 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquity through Access: A Case for Small-scale Deep Learning
Mar 19, 2024



The recent advances in deep learning (DL) have been accelerated by access to large-scale data and compute. These large-scale resources have been used to train progressively larger models which are resource intensive in terms of compute, data, energy, and carbon emissions. These costs are becoming a new type of entry barrier to researchers and practitioners with limited access to resources at such scale, particularly in the Global South. In this work, we take a comprehensive look at the landscape of existing DL models for vision tasks and demonstrate their usefulness in settings where resources are limited. To account for the resource consumption of DL models, we introduce a novel measure to estimate the performance per resource unit, which we call the PePR score. Using a diverse family of 131 unique DL architectures (spanning 1M to 130M trainable parameters) and three medical image datasets, we capture trends about the performance-resource trade-offs. In applications like medical image analysis, we argue that small-scale, specialized models are better than striving for large-scale models. Furthermore, we show that using pretrained models can significantly reduce the computational resources and data required. We hope this work will encourage the community to focus on improving AI equity by developing methods and models with smaller resource footprints.
Tree Counting by Bridging 3D Point Clouds with Imagery
Mar 12, 2024



Accurate and consistent methods for counting trees based on remote sensing data are needed to support sustainable forest management, assess climate change mitigation strategies, and build trust in tree carbon credits. Two-dimensional remote sensing imagery primarily shows overstory canopy, and it does not facilitate easy differentiation of individual trees in areas with a dense canopy and does not allow for easy separation of trees when the canopy is dense. We leverage the fusion of three-dimensional LiDAR measurements and 2D imagery to facilitate the accurate counting of trees. We compare a deep learning approach to counting trees in forests using 3D airborne LiDAR data and 2D imagery. The approach is compared with state-of-the-art algorithms, like operating on 3D point cloud and 2D imagery. We empirically evaluate the different methods on the NeonTreeCount data set, which we use to define a tree-counting benchmark. The experiments show that FuseCountNet yields more accurate tree counts.
Predicting urban tree cover from incomplete point labels and limited background information
Nov 20, 2023



Trees inside cities are important for the urban microclimate, contributing positively to the physical and mental health of the urban dwellers. Despite their importance, often only limited information about city trees is available. Therefore in this paper, we propose a method for mapping urban trees in high-resolution aerial imagery using limited datasets and deep learning. Deep learning has become best-practice for this task, however, existing approaches rely on large and accurately labelled training datasets, which can be difficult and expensive to obtain. However, often noisy and incomplete data may be available that can be combined and utilized to solve more difficult tasks than those datasets were intended for. This paper studies how to combine accurate point labels of urban trees along streets with crowd-sourced annotations from an open geographic database to delineate city trees in remote sensing images, a task which is challenging even for humans. To that end, we perform semantic segmentation of very high resolution aerial imagery using a fully convolutional neural network. The main challenge is that our segmentation maps are sparsely annotated and incomplete. Small areas around the point labels of the street trees coming from official and crowd-sourced data are marked as foreground class. Crowd-sourced annotations of streets, buildings, etc. define the background class. Since the tree data is incomplete, we introduce a masking to avoid class confusion. Our experiments in Hamburg, Germany, showed that the system is able to produce tree cover maps, not limited to trees along streets, without providing tree delineations. We evaluated the method on manually labelled trees and show that performance drastically deteriorates if the open geographic database is not used.
Benchmarking Individual Tree Mapping with Sub-meter Imagery
Nov 14, 2023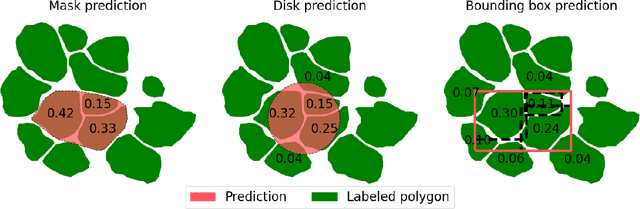



There is a rising interest in mapping trees using satellite or aerial imagery, but there is no standardized evaluation protocol for comparing and enhancing methods. In dense canopy areas, the high variability of tree sizes and their spatial proximity makes it arduous to define the quality of the predictions. Concurrently, object-centric approaches such as bounding box detection usuallyperform poorly on small and dense objects. It thus remains unclear what is the ideal framework for individual tree mapping, in regards to detection and segmentation approaches, convolutional neural networks and transformers. In this paper, we introduce an evaluation framework suited for individual tree mapping in any physical environment, with annotation costs and applicative goals in mind. We review and compare different approaches and deep architectures, and introduce a new method that we experimentally prove to be a good compromise between segmentation and detection.
Familiarity-Based Open-Set Recognition Under Adversarial Attacks
Nov 08, 2023Open-set recognition (OSR), the identification of novel categories, can be a critical component when deploying classification models in real-world applications. Recent work has shown that familiarity-based scoring rules such as the Maximum Softmax Probability (MSP) or the Maximum Logit Score (MLS) are strong baselines when the closed-set accuracy is high. However, one of the potential weaknesses of familiarity-based OSR are adversarial attacks. Here, we present gradient-based adversarial attacks on familiarity scores for both types of attacks, False Familiarity and False Novelty attacks, and evaluate their effectiveness in informed and uninformed settings on TinyImageNet.
Efficiency is Not Enough: A Critical Perspective of Environmentally Sustainable AI
Sep 05, 2023



Artificial Intelligence (AI) is currently spearheaded by machine learning (ML) methods such as deep learning (DL) which have accelerated progress on many tasks thought to be out of reach of AI. These ML methods can often be compute hungry, energy intensive, and result in significant carbon emissions, a known driver of anthropogenic climate change. Additionally, the platforms on which ML systems run are associated with environmental impacts including and beyond carbon emissions. The solution lionized by both industry and the ML community to improve the environmental sustainability of ML is to increase the efficiency with which ML systems operate in terms of both compute and energy consumption. In this perspective, we argue that efficiency alone is not enough to make ML as a technology environmentally sustainable. We do so by presenting three high level discrepancies between the effect of efficiency on the environmental sustainability of ML when considering the many variables which it interacts with. In doing so, we comprehensively demonstrate, at multiple levels of granularity both technical and non-technical reasons, why efficiency is not enough to fully remedy the environmental impacts of ML. Based on this, we present and argue for systems thinking as a viable path towards improving the environmental sustainability of ML holistically.
Smooth Monotonic Networks
Jun 01, 2023Monotonicity constraints are powerful regularizers in statistical modelling. They can support fairness in computer supported decision making and increase plausibility in data-driven scientific models. The seminal min-max (MM) neural network architecture ensures monotonicity, but often gets stuck in undesired local optima during training because of vanishing gradients. We propose a simple modification of the MM network using strictly-increasing smooth non-linearities that alleviates this problem. The resulting smooth min-max (SMM) network module inherits the asymptotic approximation properties from the MM architecture. It can be used within larger deep learning systems trained end-to-end. The SMM module is considerably simpler and less computationally demanding than state-of-the-art neural networks for monotonic modelling. Still, in our experiments, it compared favorably to alternative neural and non-neural approaches in terms of generalization performance.
BuildSeg: A General Framework for the Segmentation of Buildings
Jan 15, 2023

Building segmentation from aerial images and 3D laser scanning (LiDAR) is a challenging task due to the diversity of backgrounds, building textures, and image quality. While current research using different types of convolutional and transformer networks has considerably improved the performance on this task, even more accurate segmentation methods for buildings are desirable for applications such as automatic mapping. In this study, we propose a general framework termed \emph{BuildSeg} employing a generic approach that can be quickly applied to segment buildings. Different data sources were combined to increase generalization performance. The approach yields good results for different data sources as shown by experiments on high-resolution multi-spectral and LiDAR imagery of cities in Norway, Denmark and France. We applied ConvNeXt and SegFormer based models on the high resolution aerial image dataset from the MapAI-competition. The methods achieved an IOU of 0.7902 and a boundary IOU of 0.6185. We used post-processing to account for the rectangular shape of the objects. This increased the boundary IOU from 0.6185 to 0.6189.
LR-CSNet: Low-Rank Deep Unfolding Network for Image Compressive Sensing
Dec 18, 2022



Deep unfolding networks (DUNs) have proven to be a viable approach to compressive sensing (CS). In this work, we propose a DUN called low-rank CS network (LR-CSNet) for natural image CS. Real-world image patches are often well-represented by low-rank approximations. LR-CSNet exploits this property by adding a low-rank prior to the CS optimization task. We derive a corresponding iterative optimization procedure using variable splitting, which is then translated to a new DUN architecture. The architecture uses low-rank generation modules (LRGMs), which learn low-rank matrix factorizations, as well as gradient descent and proximal mappings (GDPMs), which are proposed to extract high-frequency features to refine image details. In addition, the deep features generated at each reconstruction stage in the DUN are transferred between stages to boost the performance. Our extensive experiments on three widely considered datasets demonstrate the promising performance of LR-CSNet compared to state-of-the-art methods in natural image CS.
Mask-FPAN: Semi-Supervised Face Parsing in the Wild With De-Occlusion and UV GAN
Dec 18, 2022



Fine-grained semantic segmentation of a person's face and head, including facial parts and head components, has progressed a great deal in recent years. However, it remains a challenging task, whereby considering ambiguous occlusions and large pose variations are particularly difficult. To overcome these difficulties, we propose a novel framework termed Mask-FPAN. It uses a de-occlusion module that learns to parse occluded faces in a semi-supervised way. In particular, face landmark localization, face occlusionstimations, and detected head poses are taken into account. A 3D morphable face model combined with the UV GAN improves the robustness of 2D face parsing. In addition, we introduce two new datasets named FaceOccMask-HQ and CelebAMaskOcc-HQ for face paring work. The proposed Mask-FPAN framework addresses the face parsing problem in the wild and shows significant performance improvements with MIOU from 0.7353 to 0.9013 compared to the state-of-the-art on challenging face datasets.