 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
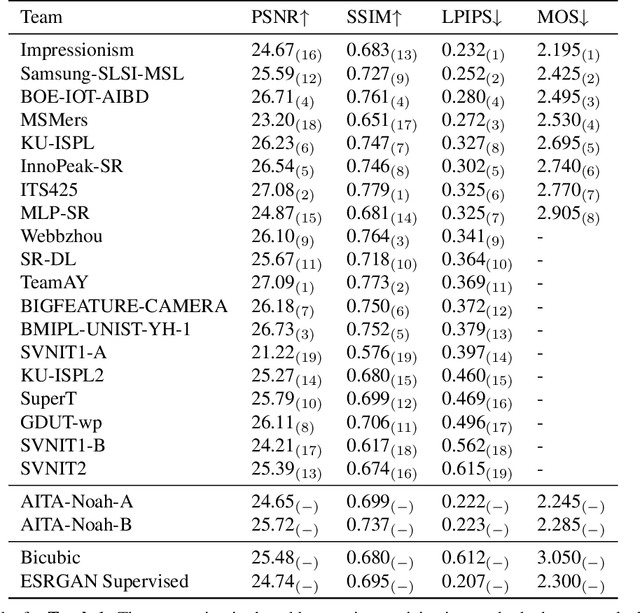
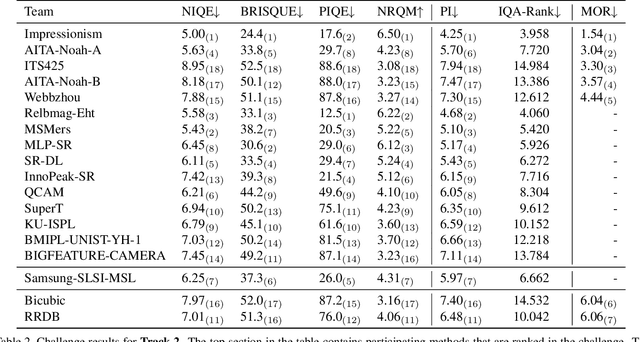

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Residual Channel Attention Generative Adversarial Network for Image Super-Resolution and Noise Reduction
Apr 28, 2020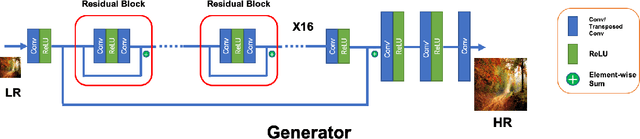
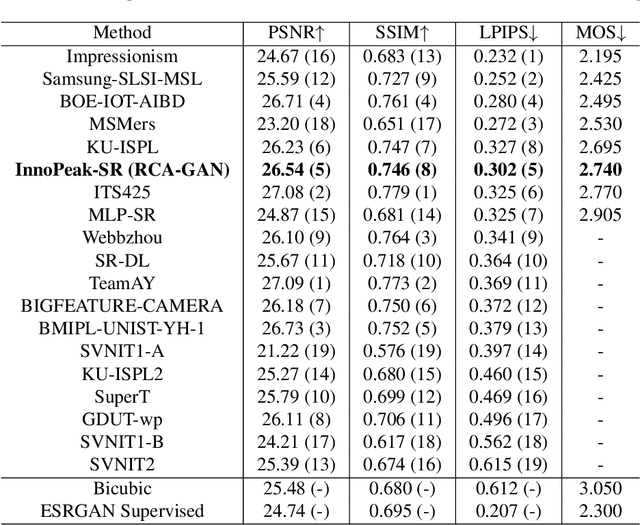
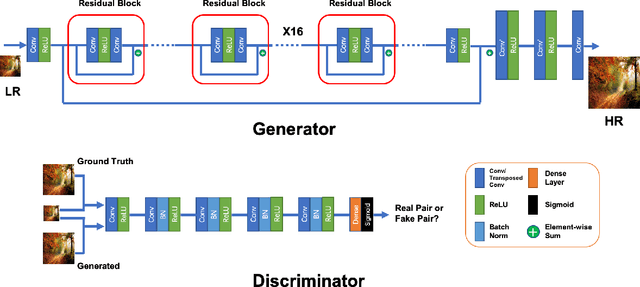
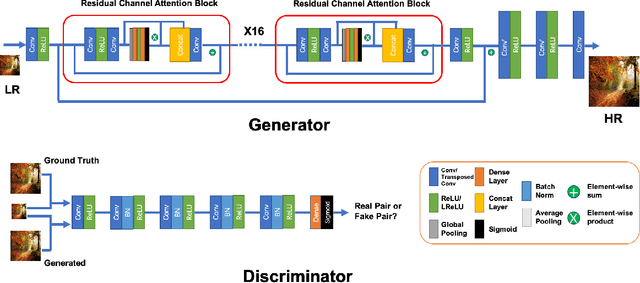
Image super-resolution is one of the important computer vision techniques aiming to reconstruct high-resolution images from corresponding low-resolution ones. Most recently, deep learning-based approaches have been demonstrated for image super-resolution. However, as the deep networks go deeper, they become more difficult to train and more difficult to restore the finer texture details, especially under real-world settings. In this paper, we propose a Residual Channel Attention-Generative Adversarial Network(RCA-GAN) to solve these problems. Specifically, a novel residual channel attention block is proposed to form RCA-GAN, which consists of a set of residual blocks with shortcut connections, and a channel attention mechanism to model the interdependence and interaction of the feature representations among different channels. Besides, a generative adversarial network (GAN) is employed to further produce realistic and highly detailed results. Benefiting from these improvements, the proposed RCA-GAN yields consistently better visual quality with more detailed and natural textures than baseline models; and achieves comparable or better performance compared with the state-of-the-art methods for real-world image super-resolution.
Gradient-Coherent Strong Regularization for Deep Neural Networks
Nov 20, 2018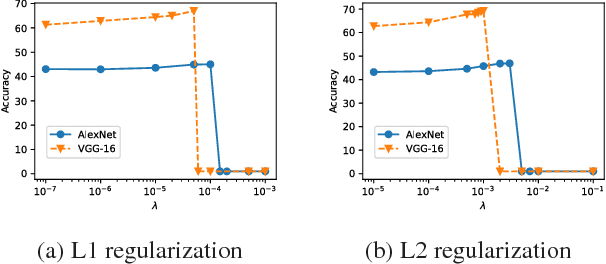
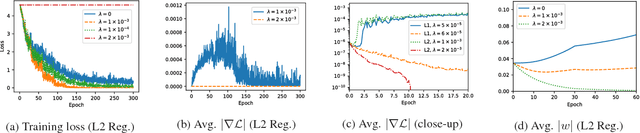

Deep neural networks are often prone to over-fitting with their numerous parameters, so regularization plays an important role in generalization. L1 and L2 regularizers are common regularization tools in machine learning with their simplicity and effectiveness. However, we observe that imposing strong L1 or L2 regularization on deep neural networks with stochastic gradient descent easily fails, which limits the generalization ability of the underlying neural networks. To understand this phenomenon, we first investigate how and why learning fails when strong regularization is imposed on deep neural networks. We then propose a novel method, gradient-coherent strong regularization, which imposes regularization only when the gradients are kept coherent in the presence of strong regularization. Experiments are performed with multiple deep architectures on three benchmark data sets for image recognition. Experimental results show that our proposed approach indeed endures strong regularization and significantly improves both accuracy and compression, which could not be achieved otherwise.
Sequenced-Replacement Sampling for Deep Learning
Oct 19, 2018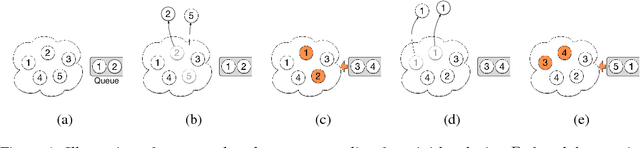

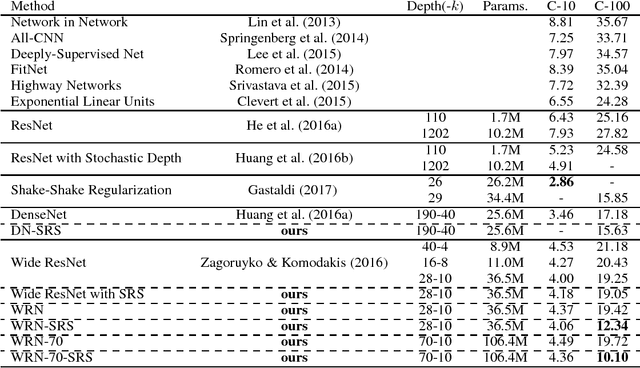
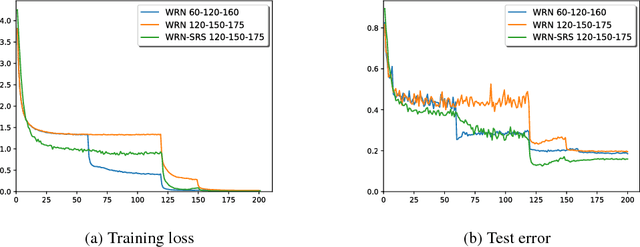
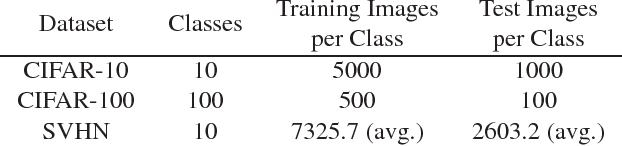
We propose sequenced-replacement sampling (SRS) for training deep neural networks. The basic idea is to assign a fixed sequence index to each sample in the dataset. Once a mini-batch is randomly drawn in each training iteration, we refill the original dataset by successively adding samples according to their sequence index. Thus we carry out replacement sampling but in a batched and sequenced way. In a sense, SRS could be viewed as a way of performing "mini-batch augmentation". It is particularly useful for a task where we have a relatively small images-per-class such as CIFAR-100. Together with a longer period of initial large learning rate, it significantly improves the classification accuracy in CIFAR-100 over the current state-of-the-art results. Our experiments indicate that training deeper networks with SRS is less prone to over-fitting. In the best case, we achieve an error rate as low as 10.10%.