 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo as Natural Augmentation: Towards Unified AI-Generated Image and Video Detection
May 21, 2026AI-generated content (AIGC) is rapidly improving, creating an urgent need for detectors that generalize across data sources, deployment pipelines, and visual modalities. A strongly generalizable detector should remain robust under distributional variations. However, we identify a consistent failure mode: SOTA AI-generated image detectors often collapse when applied to frames extracted from videos. Through systematic analysis, we show that this cross-modal gap arises from both entangled synthesis-agnostic video processing shifts, including color conversion, codec compression, resizing, and blur, and model-specific fingerprints introduced by modern video generators. Motivated by these findings, we propose VINA (Video as Natural Augmentation), a unified AIGC detection framework that jointly trains on image and video data. VINA uses video frames as physically grounded natural augmentations and further introduces a cross-modal supervised contrastive objective to align image and video representations under a shared real/fake decision boundary. Extensive experiments on 14 image, video, and in-the-wild benchmarks show that VINA delivers bidirectional gains, improves robustness and transferability, and achieves state-of-the-art performance across nearly all evaluated settings without complex augmentation or dataset-specific tuning.
Preserving Forgery Artifacts: AI-Generated Video Detection at Native Scale
Apr 06, 2026The rapid advancement of video generation models has enabled the creation of highly realistic synthetic media, raising significant societal concerns regarding the spread of misinformation. However, current detection methods suffer from critical limitations. They rely on preprocessing operations like fixed-resolution resizing and cropping. These operations not only discard subtle, high-frequency forgery traces but also cause spatial distortion and significant information loss. Furthermore, existing methods are often trained and evaluated on outdated datasets that fail to capture the sophistication of modern generative models. To address these challenges, we introduce a comprehensive dataset and a novel detection framework. First, we curate a large-scale dataset of over 140K videos from 15 state-of-the-art open-source and commercial generators, along with Magic Videos benchmark designed specifically for evaluating ultra-realistic synthetic content. In addition, we propose a novel detection framework built on the Qwen2.5-VL Vision Transformer, which operates natively at variable spatial resolutions and temporal durations. This native-scale approach effectively preserves the high-frequency artifacts and spatiotemporal inconsistencies typically lost during conventional preprocessing. Extensive experiments demonstrate that our method achieves superior performance across multiple benchmarks, underscoring the critical importance of native-scale processing and establishing a robust new baseline for AI-generated video detection.
Multimodal Dataset Distillation via Phased Teacher Models
Mar 26, 2026Multimodal dataset distillation aims to construct compact synthetic datasets that enable efficient compression and knowledge transfer from large-scale image-text data. However, existing approaches often fail to capture the complex, dynamically evolving knowledge embedded in the later training stages of teacher models. This limitation leads to degraded student performance and compromises the quality of the distilled data. To address critical challenges such as pronounced cross-stage performance gaps and unstable teacher trajectories, we propose Phased Teacher Model with Shortcut Trajectory (PTM-ST) -- a novel phased distillation framework. PTM-ST leverages stage-aware teacher modeling and a shortcut-based trajectory construction strategy to accurately fit the teacher's learning dynamics across distinct training phases. This enhances both the stability and expressiveness of the distillation process. Through theoretical analysis and comprehensive experiments, we show that PTM-ST significantly mitigates optimization oscillations and inter-phase knowledge gaps, while also reducing storage overhead. Our method consistently surpasses state-of-the-art baselines on Flickr30k and COCO, achieving up to 13.5% absolute improvement and an average gain of 9.53% on Flickr30k. Code: https://github.com/Previsior/PTM-ST.
Robust Reinforcement Learning under Diffusion Models for Data with Jumps
Nov 18, 2024
Reinforcement Learning (RL) has proven effective in solving complex decision-making tasks across various domains, but challenges remain in continuous-time settings, particularly when state dynamics are governed by stochastic differential equations (SDEs) with jump components. In this paper, we address this challenge by introducing the Mean-Square Bipower Variation Error (MSBVE) algorithm, which enhances robustness and convergence in scenarios involving significant stochastic noise and jumps. We first revisit the Mean-Square TD Error (MSTDE) algorithm, commonly used in continuous-time RL, and highlight its limitations in handling jumps in state dynamics. The proposed MSBVE algorithm minimizes the mean-square quadratic variation error, offering improved performance over MSTDE in environments characterized by SDEs with jumps. Simulations and formal proofs demonstrate that the MSBVE algorithm reliably estimates the value function in complex settings, surpassing MSTDE's performance when faced with jump processes. These findings underscore the importance of alternative error metrics to improve the resilience and effectiveness of RL algorithms in continuous-time frameworks.
Artificial Intelligence System for Detection and Screening of Cardiac Abnormalities using Electrocardiogram Images
Feb 10, 2023



The artificial intelligence (AI) system has achieved expert-level performance in electrocardiogram (ECG) signal analysis. However, in underdeveloped countries or regions where the healthcare information system is imperfect, only paper ECGs can be provided. Analysis of real-world ECG images (photos or scans of paper ECGs) remains challenging due to complex environments or interference. In this study, we present an AI system developed to detect and screen cardiac abnormalities (CAs) from real-world ECG images. The system was evaluated on a large dataset of 52,357 patients from multiple regions and populations across the world. On the detection task, the AI system obtained area under the receiver operating curve (AUC) of 0.996 (hold-out test), 0.994 (external test 1), 0.984 (external test 2), and 0.979 (external test 3), respectively. Meanwhile, the detection results of AI system showed a strong correlation with the diagnosis of cardiologists (cardiologist 1 (R=0.794, p<1e-3), cardiologist 2 (R=0.812, p<1e-3)). On the screening task, the AI system achieved AUCs of 0.894 (hold-out test) and 0.850 (external test). The screening performance of the AI system was better than that of the cardiologists (AI system (0.846) vs. cardiologist 1 (0.520) vs. cardiologist 2 (0.480)). Our study demonstrates the feasibility of an accurate, objective, easy-to-use, fast, and low-cost AI system for CA detection and screening. The system has the potential to be used by healthcare professionals, caregivers, and general users to assess CAs based on real-world ECG images.
MetaVA: Curriculum Meta-learning and Pre-fine-tuning of Deep Neural Networks for Detecting Ventricular Arrhythmias based on ECGs
Mar 01, 2022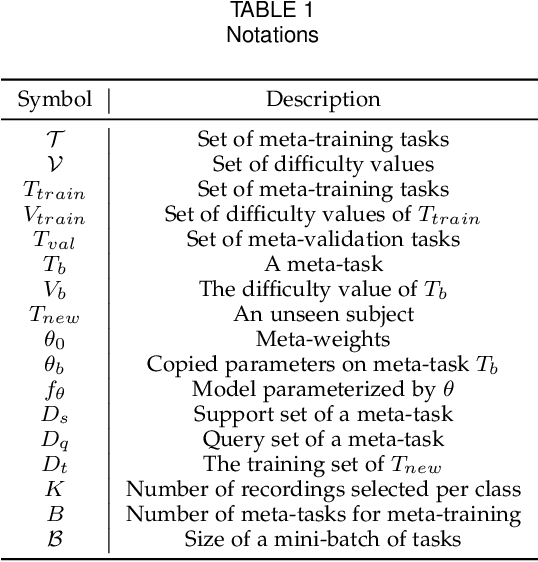
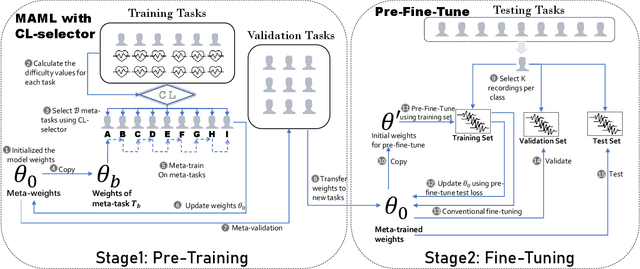

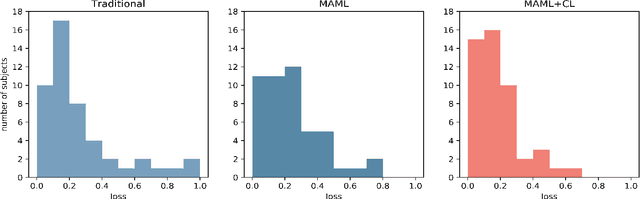
Ventricular arrhythmias (VA) are the main causes of sudden cardiac death. Developing machine learning methods for detecting VA based on electrocardiograms (ECGs) can help save people's lives. However, developing such machine learning models for ECGs is challenging because of the following: 1) group-level diversity from different subjects and 2) individual-level diversity from different moments of a single subject. In this study, we aim to solve these problems in the pre-training and fine-tuning stages. For the pre-training stage, we propose a novel model agnostic meta-learning (MAML) with curriculum learning (CL) method to solve group-level diversity. MAML is expected to better transfer the knowledge from a large dataset and use only a few recordings to quickly adapt the model to a new person. CL is supposed to further improve MAML by meta-learning from easy to difficult tasks. For the fine-tuning stage, we propose improved pre-fine-tuning to solve individual-level diversity. We conduct experiments using a combination of three publicly available ECG datasets. The results show that our method outperforms the compared methods in terms of all evaluation metrics. Ablation studies show that MAML and CL could help perform more evenly, and pre-fine-tuning could better fit the model to training data.