approach builds on existing work to capture dynamic performances of human heads using neural radiance field (NeRF) and edits this representation with a text-to-image diffusion model. Specifically, we introduce an optimization strategy for incorporating multiple keyframes representing different camera viewpoints and time stamps of a video performance into a single diffusion model. Using this personalized diffusion model, we edit the dynamic NeRF by introducing view-and-time-aware Score Distillation Sampling (VT-SDS) following a model-based guidance approach. Our method edits the full head in a canonical space, and then propagates these edits to remaining time steps via a pretrained deformation network. We evaluate our method visually and numerically via a user study, and results show that our method outperforms existing approaches. Our experiments validate the design choices of our method and highlight that our edits are genuine, personalized, as well as 3D- and time-consistent.
3D Open-vocabulary Segmentation with Foundation Models
May 24, 2023



Open-vocabulary segmentation of 3D scenes is a fundamental function of human perception and thus a crucial objective in computer vision research. However, this task is heavily impeded by the lack of large-scale and diverse 3D open-vocabulary segmentation datasets for training robust and generalizable models. Distilling knowledge from pre-trained 2D open-vocabulary segmentation models helps but it compromises the open-vocabulary feature significantly as the 2D models are mostly finetuned with close-vocabulary datasets. We tackle the challenges in 3D open-vocabulary segmentation by exploiting the open-vocabulary multimodal knowledge and object reasoning capability of pre-trained foundation models CLIP and DINO, without necessitating any fine-tuning. Specifically, we distill open-vocabulary visual and textual knowledge from CLIP into a neural radiance field (NeRF) which effectively lifts 2D features into view-consistent 3D segmentation. Furthermore, we introduce the Relevancy-Distribution Alignment loss and Feature-Distribution Alignment loss to respectively mitigate the ambiguities of CLIP features and distill precise object boundaries from DINO features, eliminating the need for segmentation annotations during training. Extensive experiments show that our method even outperforms fully supervised models trained with segmentation annotations, suggesting that 3D open-vocabulary segmentation can be effectively learned from 2D images and text-image pairs.