 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Standardization of Data Licenses: The Montreal Data License
Mar 21, 2019This paper provides a taxonomy for the licensing of data in the fields of artificial intelligence and machine learning. The paper's goal is to build towards a common framework for data licensing akin to the licensing of open source software. Increased transparency and resolving conceptual ambiguities in existing licensing language are two noted benefits of the approach proposed in the paper. In parallel, such benefits may help foster fairer and more efficient markets for data through bringing about clearer tools and concepts that better define how data can be used in the fields of AI and ML. The paper's approach is summarized in a new family of data license language - \textit{the Montreal Data License (MDL)}. Alongside this new license, the authors and their collaborators have developed a web-based tool to generate license language espousing the taxonomies articulated in this paper.
The Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019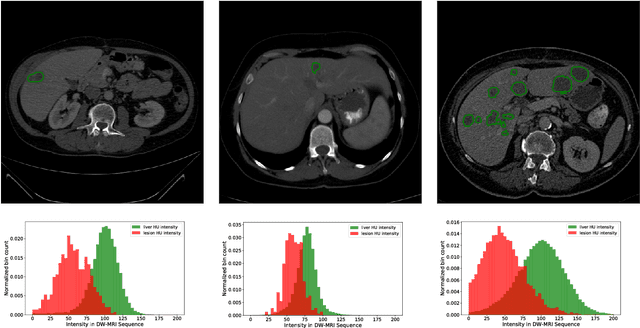

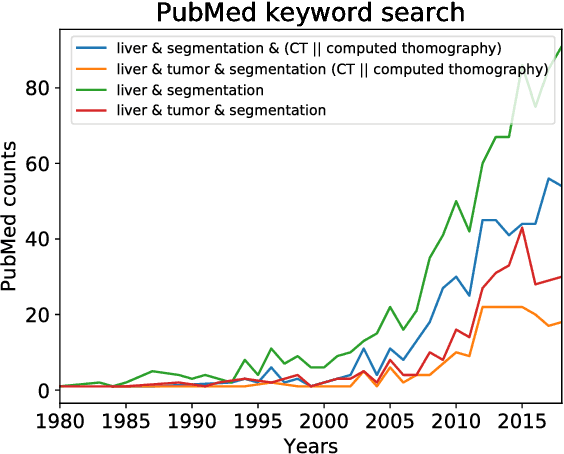

In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.
Towards Deep Conversational Recommendations
Dec 18, 2018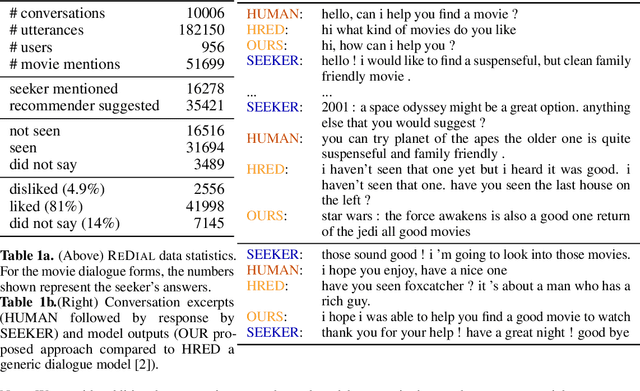
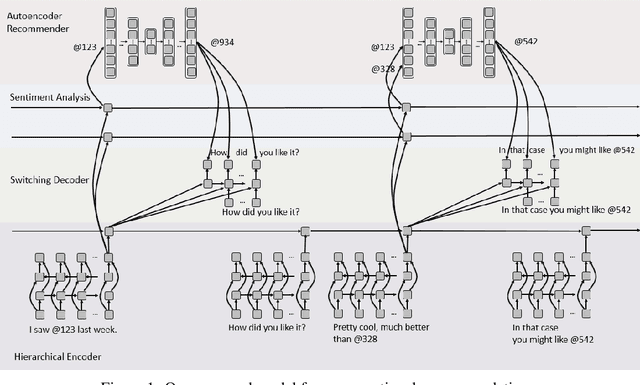


There has been growing interest in using neural networks and deep learning techniques to create dialogue systems. Conversational recommendation is an interesting setting for the scientific exploration of dialogue with natural language as the associated discourse involves goal-driven dialogue that often transforms naturally into more free-form chat. This paper provides two contributions. First, until now there has been no publicly available large-scale dataset consisting of real-world dialogues centered around recommendations. To address this issue and to facilitate our exploration here, we have collected ReDial, a dataset consisting of over 10,000 conversations centered around the theme of providing movie recommendations. We make this data available to the community for further research. Second, we use this dataset to explore multiple facets of conversational recommendations. In particular we explore new neural architectures, mechanisms, and methods suitable for composing conversational recommendation systems. Our dataset allows us to systematically probe model sub-components addressing different parts of the overall problem domain ranging from: sentiment analysis and cold-start recommendation generation to detailed aspects of how natural language is used in this setting in the real world. We combine such sub-components into a full-blown dialogue system and examine its behavior.
A Survey of Mobile Computing for the Visually Impaired
Nov 27, 2018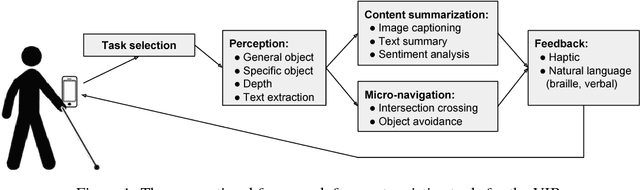
The number of visually impaired or blind (VIB) people in the world is estimated at several hundred million. Based on a series of interviews with the VIB and developers of assistive technology, this paper provides a survey of machine-learning based mobile applications and identifies the most relevant applications. We discuss the functionality of these apps, how they align with the needs and requirements of the VIB users, and how they can be improved with techniques such as federated learning and model compression. As a result of this study we identify promising future directions of research in mobile perception, micro-navigation, and content-summarization.
Sparse Attentive Backtracking: Temporal CreditAssignment Through Reminding
Sep 11, 2018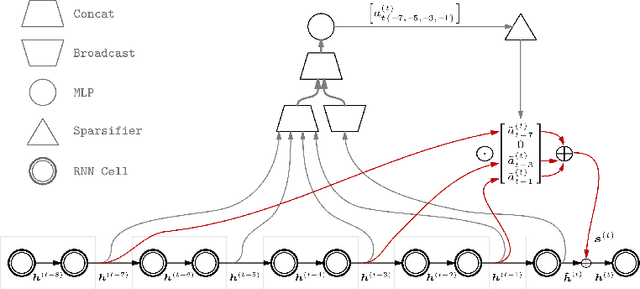

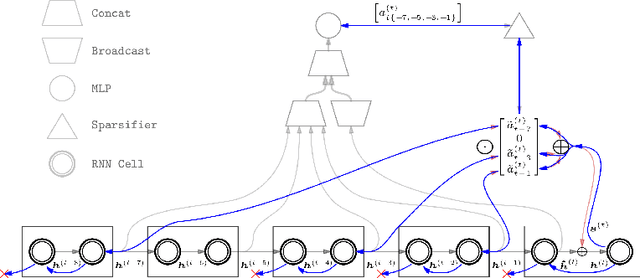
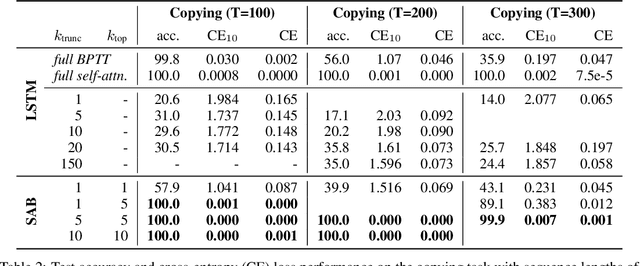
Learning long-term dependencies in extended temporal sequences requires credit assignment to events far back in the past. The most common method for training recurrent neural networks, back-propagation through time (BPTT), requires credit information to be propagated backwards through every single step of the forward computation, potentially over thousands or millions of time steps. This becomes computationally expensive or even infeasible when used with long sequences. Importantly, biological brains are unlikely to perform such detailed reverse replay over very long sequences of internal states (consider days, months, or years.) However, humans are often reminded of past memories or mental states which are associated with the current mental state. We consider the hypothesis that such memory associations between past and present could be used for credit assignment through arbitrarily long sequences, propagating the credit assigned to the current state to the associated past state. Based on this principle, we study a novel algorithm which only back-propagates through a few of these temporal skip connections, realized by a learned attention mechanism that associates current states with relevant past states. We demonstrate in experiments that our method matches or outperforms regular BPTT and truncated BPTT in tasks involving particularly long-term dependencies, but without requiring the biologically implausible backward replay through the whole history of states. Additionally, we demonstrate that the proposed method transfers to longer sequences significantly better than LSTMs trained with BPTT and LSTMs trained with full self-attention.
Liver lesion segmentation informed by joint liver segmentation
Aug 11, 2018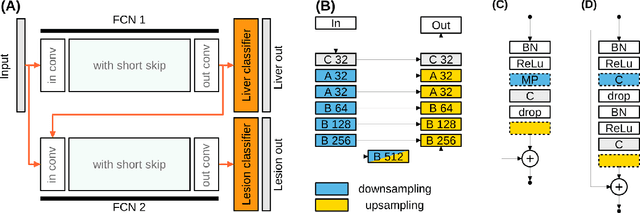
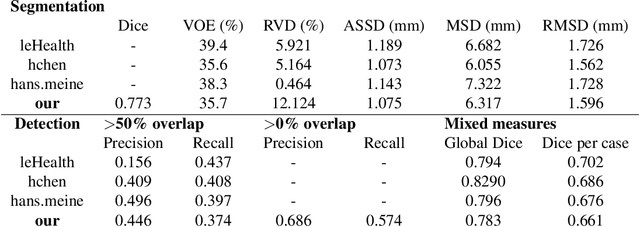
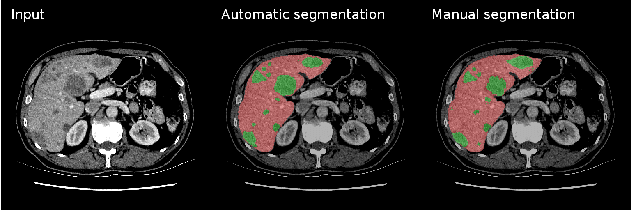
We propose a model for the joint segmentation of the liver and liver lesions in computed tomography (CT) volumes. We build the model from two fully convolutional networks, connected in tandem and trained together end-to-end. We evaluate our approach on the 2017 MICCAI Liver Tumour Segmentation Challenge, attaining competitive liver and liver lesion detection and segmentation scores across a wide range of metrics. Unlike other top performing methods, our model output post-processing is trivial, we do not use data external to the challenge, and we propose a simple single-stage model that is trained end-to-end. However, our method nearly matches the top lesion segmentation performance and achieves the second highest precision for lesion detection while maintaining high recall.
Fashion-Gen: The Generative Fashion Dataset and Challenge
Jul 30, 2018

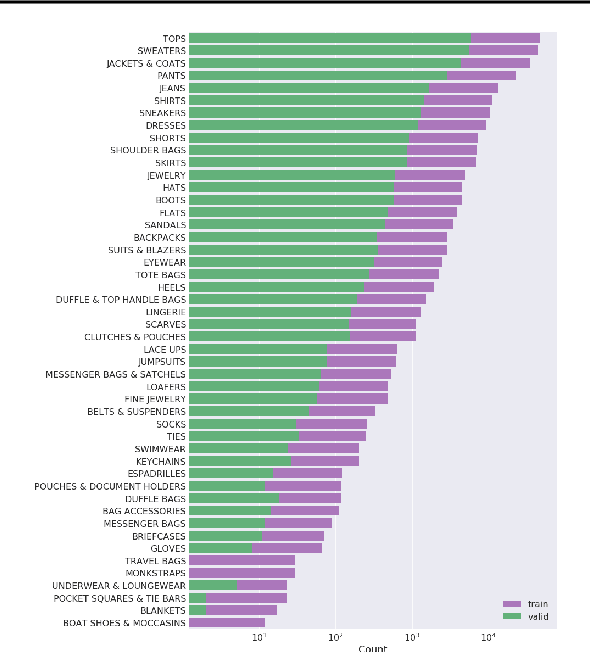

We introduce a new dataset of 293,008 high definition (1360 x 1360 pixels) fashion images paired with item descriptions provided by professional stylists. Each item is photographed from a variety of angles. We provide baseline results on 1) high-resolution image generation, and 2) image generation conditioned on the given text descriptions. We invite the community to improve upon these baselines. In this paper, we also outline the details of a challenge that we are launching based upon this dataset.
Focused Hierarchical RNNs for Conditional Sequence Processing
Jun 12, 2018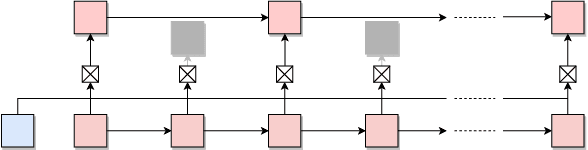
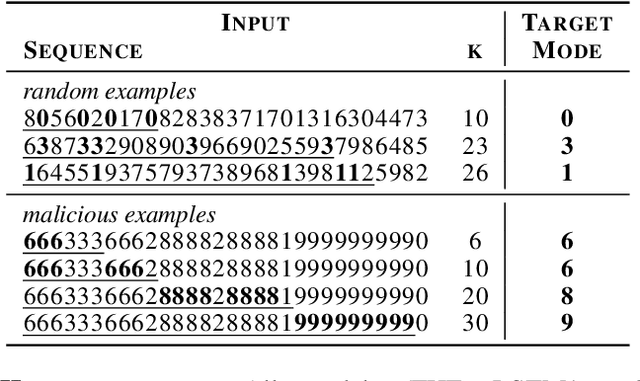
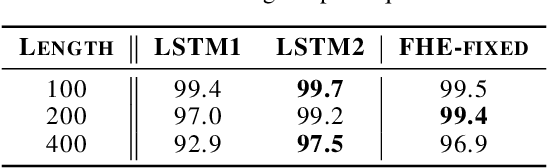
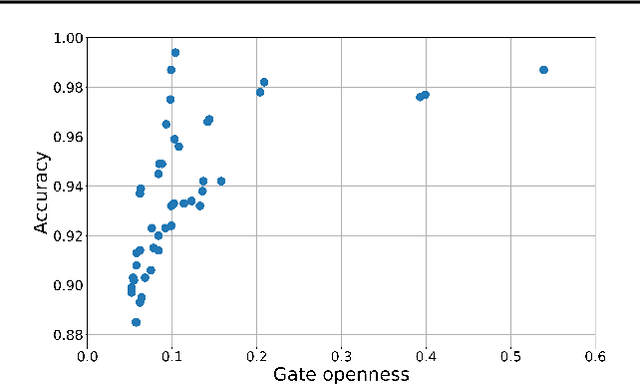
Recurrent Neural Networks (RNNs) with attention mechanisms have obtained state-of-the-art results for many sequence processing tasks. Most of these models use a simple form of encoder with attention that looks over the entire sequence and assigns a weight to each token independently. We present a mechanism for focusing RNN encoders for sequence modelling tasks which allows them to attend to key parts of the input as needed. We formulate this using a multi-layer conditional sequence encoder that reads in one token at a time and makes a discrete decision on whether the token is relevant to the context or question being asked. The discrete gating mechanism takes in the context embedding and the current hidden state as inputs and controls information flow into the layer above. We train it using policy gradient methods. We evaluate this method on several types of tasks with different attributes. First, we evaluate the method on synthetic tasks which allow us to evaluate the model for its generalization ability and probe the behavior of the gates in more controlled settings. We then evaluate this approach on large scale Question Answering tasks including the challenging MS MARCO and SearchQA tasks. Our models shows consistent improvements for both tasks over prior work and our baselines. It has also shown to generalize significantly better on synthetic tasks as compared to the baselines.
Twin Networks: Matching the Future for Sequence Generation
Feb 23, 2018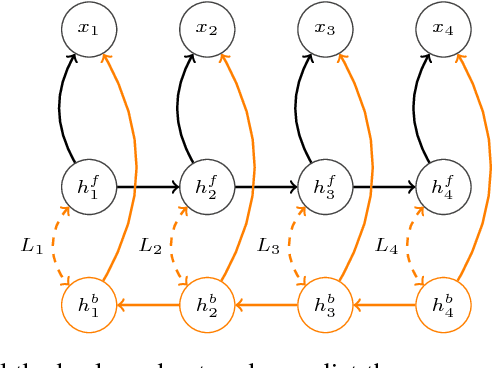

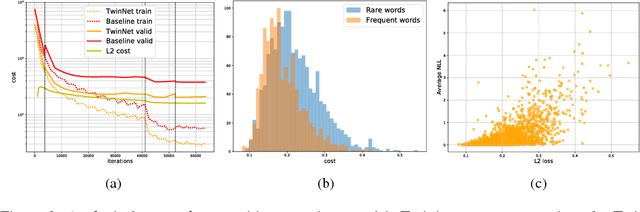
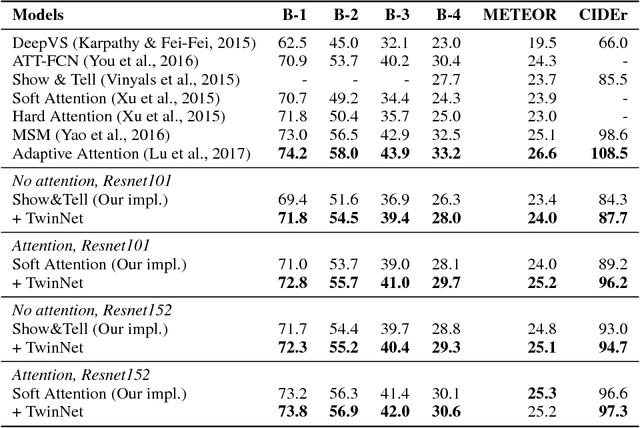
We propose a simple technique for encouraging generative RNNs to plan ahead. We train a "backward" recurrent network to generate a given sequence in reverse order, and we encourage states of the forward model to predict cotemporal states of the backward model. The backward network is used only during training, and plays no role during sampling or inference. We hypothesize that our approach eases modeling of long-term dependencies by implicitly forcing the forward states to hold information about the longer-term future (as contained in the backward states). We show empirically that our approach achieves 9% relative improvement for a speech recognition task, and achieves significant improvement on a COCO caption generation task.
ACtuAL: Actor-Critic Under Adversarial Learning
Nov 13, 2017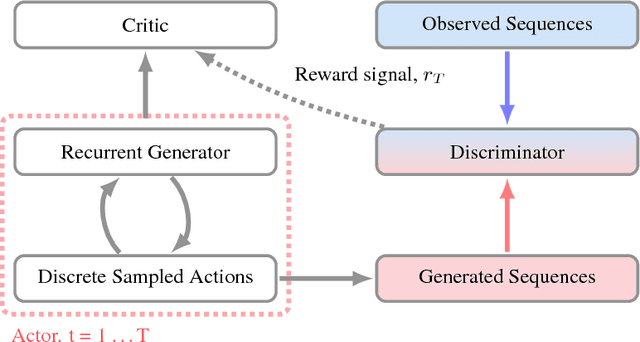
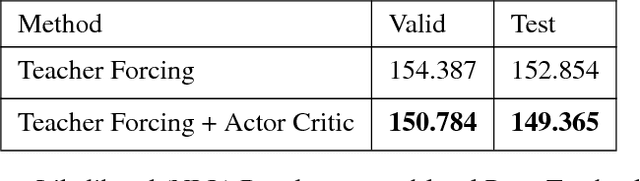
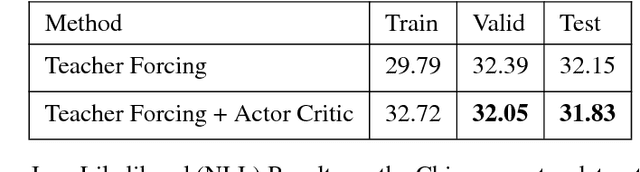

Generative Adversarial Networks (GANs) are a powerful framework for deep generative modeling. Posed as a two-player minimax problem, GANs are typically trained end-to-end on real-valued data and can be used to train a generator of high-dimensional and realistic images. However, a major limitation of GANs is that training relies on passing gradients from the discriminator through the generator via back-propagation. This makes it fundamentally difficult to train GANs with discrete data, as generation in this case typically involves a non-differentiable function. These difficulties extend to the reinforcement learning setting when the action space is composed of discrete decisions. We address these issues by reframing the GAN framework so that the generator is no longer trained using gradients through the discriminator, but is instead trained using a learned critic in the actor-critic framework with a Temporal Difference (TD) objective. This is a natural fit for sequence modeling and we use it to achieve improvements on language modeling tasks over the standard Teacher-Forcing methods.