 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion-Gen: The Generative Fashion Dataset and Challenge
Jul 30, 2018

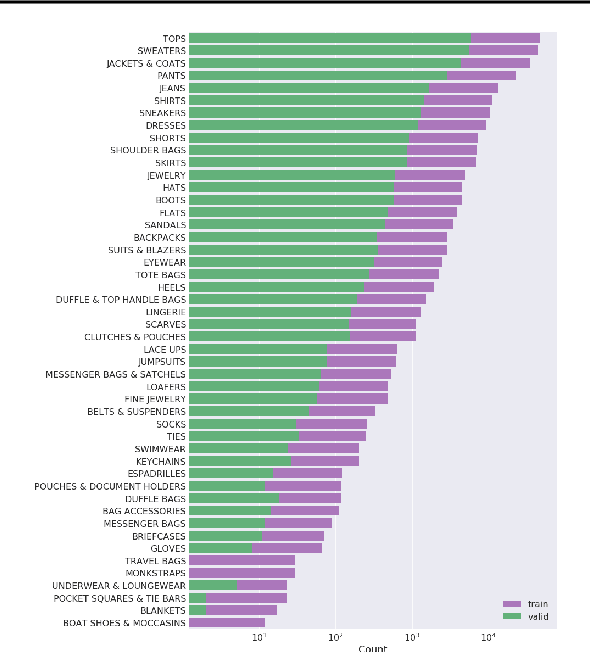

We introduce a new dataset of 293,008 high definition (1360 x 1360 pixels) fashion images paired with item descriptions provided by professional stylists. Each item is photographed from a variety of angles. We provide baseline results on 1) high-resolution image generation, and 2) image generation conditioned on the given text descriptions. We invite the community to improve upon these baselines. In this paper, we also outline the details of a challenge that we are launching based upon this dataset.
Commonsense mining as knowledge base completion? A study on the impact of novelty
Apr 24, 2018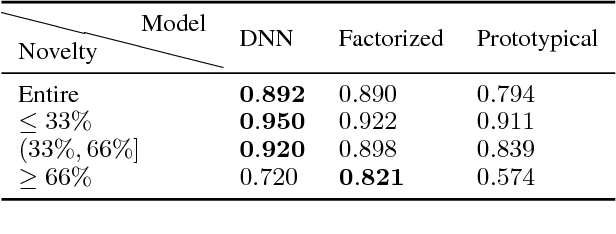
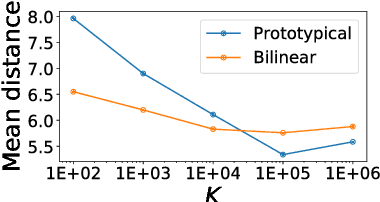


Commonsense knowledge bases such as ConceptNet represent knowledge in the form of relational triples. Inspired by the recent work by Li et al., we analyse if knowledge base completion models can be used to mine commonsense knowledge from raw text. We propose novelty of predicted triples with respect to the training set as an important factor in interpreting results. We critically analyse the difficulty of mining novel commonsense knowledge, and show that a simple baseline method outperforms the previous state of the art on predicting more novel.