 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Forgery Artifacts: AI-Generated Video Detection at Native Scale
Apr 06, 2026The rapid advancement of video generation models has enabled the creation of highly realistic synthetic media, raising significant societal concerns regarding the spread of misinformation. However, current detection methods suffer from critical limitations. They rely on preprocessing operations like fixed-resolution resizing and cropping. These operations not only discard subtle, high-frequency forgery traces but also cause spatial distortion and significant information loss. Furthermore, existing methods are often trained and evaluated on outdated datasets that fail to capture the sophistication of modern generative models. To address these challenges, we introduce a comprehensive dataset and a novel detection framework. First, we curate a large-scale dataset of over 140K videos from 15 state-of-the-art open-source and commercial generators, along with Magic Videos benchmark designed specifically for evaluating ultra-realistic synthetic content. In addition, we propose a novel detection framework built on the Qwen2.5-VL Vision Transformer, which operates natively at variable spatial resolutions and temporal durations. This native-scale approach effectively preserves the high-frequency artifacts and spatiotemporal inconsistencies typically lost during conventional preprocessing. Extensive experiments demonstrate that our method achieves superior performance across multiple benchmarks, underscoring the critical importance of native-scale processing and establishing a robust new baseline for AI-generated video detection.
Consistency Beyond Contrast: Enhancing Open-Vocabulary Object Detection Robustness via Contextual Consistency Learning
Mar 27, 2026Recent advances in open-vocabulary object detection focus primarily on two aspects: scaling up datasets and leveraging contrastive learning to align language and vision modalities. However, these approaches often neglect internal consistency within a single modality, particularly when background or environmental changes occur. This lack of consistency leads to a performance drop because the model struggles to detect the same object in different scenes, which reveals a robustness gap. To address this issue, we introduce Contextual Consistency Learning (CCL), a novel framework that integrates two key strategies: Contextual Bootstrapped Data Generation (CBDG) and Contextual Consistency Loss (CCLoss). CBDG functions as a data generation mechanism, producing images that contain the same objects across diverse backgrounds. This is essential because existing datasets alone do not support our CCL framework. The CCLoss further enforces the invariance of object features despite environmental changes, thereby improving the model's robustness in different scenes. These strategies collectively form a unified framework for ensuring contextual consistency within the same modality. Our method achieves state-of-the-art performance, surpassing previous approaches by +16.3 AP on OmniLabel and +14.9 AP on D3. These results demonstrate the importance of enforcing intra-modal consistency, significantly enhancing model generalization in diverse environments. Our code is publicly available at: https://github.com/bozhao-li/CCL.
A Duet Recommendation Algorithm Based on Jointly Local and Global Representation Learning
Dec 03, 2020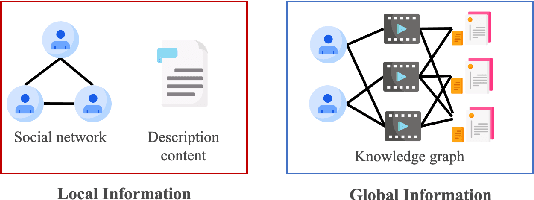
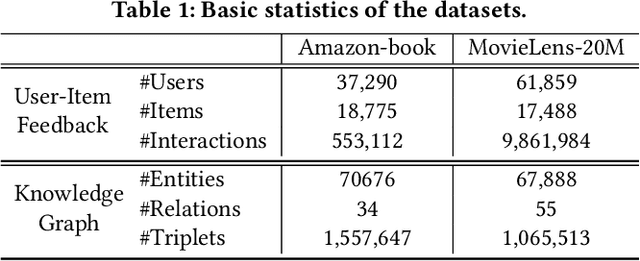
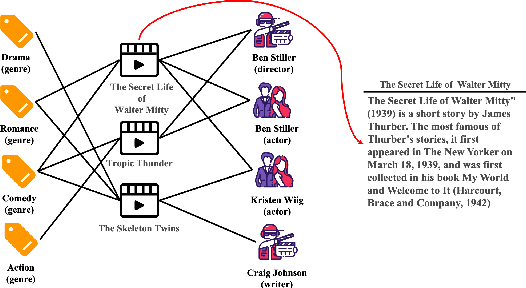
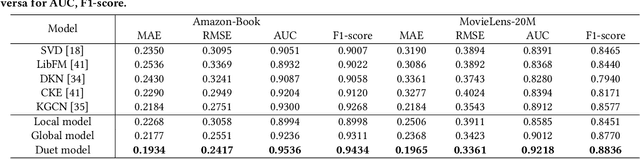
Knowledge graph (KG), as the side information, is widely utilized to learn the semantic representations of item/user for recommendation system. The traditional recommendation algorithms usually just depend on user-item interactions, but ignore the inherent web information describing the item/user, which could be formulated by the knowledge graph embedding (KGE) methods to significantly improve applications' performance. In this paper, we propose a knowledge-aware-based recommendation algorithm to capture the local and global representation learning from heterogeneous information. Specifically, the local model and global model can naturally depict the inner patterns in the content-based heterogeneous information and interactive behaviors among the users and items. Based on the method that local and global representations are learned jointly by graph convolutional networks with attention mechanism, the final recommendation probability is calculated by a fully-connected neural network. Extensive experiments are conducted on two real-world datasets to verify the proposed algorithm's validation. The evaluation results indicate that the proposed algorithm surpasses state-of-arts by $10.0\%$, $5.1\%$, $2.5\%$ and $1.8\%$ in metrics of MAE, RMSE, AUC and F1-score at least, respectively. The significant improvements reveal the capacity of our proposal to recommend user/item effectively.